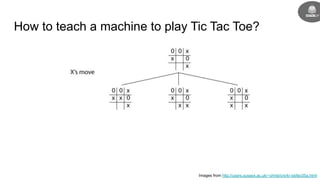
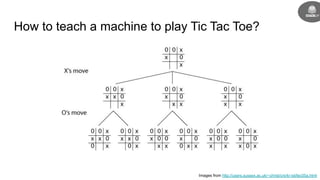
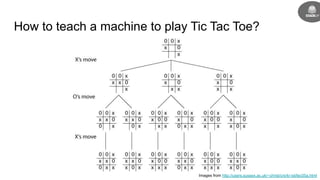
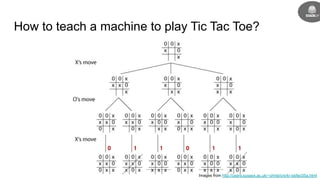
This document provides an introduction to reinforcement learning concepts including:
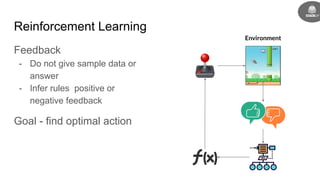
- Reinforcement learning uses feedback to infer optimal actions without sample data or answers being provided directly.
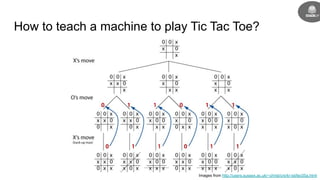
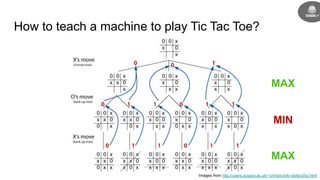
- It was inspired by Arthur Samuel programming the first machine to learn checkers in 1959 using a minimax algorithm.
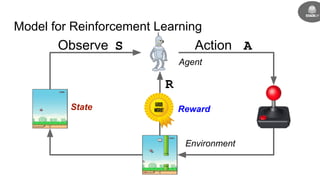
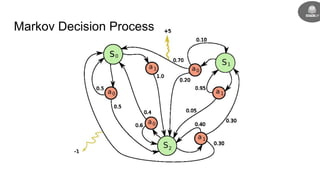
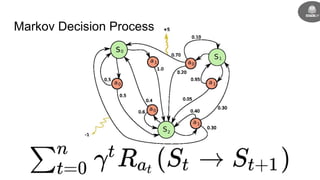
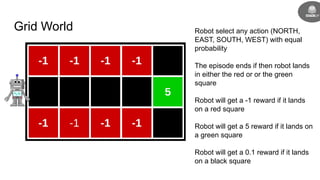
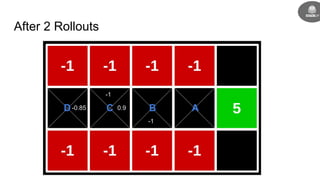
- Reinforcement learning problems can be modeled as Markov decision processes where an agent takes actions in an environment and receives rewards.
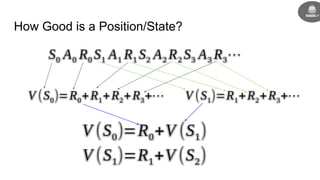
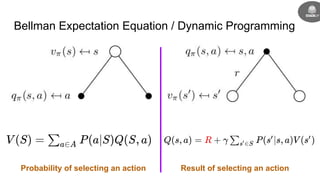
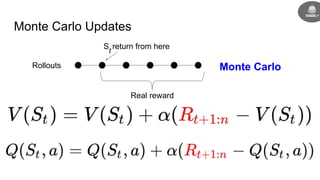
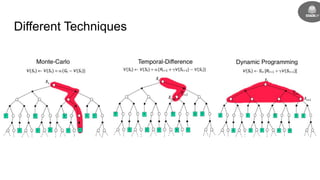
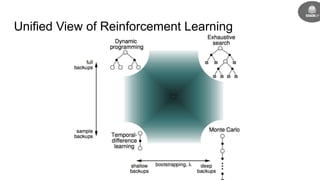
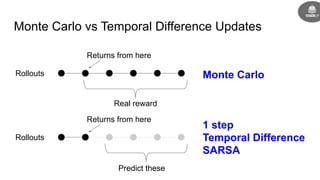
- The goal is to learn a policy that maximizes long term rewards by estimating state and action values using techniques like Monte Carlo methods, temporal difference learning, and deep reinforcement learning.