Downloaded 46 times


![Outline
Overview
Renormalization Group
Physical world with various length scales
Symmetry and Scale Invariance
Restricted Boltzman Machine
Generative, Energy-based Model, Unsupervised Learning Algorithm
Richard Feynman: What I Cannot Create, I Do Not Understand.
Mapping
Unsupervised Deep Learning Implements the Kadanoff Real Space
Variational Renormalization Group
HRG
λ [{hj }] = HRBM
λ [{hj }]
Kai-Wen Zhao, kv (NTU-PHYS) Review December 1, 2016 2 / 18](https://image.slidesharecdn.com/exact-161201033302/85/Paper-Review-An-exact-mapping-between-the-Variational-Renormalization-Group-and-Deep-Learning-2-320.jpg)
![Overview of Variational RG
Statistical Physics
An ensemble of N spins {vi }, take value ±1, i is position index in some
lattice. Boltzman distribution and partition function
P({vi }) =
e−H({vi })
Z
, where Z = Trvi e−H({vi })
=
v1,v2,...=±1
e−H({vi })
Typically, Hamiltonian depends on a set of couplings {Ks}
H[{vi }] = −
i
Ki vi −
ij
Kij vi vj −
ijk
Kijkvi vj vk + ...
Free energy of spin system
F = − log Z = − log(Trvi e−H({vi })
)
Kai-Wen Zhao, kv (NTU-PHYS) Review December 1, 2016 3 / 18](https://image.slidesharecdn.com/exact-161201033302/85/Paper-Review-An-exact-mapping-between-the-Variational-Renormalization-Group-and-Deep-Learning-3-320.jpg)
![Overview of Variational RG
Overview of Variational Renormalization Group
Idea behind RG: To finde a new coarsed-grained description of spin
system, where one has integrated out short distance fluctuations.
N Physical spins: {vi }, couplings {K}
M Coarse-grained spins: {hj }, couplings { ˜K}, where M < N
Renormalization transformation is often represented as a mapping
{K} → { ˜K}
Coarse-grained Hamiltonian
HRG
[{hj }] = −
i
˜Ki hi −
ij
˜Kij hi hj −
ijk
˜Kijkhi hj hk + ...
Now, we do not distinguish vi and {vi } if no ambiguity
Kai-Wen Zhao, kv (NTU-PHYS) Review December 1, 2016 4 / 18](https://image.slidesharecdn.com/exact-161201033302/85/Paper-Review-An-exact-mapping-between-the-Variational-Renormalization-Group-and-Deep-Learning-4-320.jpg)




![Exact Mapping VRG to DL
Mapping Variational RG to RBM
In RG scheme, the couplings between visible and hidden spins are encodes
by the operators T. Analogous role, in RBM, is played by joint energy
function.
T(vi , hj ) = −E(vi , hj ) + H(vi )
To derive equivalent statement from coarse-grained Hamiltonian
e−HRG
λ (hj )
Z
=
Trvi eTλ(vi ,hj )−H(vi )
Z
= Trvi
e−E(vi ,hj )
Z
= pλ(hj )
=
e−HRBM
λ (hj )
Z
Subsituting the right-hand side yields
HRG
λ [{hj }] = HRBM
λ [{hj }] (1)
Kai-Wen Zhao, kv (NTU-PHYS) Review December 1, 2016 9 / 18](https://image.slidesharecdn.com/exact-161201033302/85/Paper-Review-An-exact-mapping-between-the-Variational-Renormalization-Group-and-Deep-Learning-9-320.jpg)


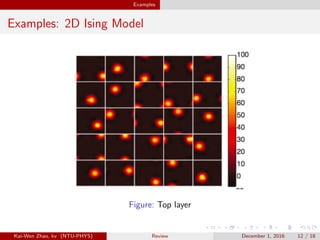






The document establishes a one-to-one mapping between variational renormalization group (VRG) methods in statistical physics and deep learning techniques, particularly focusing on Restricted Boltzmann Machines (RBMs). It explains the variational RG approach, emphasizing its ability to derive effective descriptions of physical systems while highlighting how these concepts can be applied to unsupervised deep learning frameworks. The findings suggest that learning processes in deep learning resemble RG-like schemes for feature extraction from data.



![[DL輪読会]GANとエネルギーベースモデル](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar20200828-210519065921-thumbnail.jpg?width=640&height=640&fit=bounds)























![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)






















































