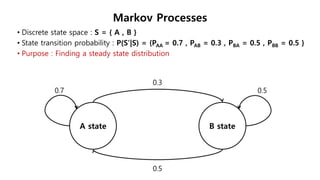
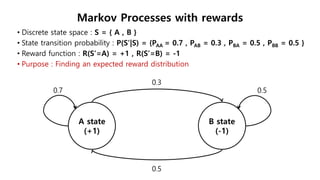
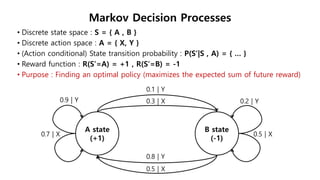
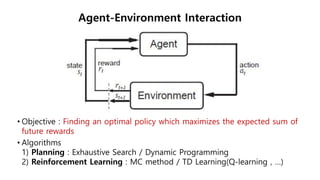
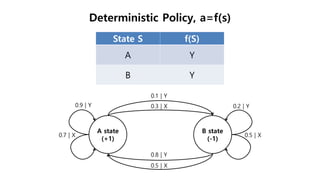
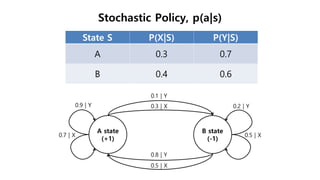
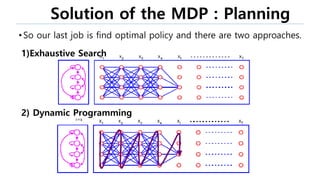
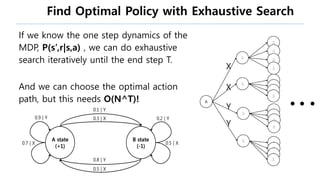
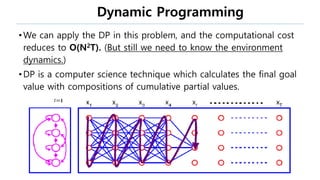
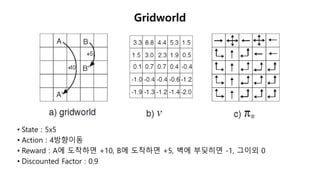
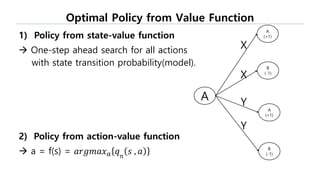
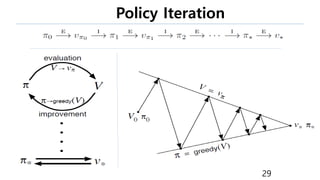
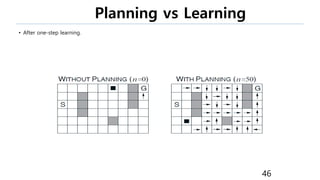
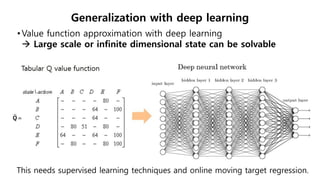
This document provides an introduction to reinforcement learning. It defines reinforcement learning as finding a policy that maximizes the sum of rewards by interacting with an environment. It discusses key concepts like Markov decision processes, value functions, temporal difference learning, Q-learning, and deep reinforcement learning. The document also provides examples of applications in games, robotics, economics and comparisons of model-based planning versus model-free reinforcement learning approaches.



























![References
[1] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An
introduction. MIT press, 1998.
50](https://image.slidesharecdn.com/reinforcementlearning-170329091514/85/Reinforcement-learning-50-320.jpg)




































































