Download as PDF, PPTX





















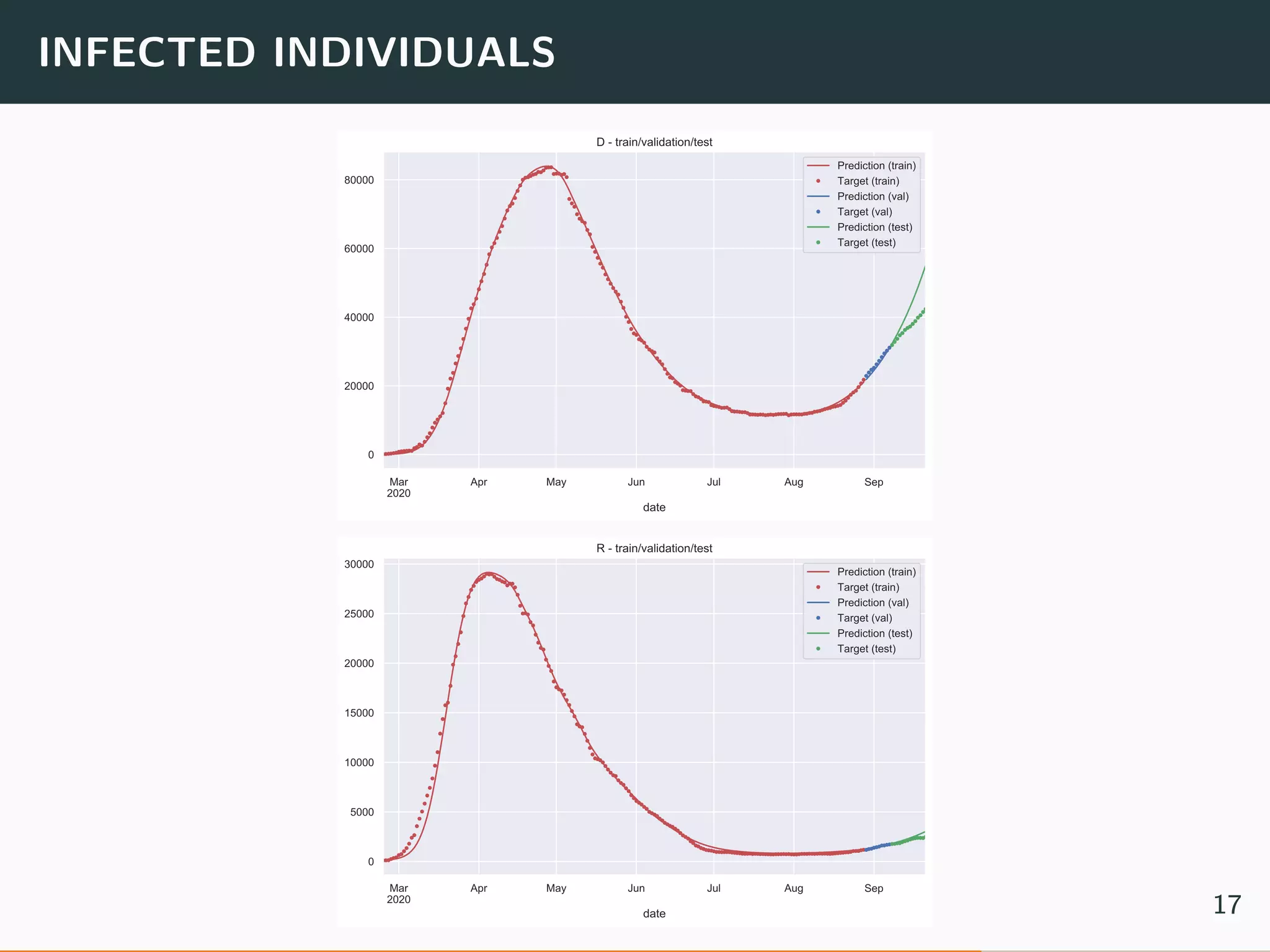
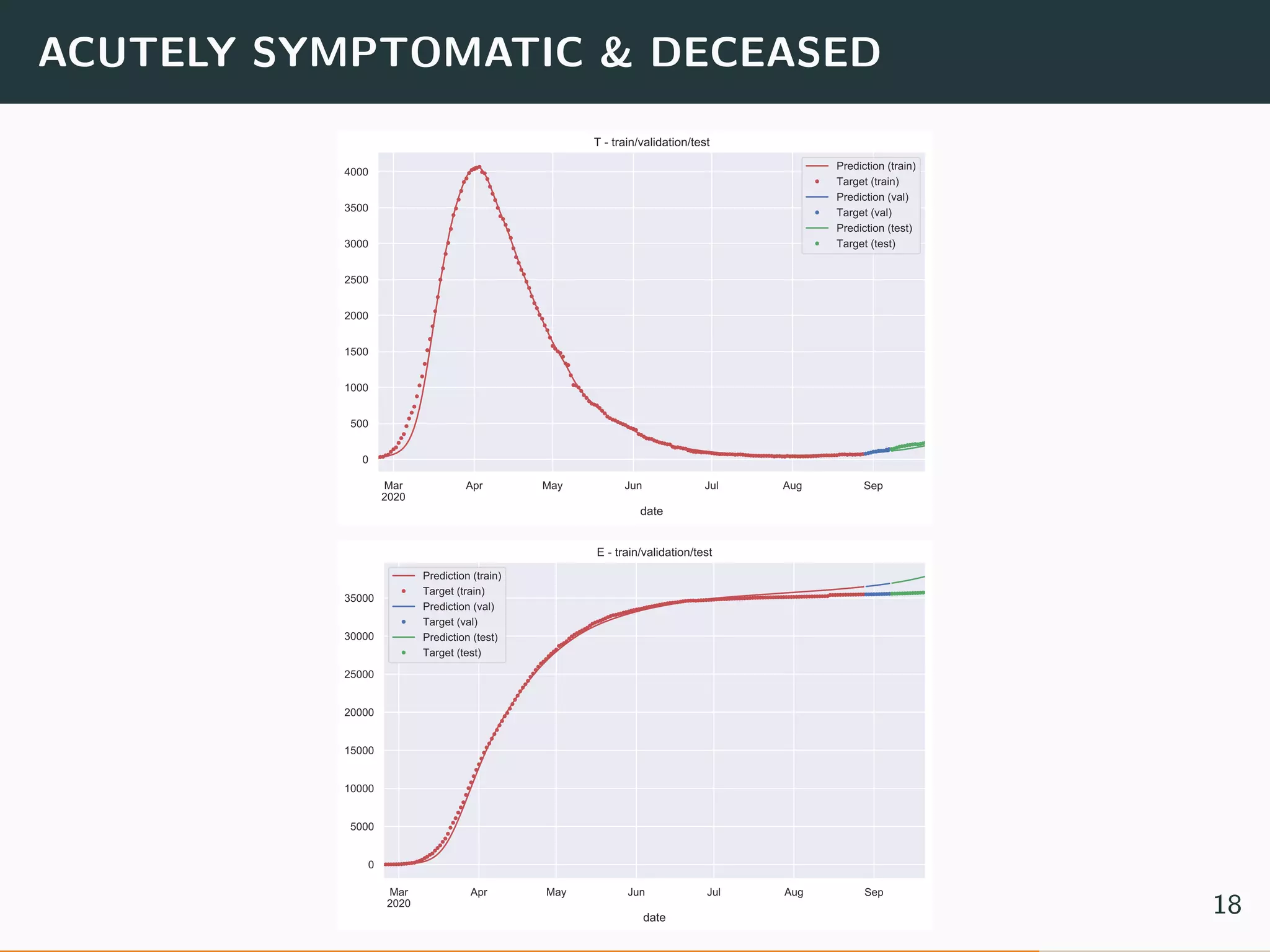
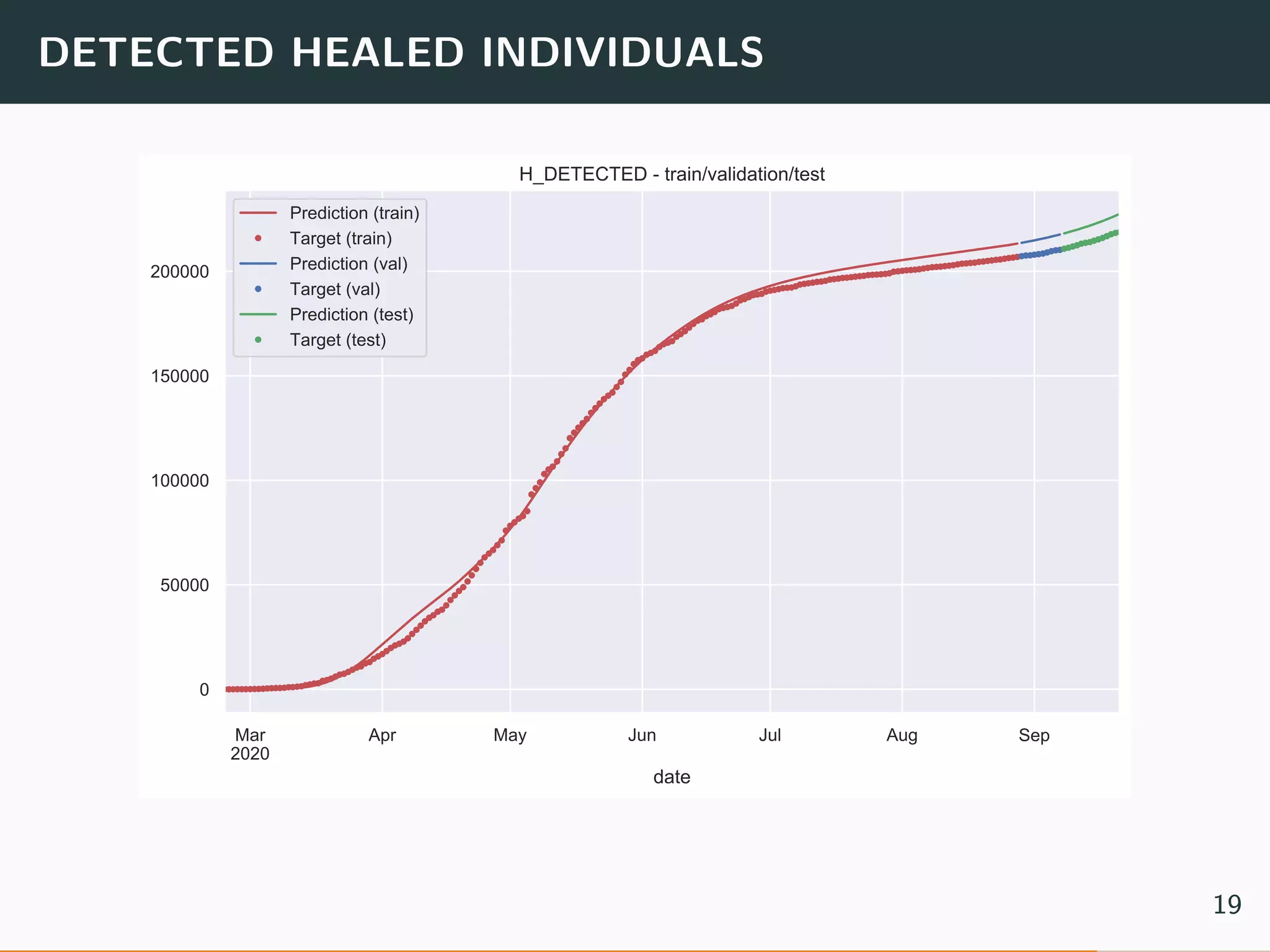
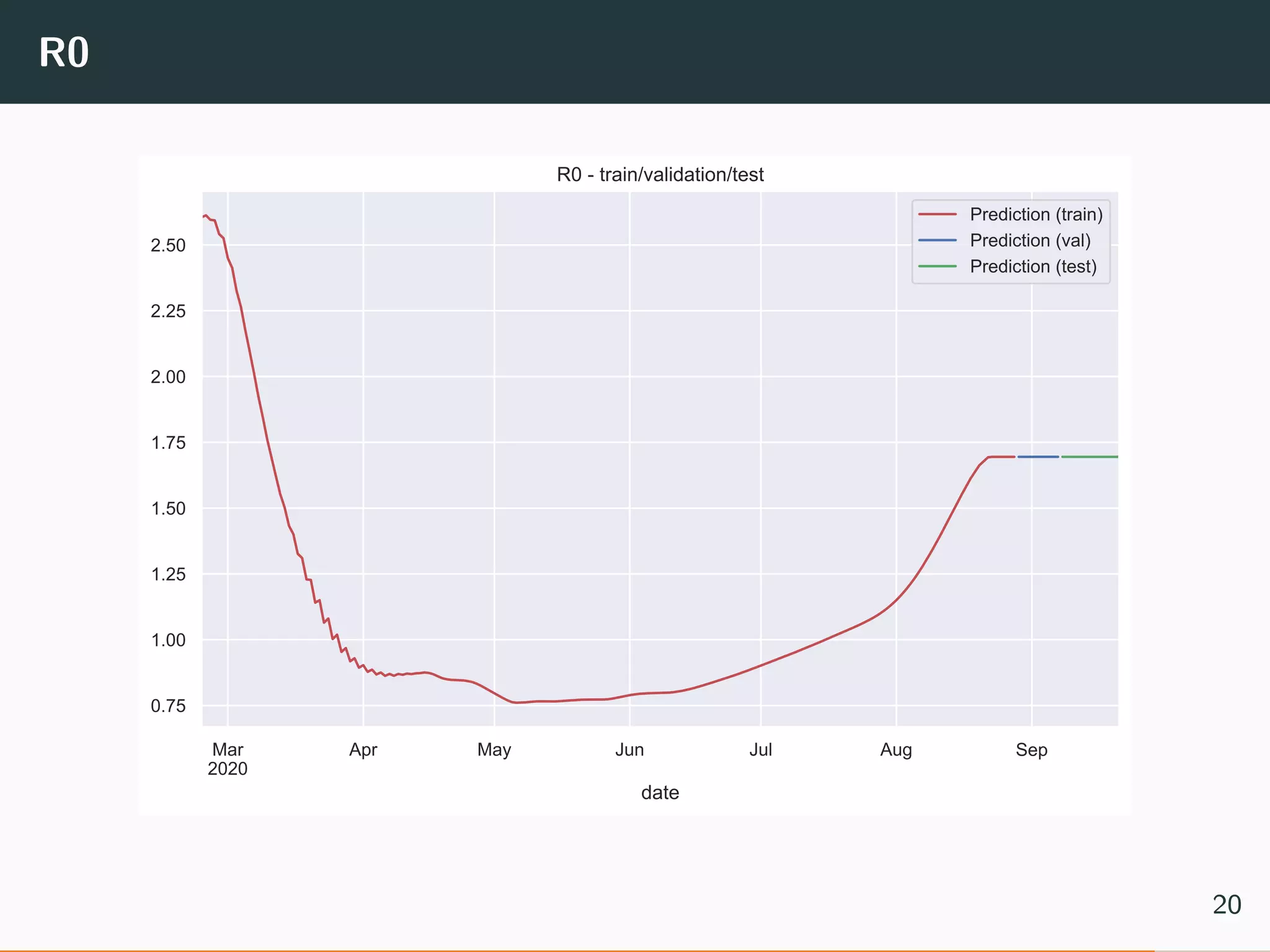
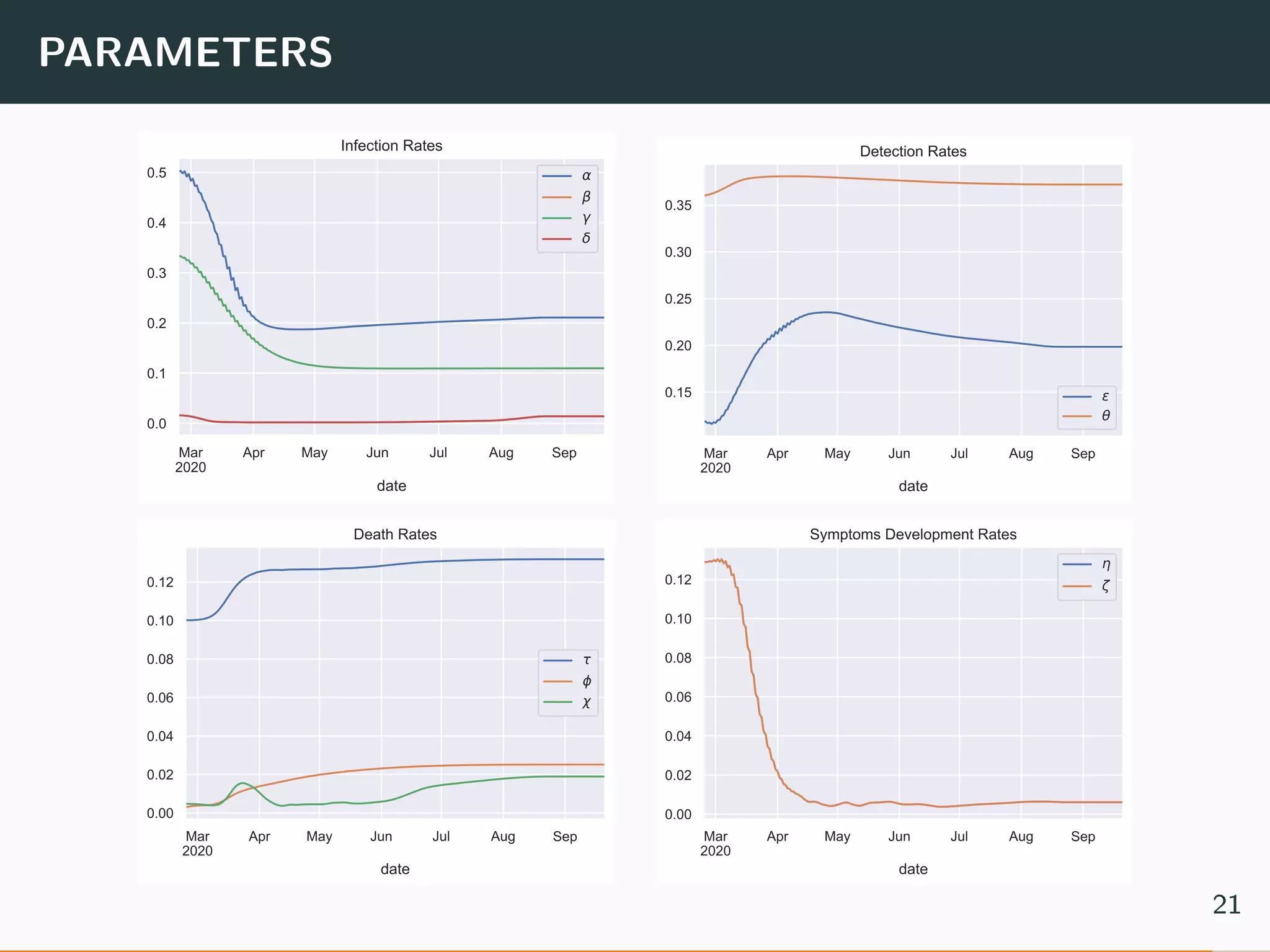









The document discusses the application of machine learning to epidemiological models, particularly in the context of COVID-19. It details the limitations of traditional deterministic models, favoring a more dynamic SIDARTHE model that accommodates time-varying parameters to capture the effects of public health interventions. The document also outlines methodologies for training and validating these models using extensive datasets to better predict the disease spread and evaluate the effectiveness of interventions.


















































![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Sponsored] C3.ai description](https://cdn.slidesharecdn.com/ss_thumbnails/c3deckmeetupnovember252019v2-191128092146-thumbnail.jpg?width=640&height=640&fit=bounds)































