Download as PDF, PPTX






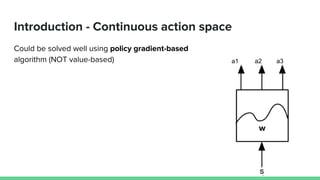

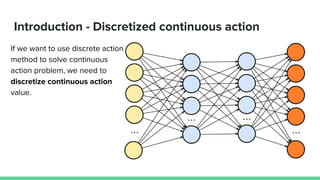
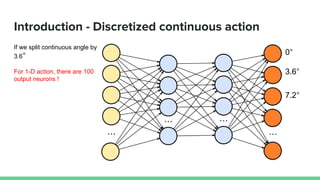
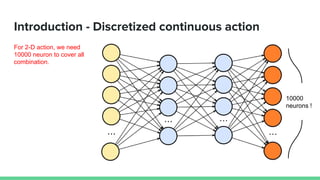

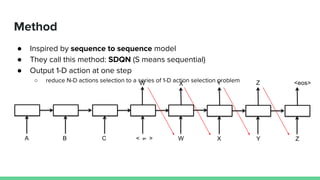
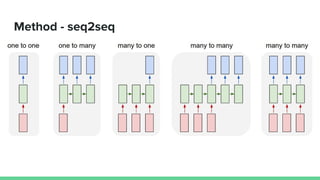
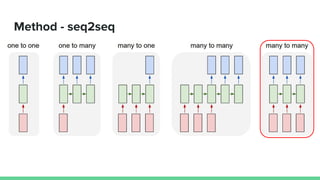
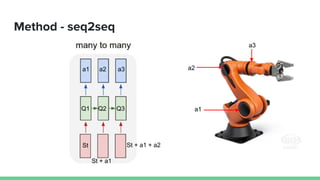

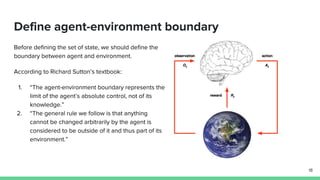
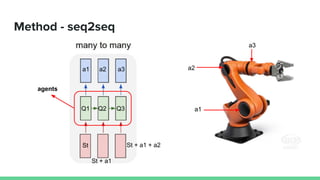
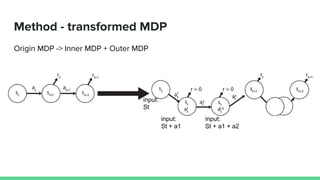
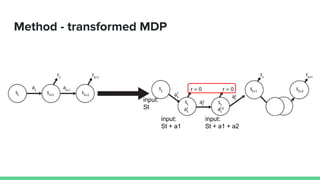
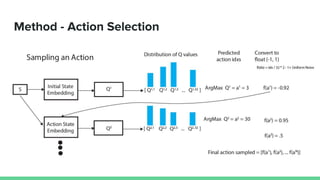
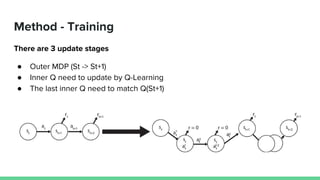
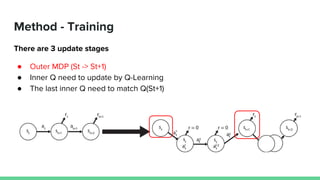
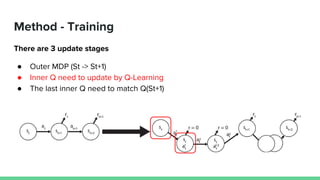
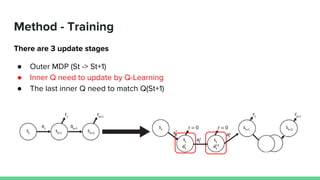
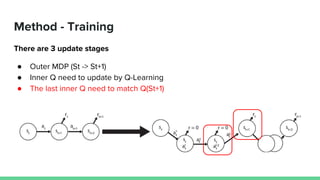
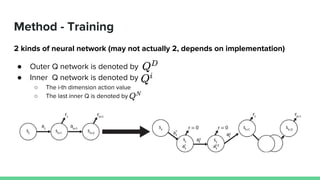
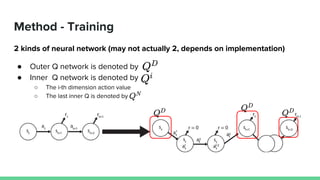
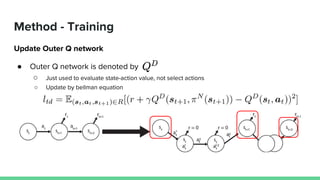
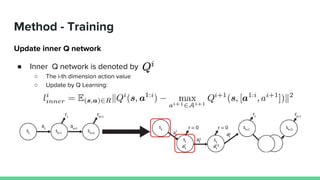
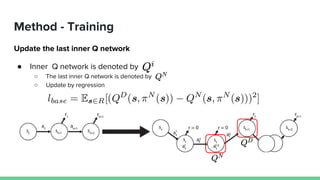

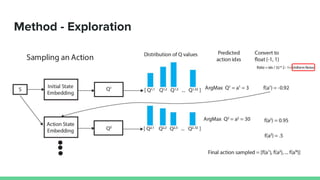


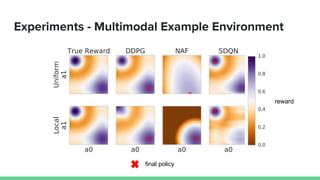
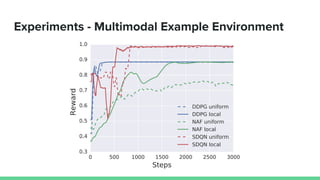



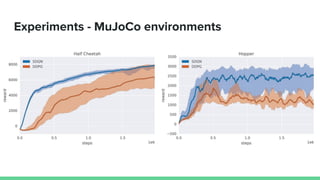




This paper proposes a method called SDQN (Sequential Deep Q-Network) to solve continuous action problems using a value-based reinforcement learning approach. SDQN discretizes continuous actions into sequential discrete steps. It transforms the original MDP into an "inner MDP" between consecutive discrete steps and an "outer MDP" between states. SDQN uses two Q-networks - an inner Q-network to estimate state-action values for each discrete step, and an outer Q-network to estimate values between states. It updates the networks using Q-learning for the inner networks and regression to match the last inner Q to the outer Q. The method is tested on a multimodal environment and several MuJoCo tasks, outperform







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

