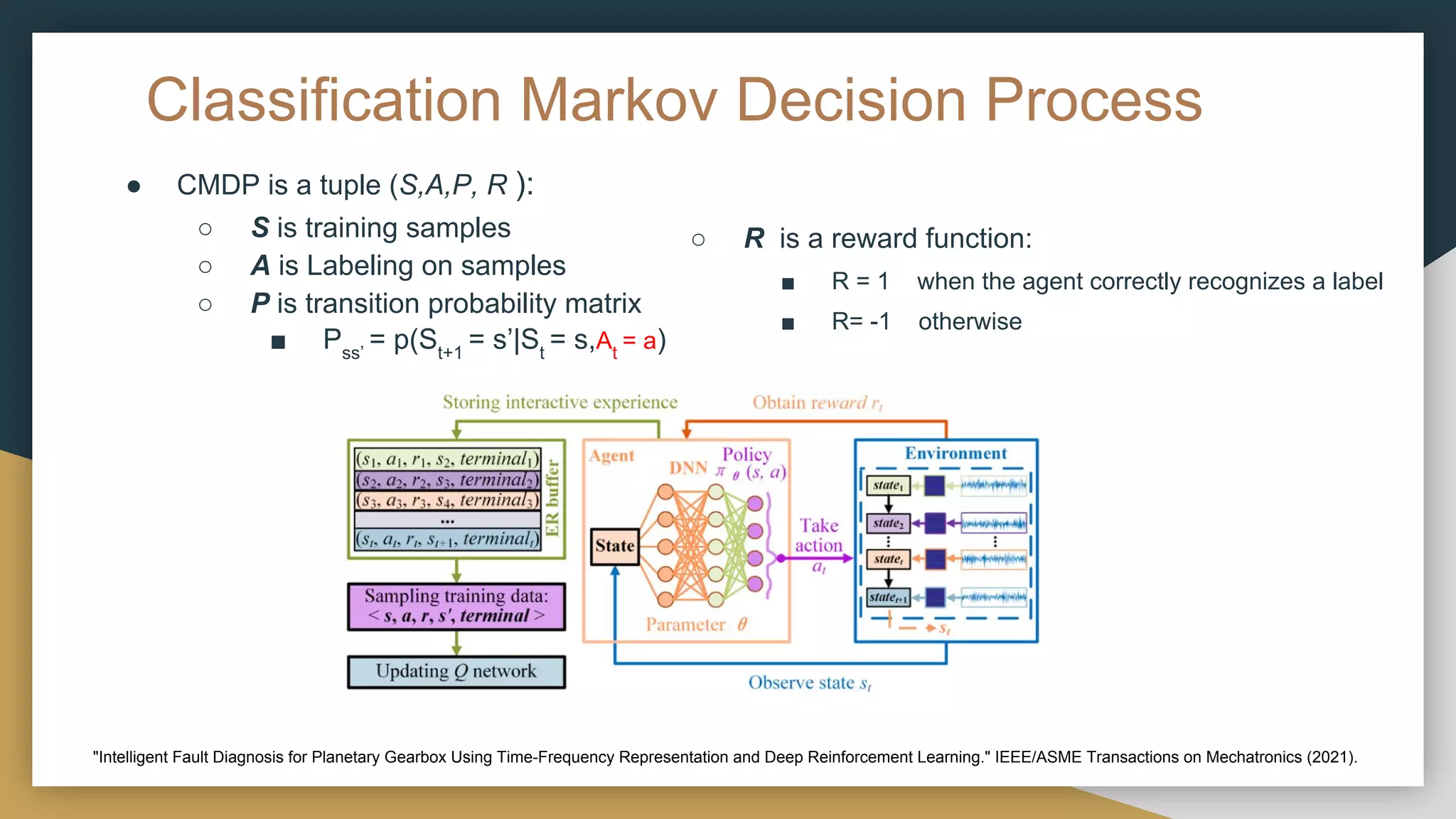
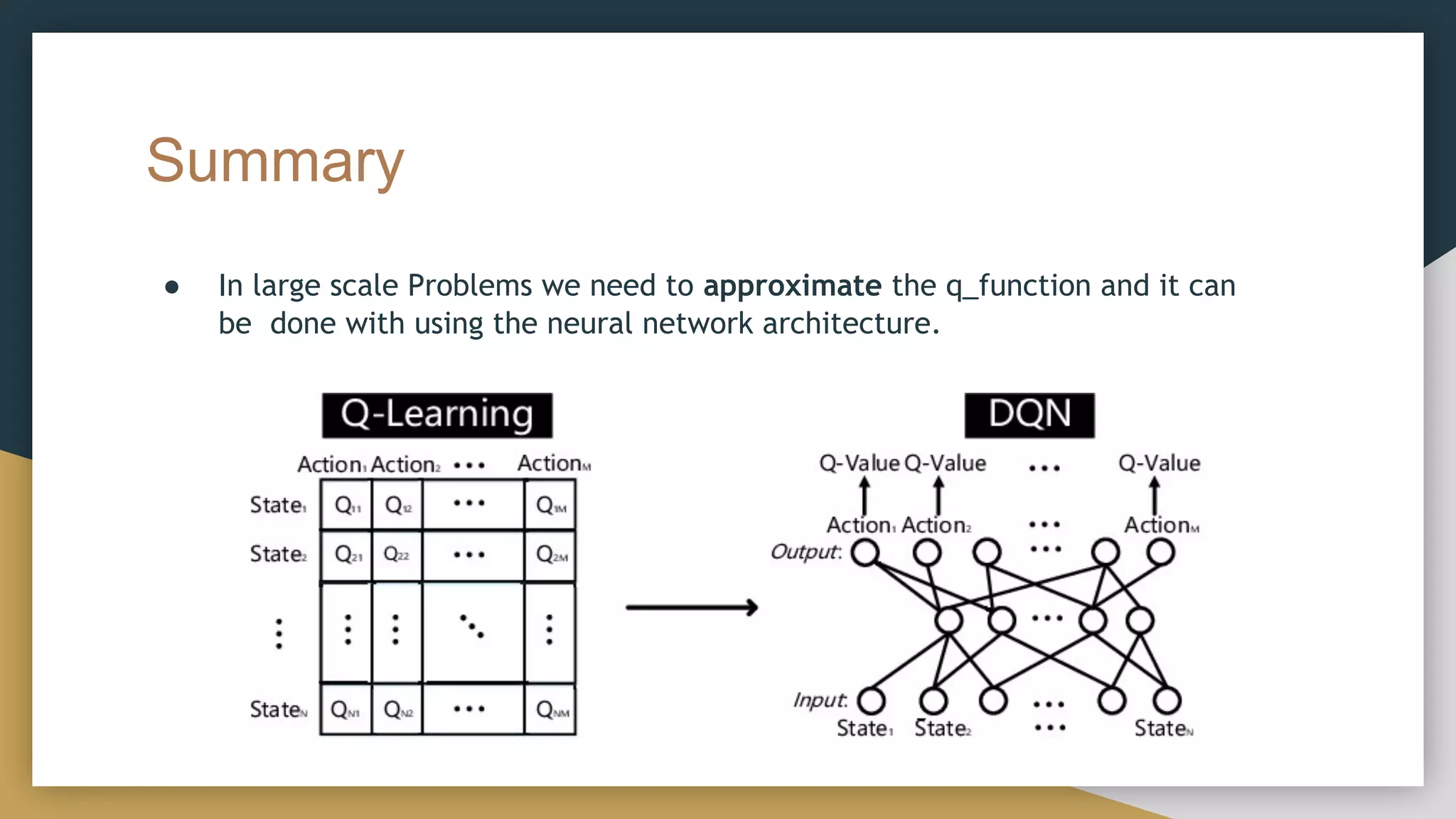
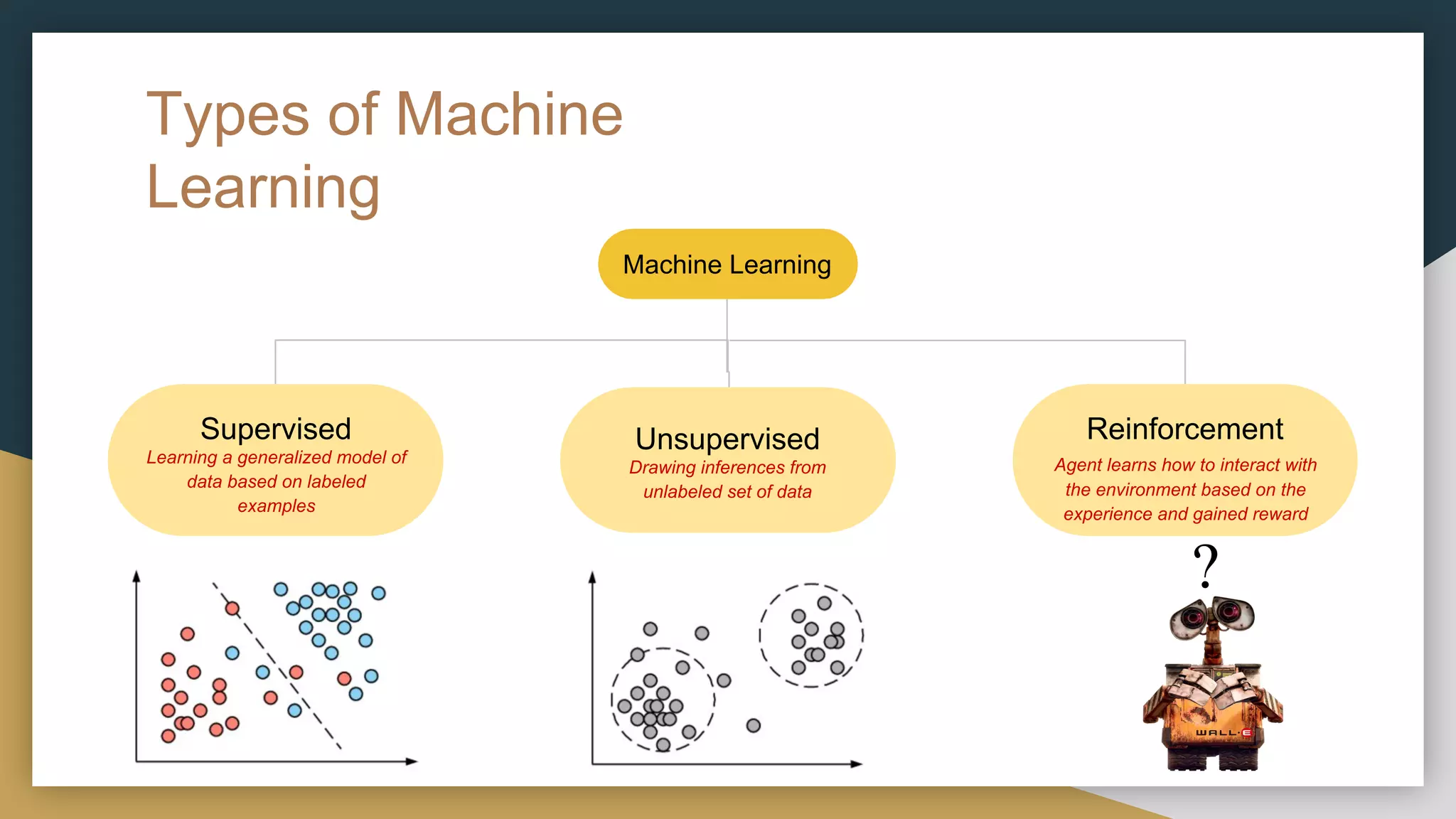
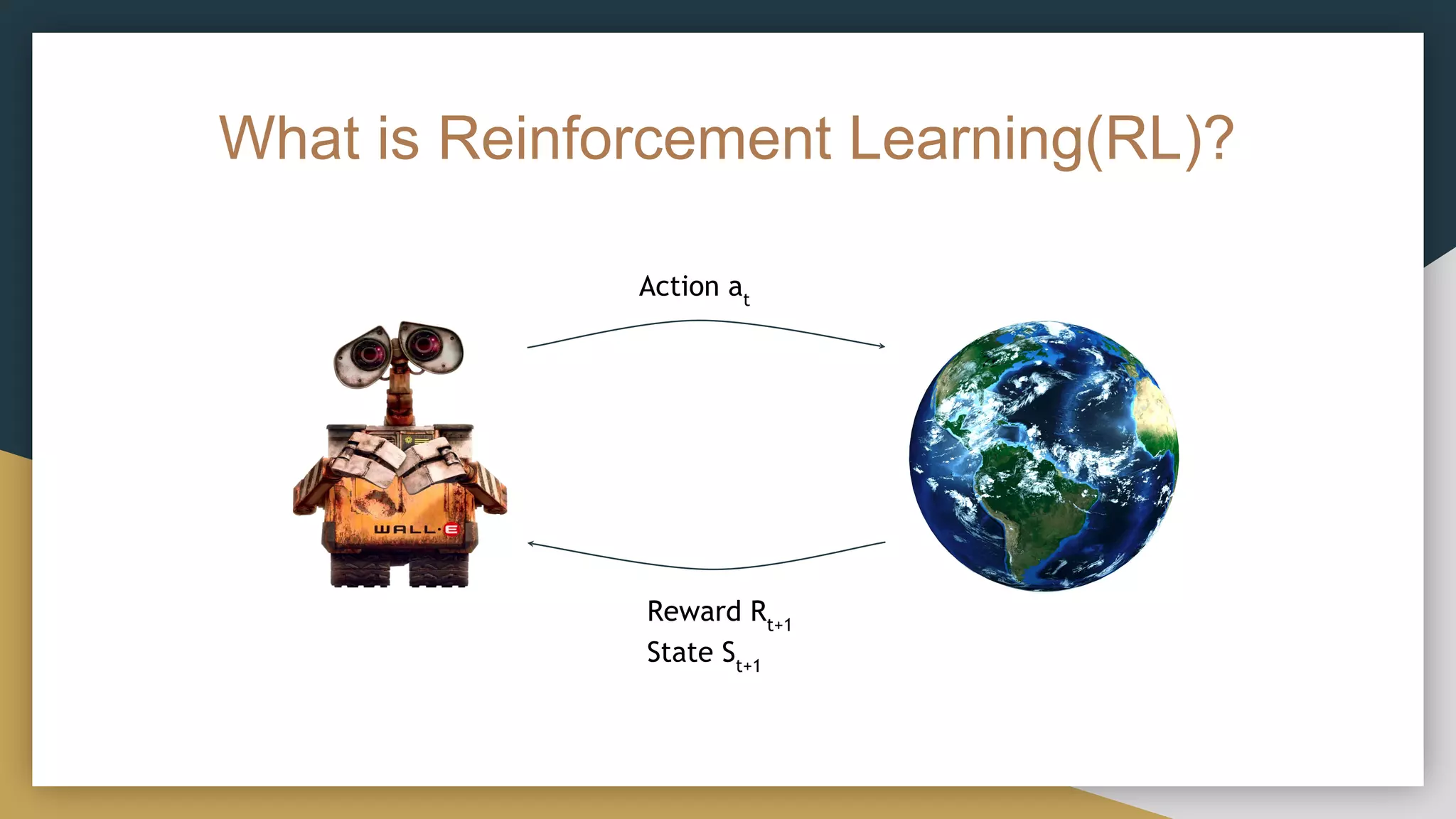
This document provides a comprehensive introduction to deep reinforcement learning (RL) and its foundational concepts, including types of machine learning, Markov processes, and different RL algorithms like Q-learning and policy iteration. It emphasizes the significance of maximizing cumulative rewards, explores the challenges posed by large state and action spaces, and discusses how neural networks can be used to approximate Q-functions in complex environments. The document also includes examples and strategies for problem-solving in RL contexts, such as exploration vs. exploitation in multi-armed bandit scenarios.





![Markov Reward Process(MRP)
● A Markov Reward Process or an MRP is a Markov
process with value judgment, saying how much reward
accumulated through some particular sequence that we
sampled.
● MRP is a tuple (S, P, R, 𝛄):
○ S is finite set of states
○ P is transition probability matrix
■ Pss’
= p(St+1
= s’|St
= s)
○ R is a reward function:
■ Rs,a
= E [Rt+1
| St
= s]
■ It is immediate reward
○ 𝛄 is a discount factor, 𝛄 ∈ [0, 1]
0.4
S0
S1
S3 S2
0.6
0.5 0.5
0.3 0.7
R = -1 R = +2
R = -1
R = +5](https://image.slidesharecdn.com/deeprl-221106111820-d5142adc/75/Deep-RL-pdf-8-2048.jpg)



![Markov Decision Process(MDP)
● MDP can be represented as follows:
𝐬𝟎 → → 𝐬𝟏 → → 𝐬𝟐 → → ⋯
● MDP is a tuple (S, A, P, R, 𝛄):
○ S is finite set of states
○ A is finite set of actions
○ P is transition probability matrix
■ Pss’
= p(St+1
= s’|St
= s,At
= a)
○ R is a reward function:
s,a t+1 t t
■ R = E [R | S = s,A = a]
■ It is immediate reward
○ 𝛄 is a discount factor, 𝛄 ∈ [0, 1]
a r a r
a r
0 1 1 2
2 3
S0
S2
S1
S3
a0
a1
a2
0.5
0.5
0.6
0.4
1.0
R = -1
R = -1
R = +2
R = +5](https://image.slidesharecdn.com/deeprl-221106111820-d5142adc/75/Deep-RL-pdf-13-2048.jpg)










![Q-Learning Example
Q =
s1
s2
s3
Q′(s,a) = 3 + 0.01 * [Rt+1
+ 0.9 max Q(St+1
,a) - Q(St
,a)] = 3 + 0.01*[4 + 0.9*10 - 3] = 3.1
Assume we are in state s1
and we choose action a2. This action will take us to state s3.
The reward of env to our action is +4.
Learning rate = 0.01
Discounted factor = 0.9
a0
a1
a2
a3
a4
a5
a0
a1
a2
a3
a4
a5
s0 12 1 3 1 10 6 s0 12 1 3
1
10 6
0 1 3 0 1 2 Q′ =
s1 0 1 3.1 0 1 2
8 5 0 1 0 2 s2 8 5 0
1
0 2
0 1 3 9 0 10 s3 0 1 3
9
0 10](https://image.slidesharecdn.com/deeprl-221106111820-d5142adc/75/Deep-RL-pdf-26-2048.jpg)



![Deep Q-learning
Algorithm
Initialize action-value function(weights of the network) with random
weights For episode = 1,M do:
Initialize the game and get starting state s
For t = 1,T do:
With probability ε select a random action at
; Otherwise select at
= maxa
Q(s, a)
Take action at
, and observe the new state s′ and reward rt+1
.
Run the network forward using s′. Store the highest Q value, which we’ll call maxQ = maxa
Q(s′,a)
if the game continues
rt+1
+ γ *maxQ
r
t+1
if the game is over
Train the model with this sample
=>
s = s′
If the game is over break; else continue
target value =
final_target = model.predict(state)
final_target[action] = target value
model.fit(state, final_target)](https://image.slidesharecdn.com/deeprl-221106111820-d5142adc/75/Deep-RL-pdf-32-2048.jpg)