Download to read offline


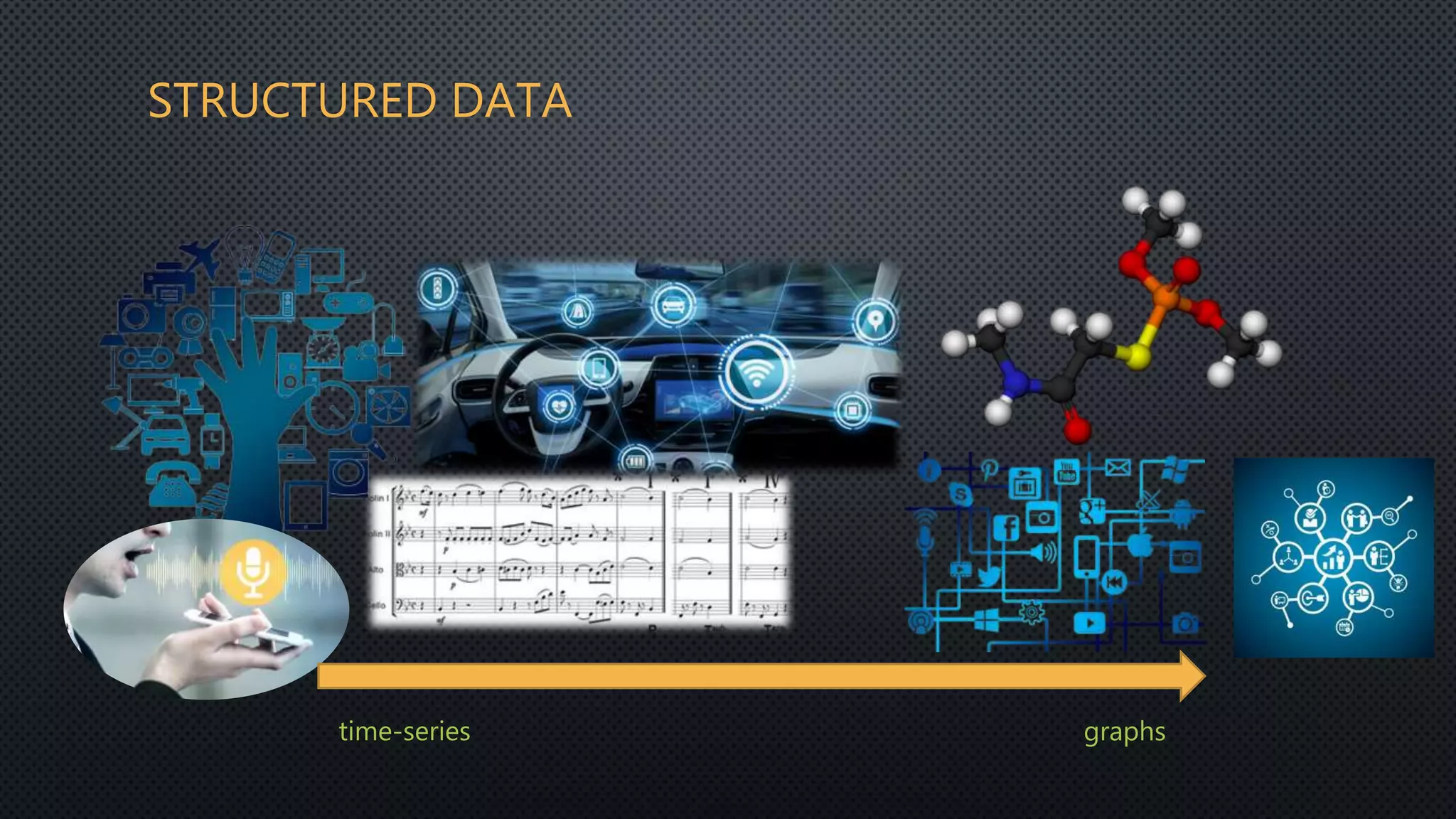
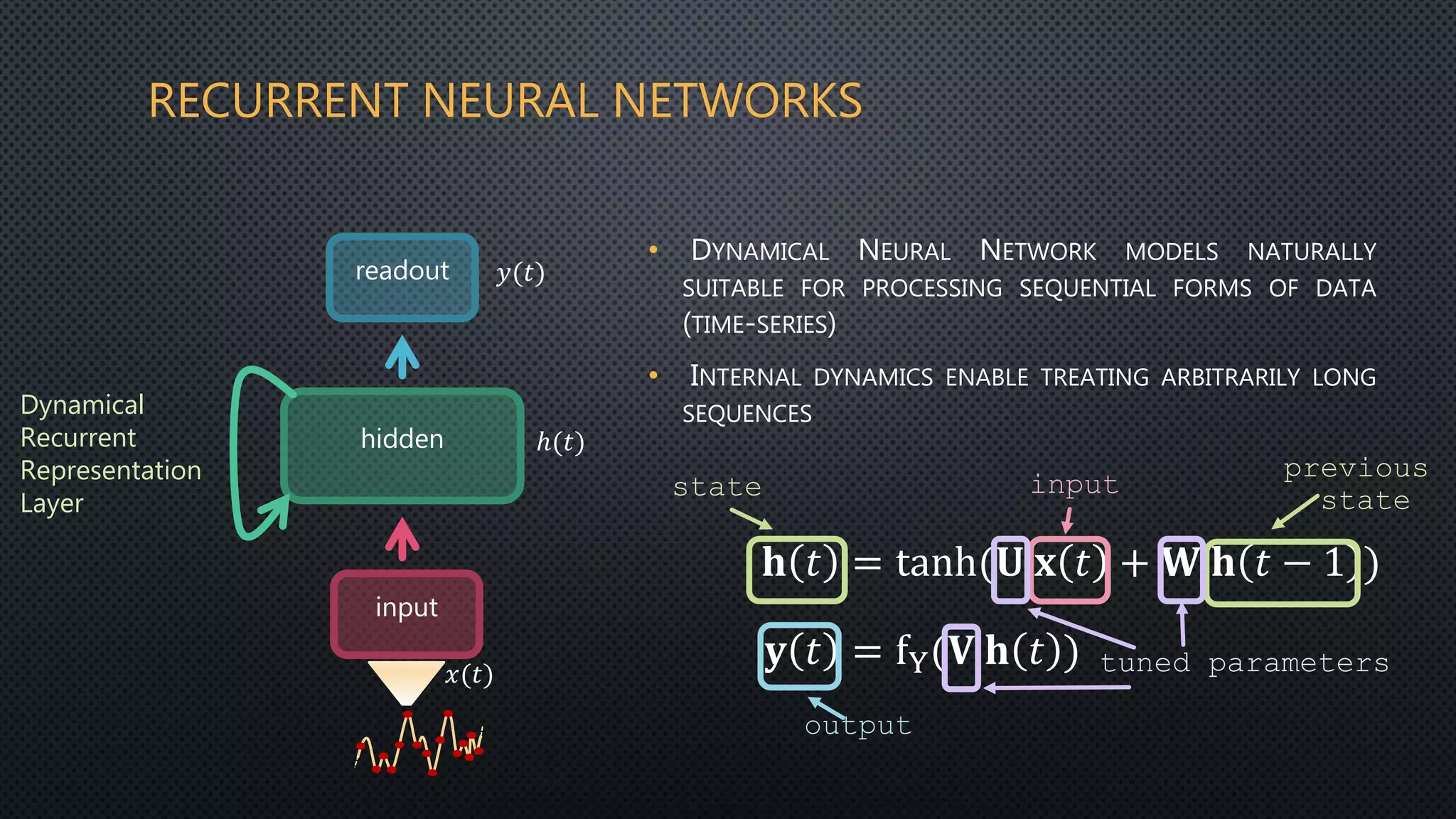
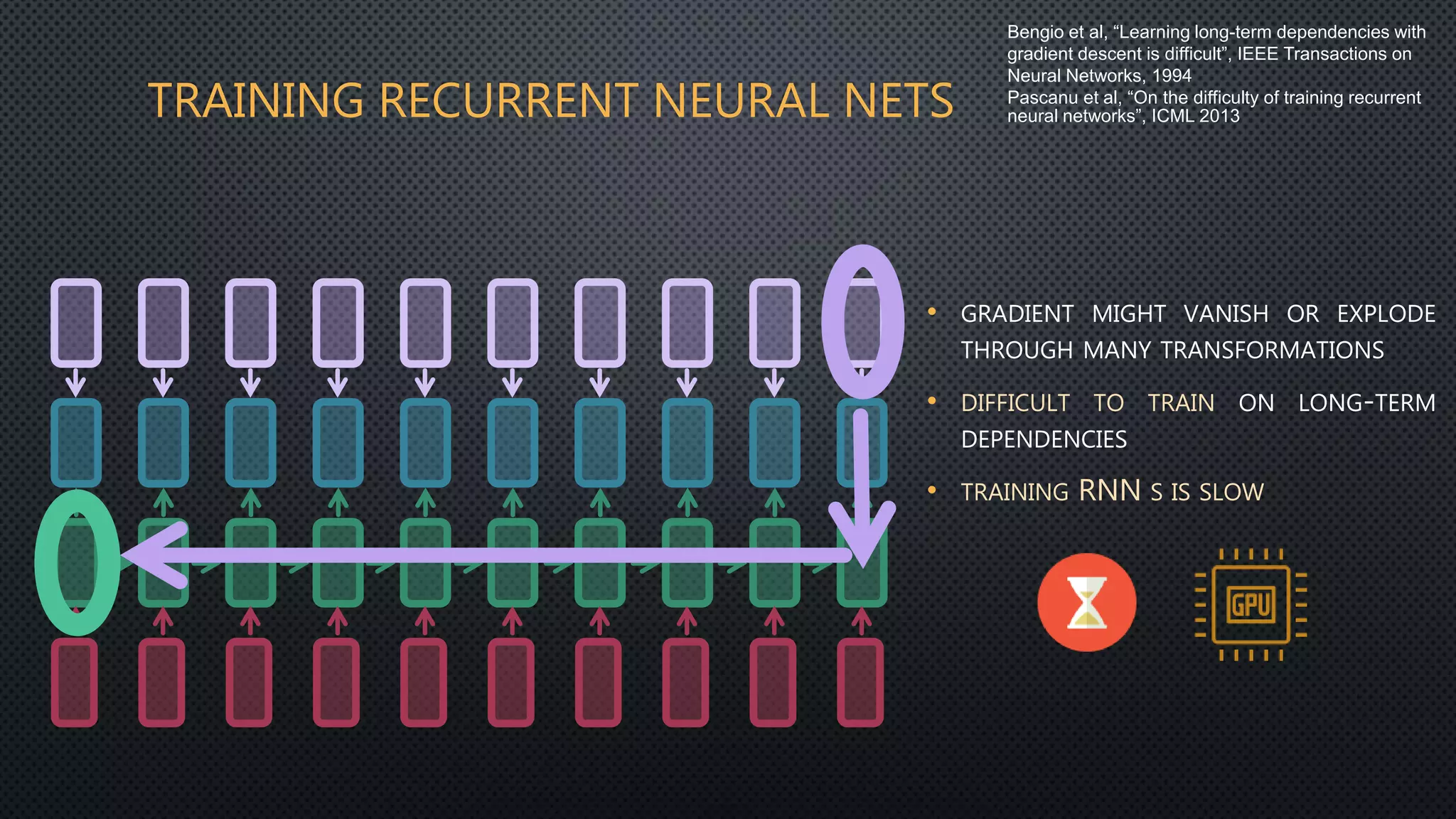
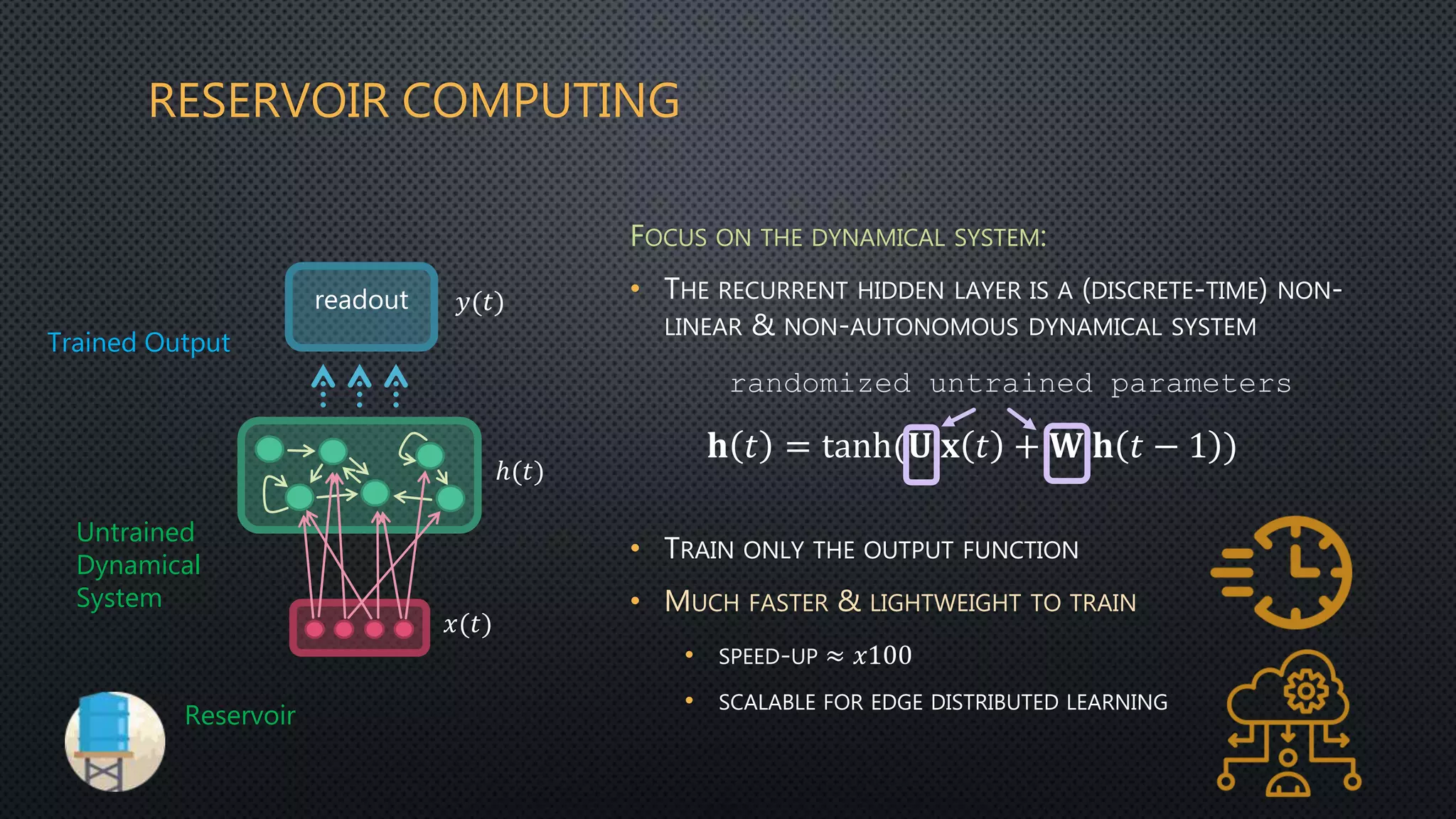


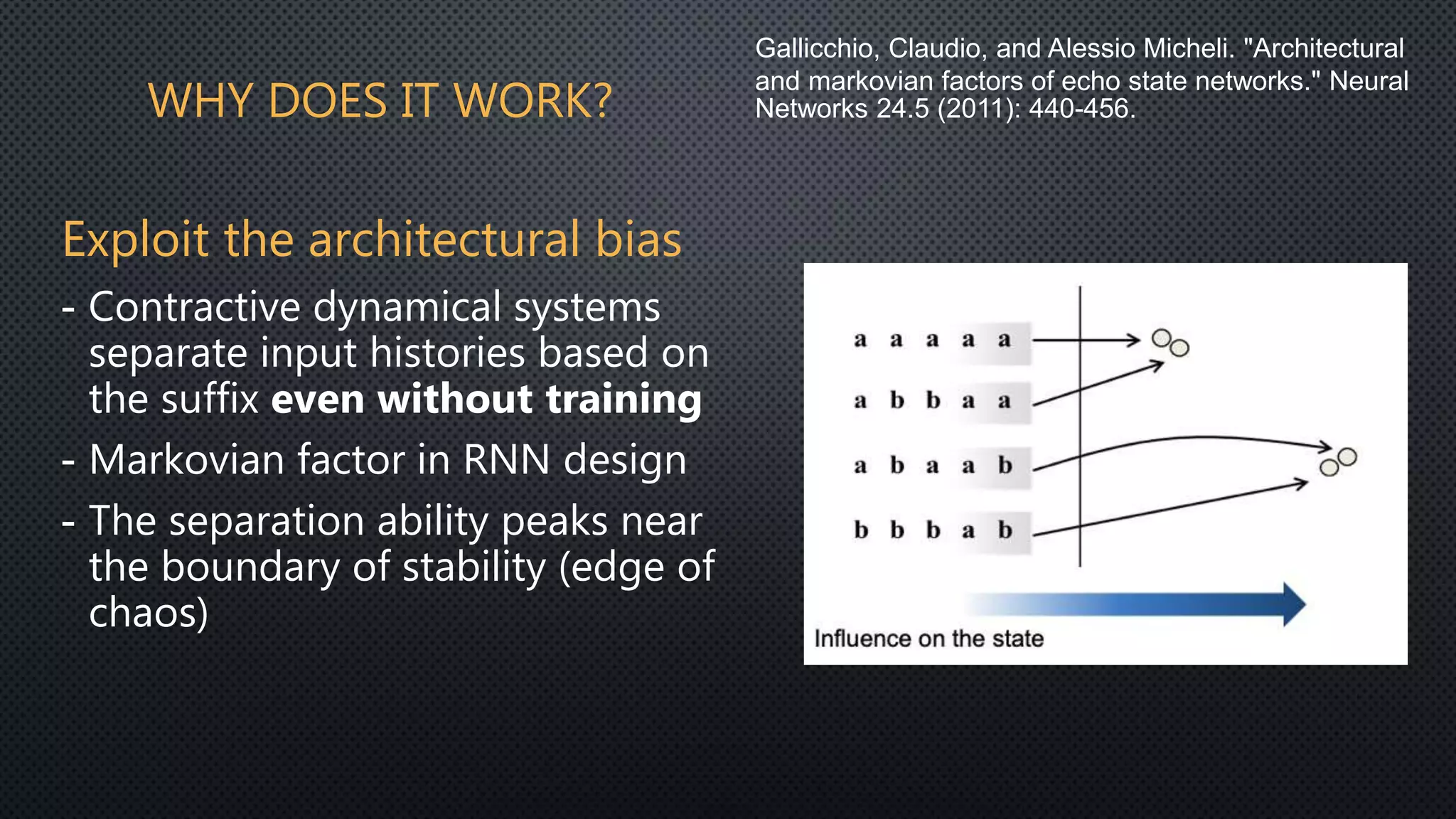



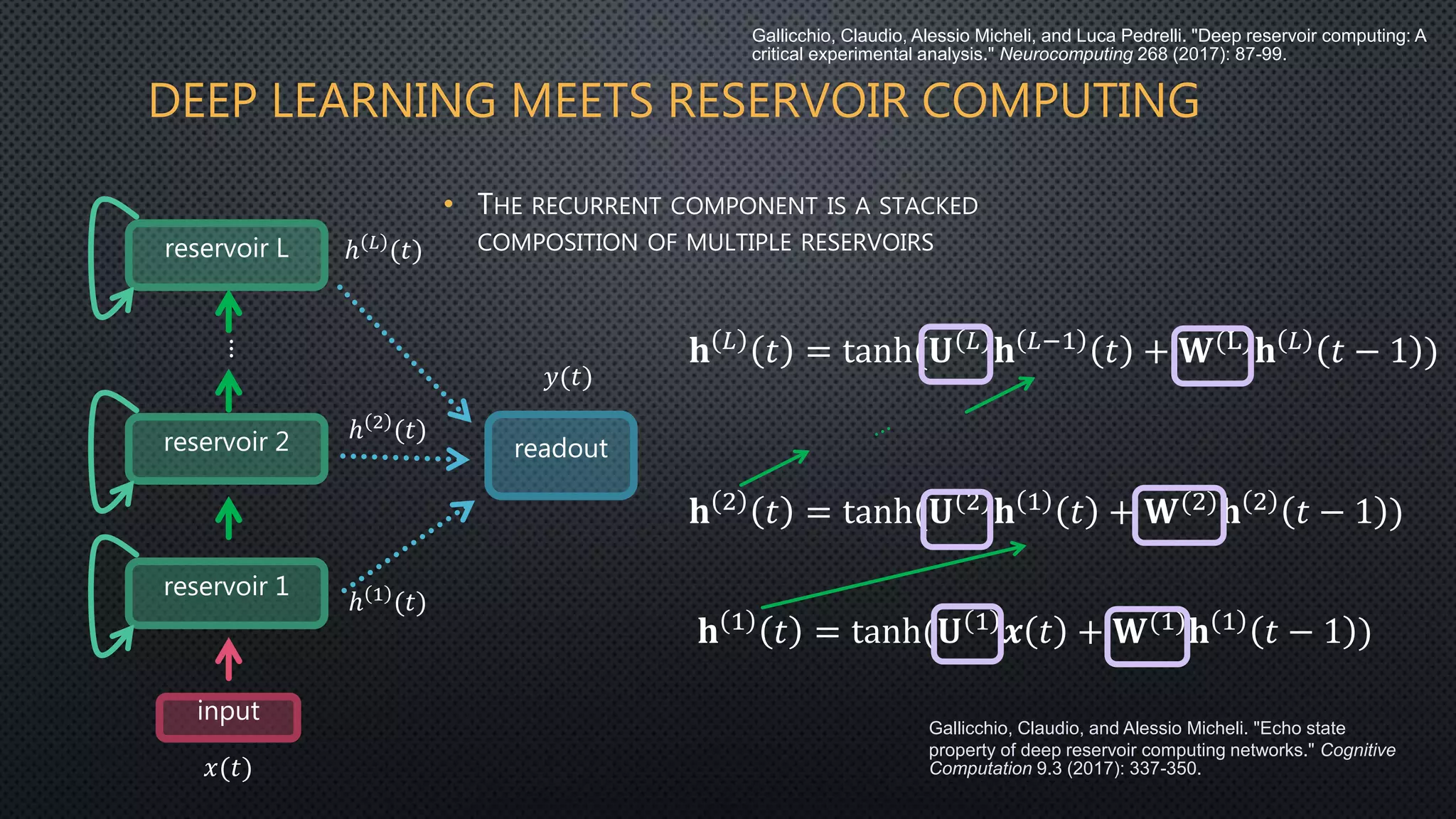

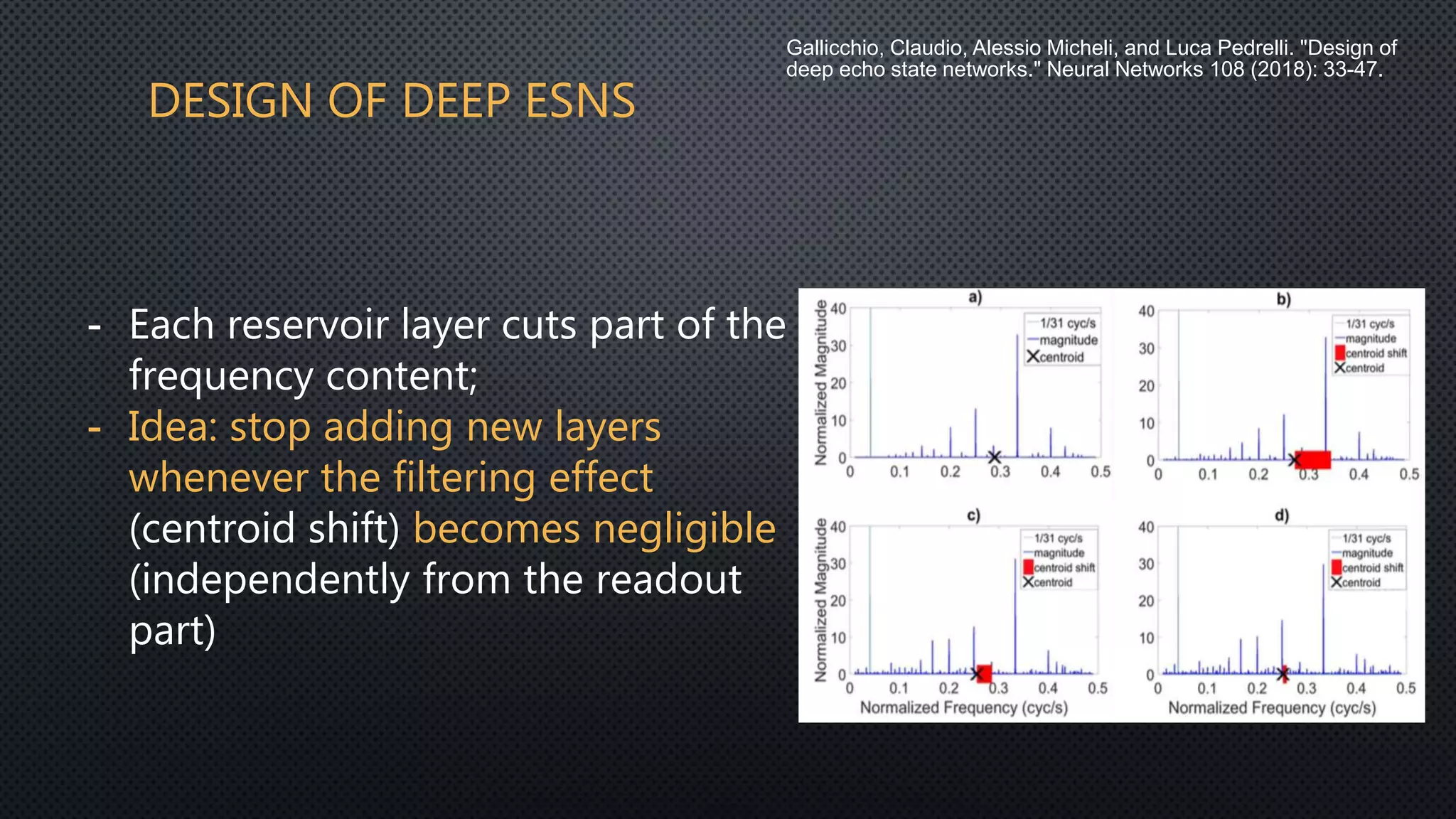
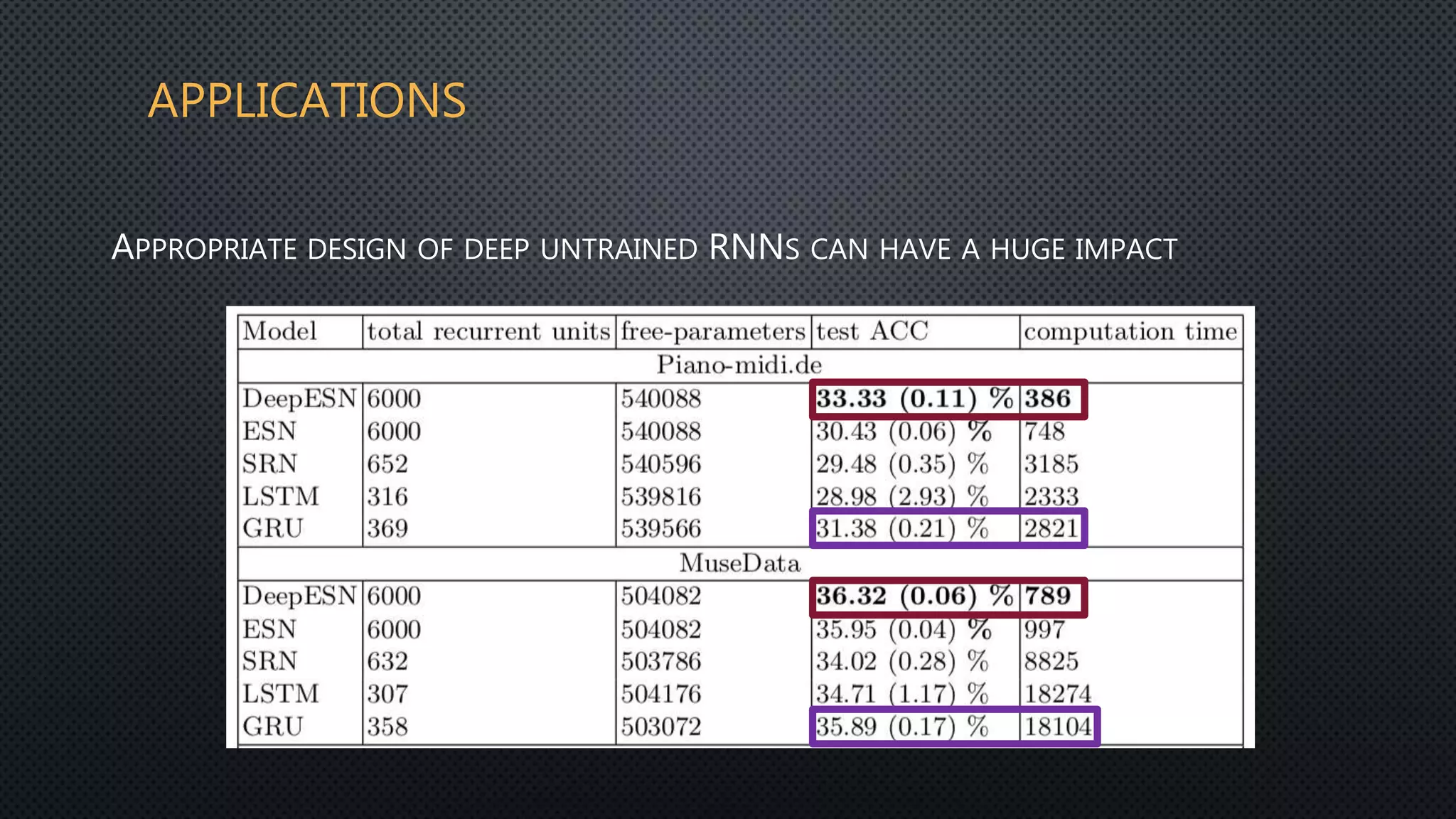
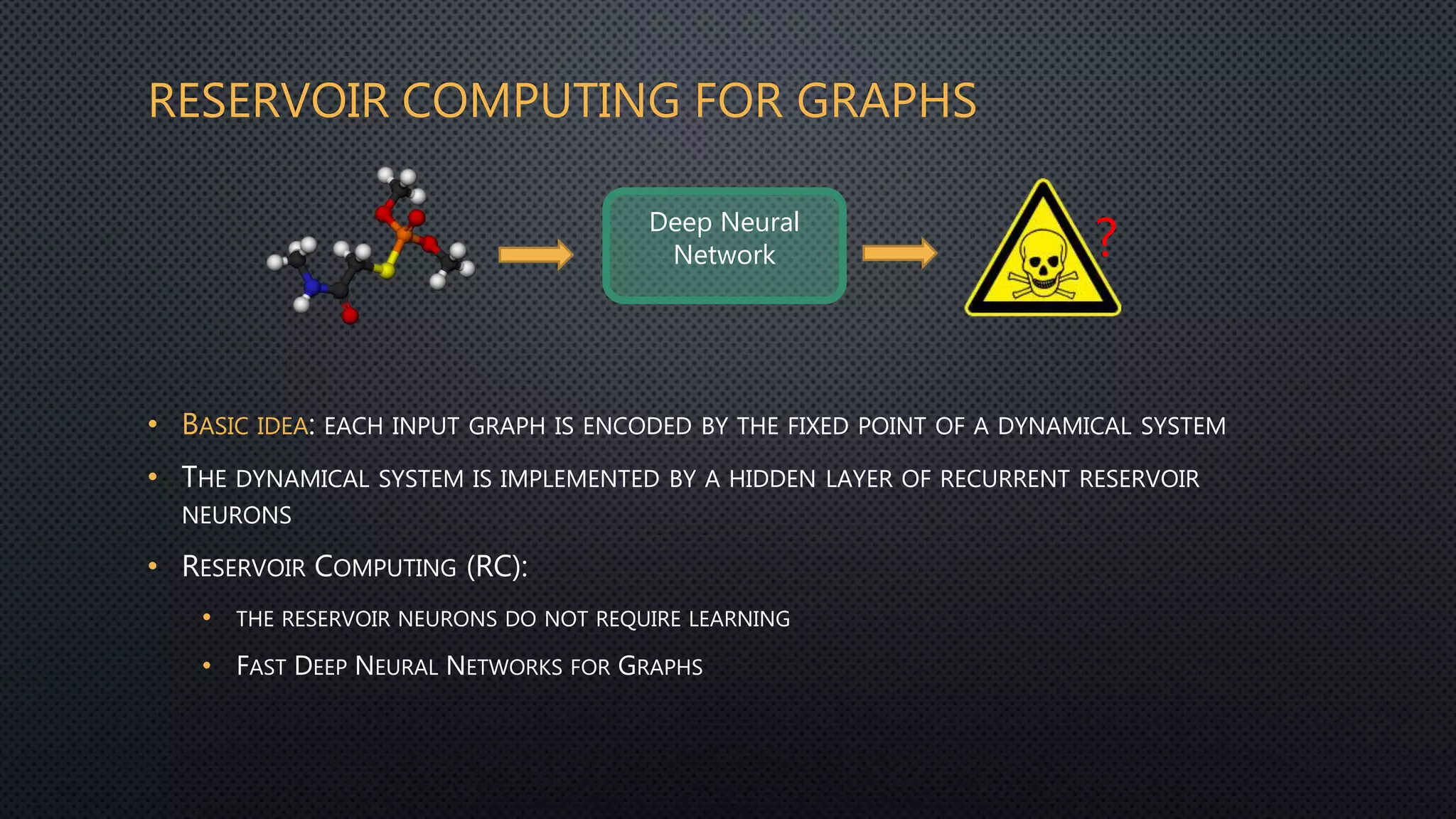
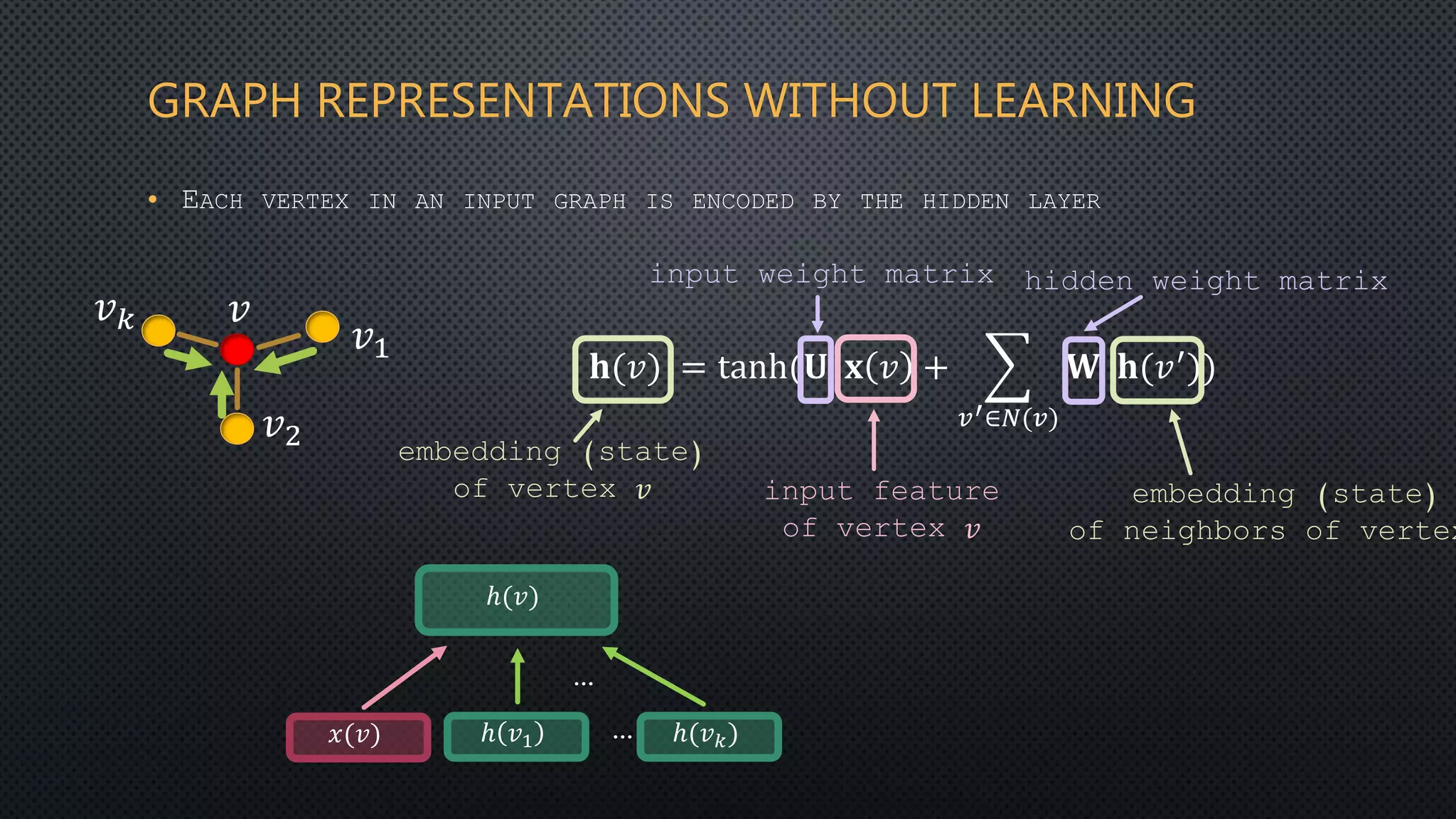


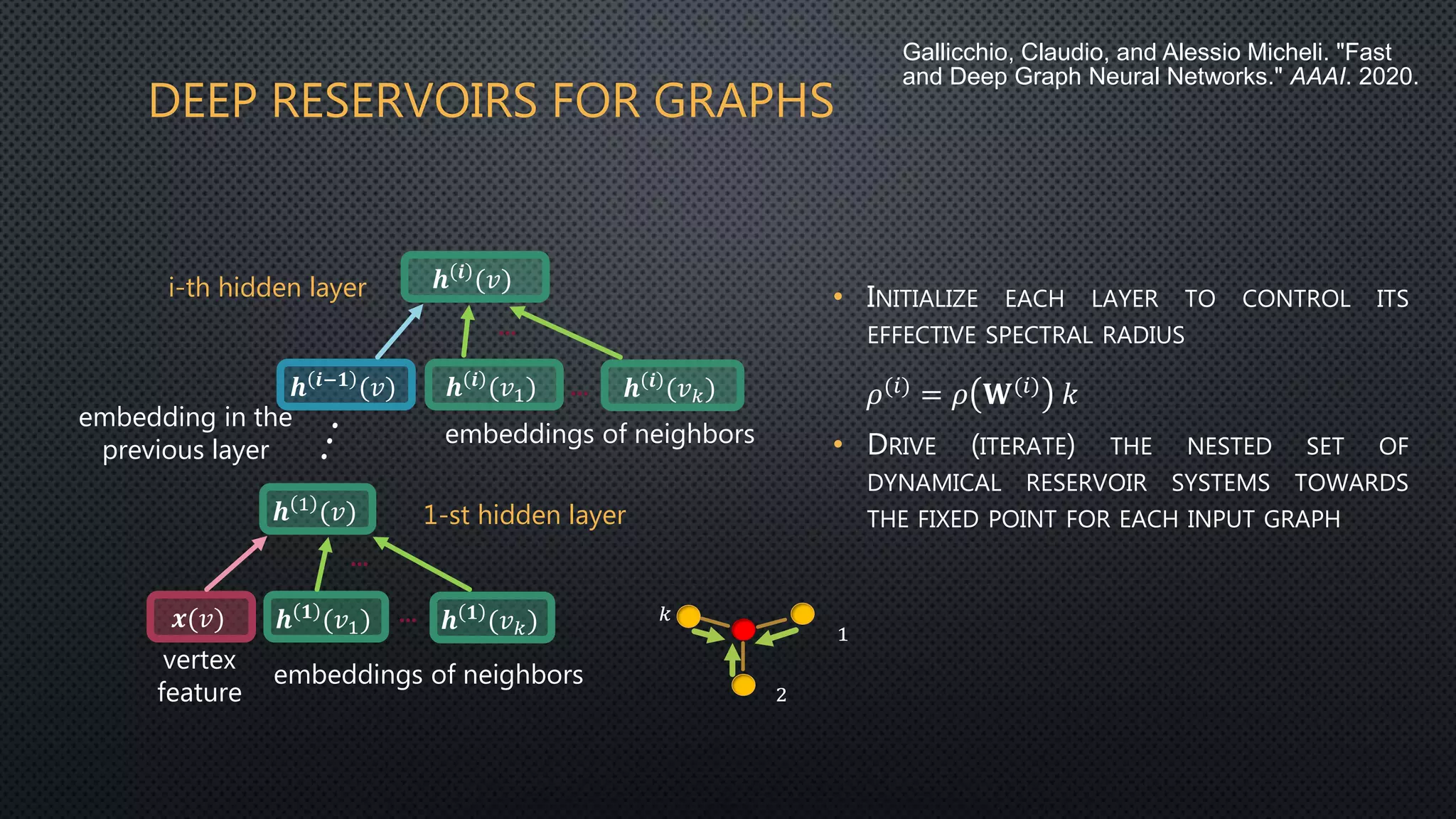
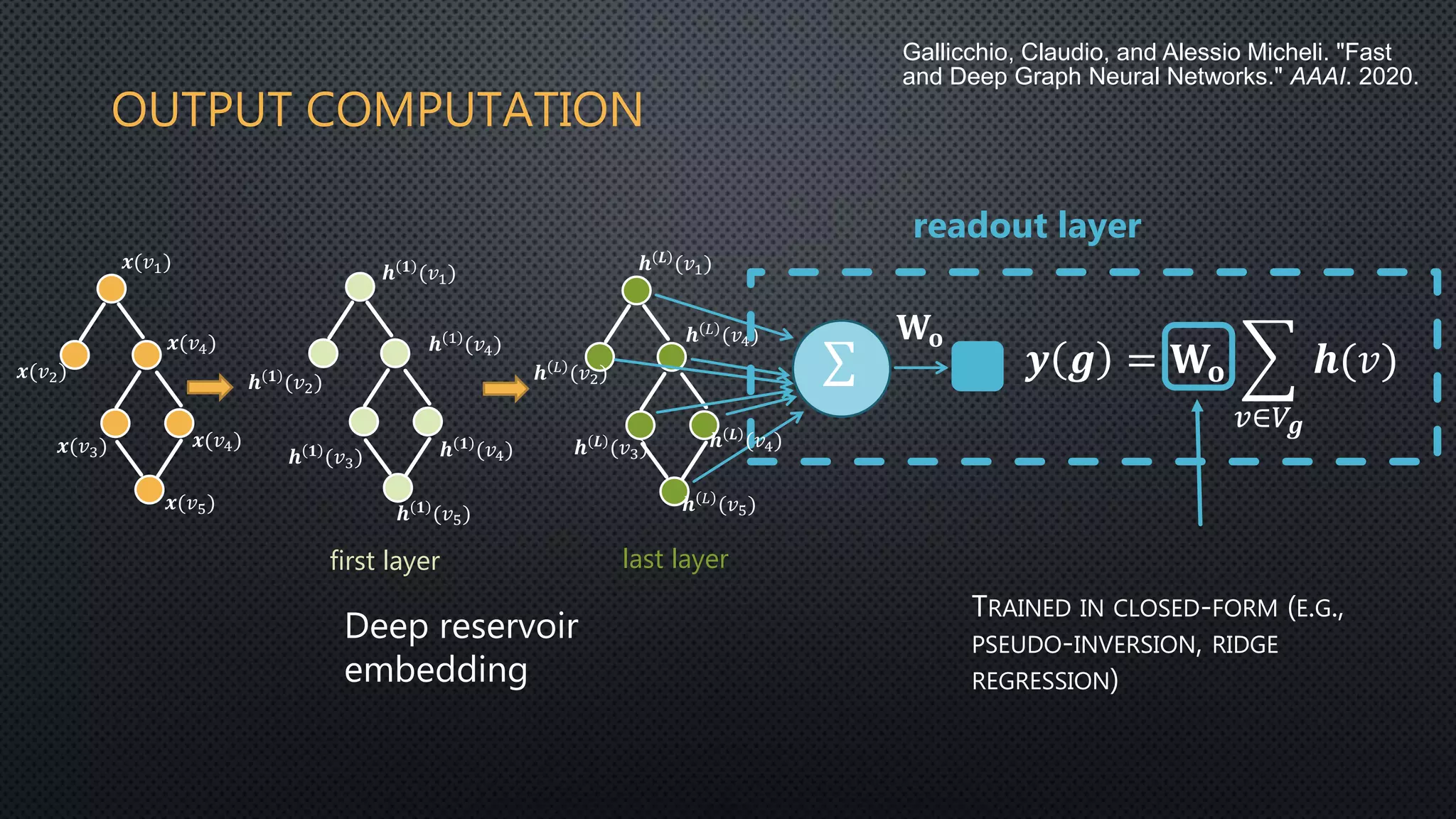
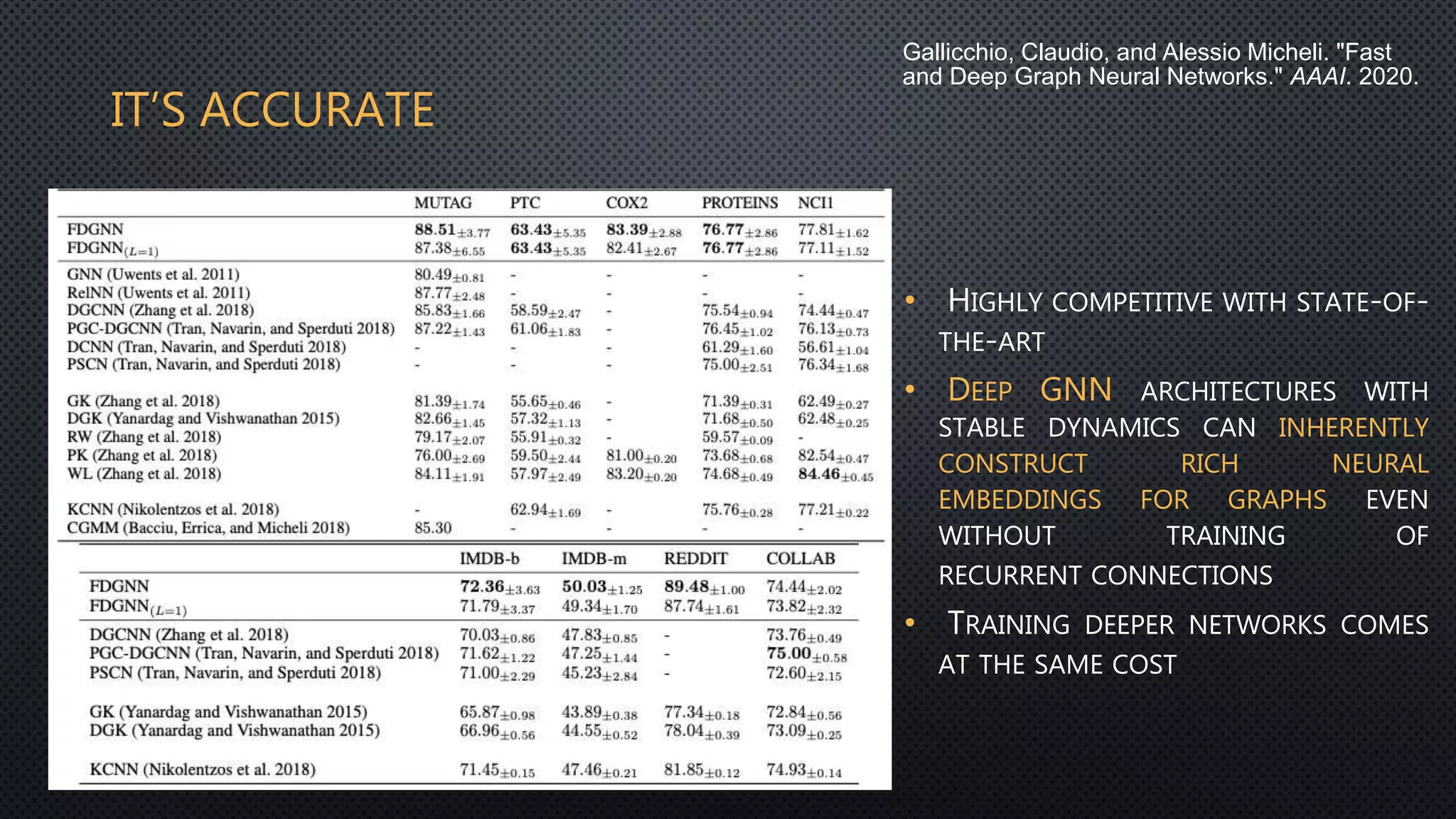




This document discusses deep reservoir computing for structured data like time-series and graphs. Recurrent neural networks are naturally suited for sequential data but are difficult to train. Reservoir computing addresses this by only training the output layer, leaving the recurrent hidden layer untrained. Stacking multiple reservoir layers leads to deep reservoir computing, which develops richer dynamics. For graphs, each node is encoded by the fixed point of a dynamical system implemented as a reservoir network. Deep reservoirs can inherently construct rich embeddings for graphs without training recurrent connections. This makes graph neural networks accurate yet fast compared to state-of-the-art methods that require training deep architectures.




























![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Sponsored] C3.ai description](https://cdn.slidesharecdn.com/ss_thumbnails/c3deckmeetupnovember252019v2-191128092146-thumbnail.jpg?width=640&height=640&fit=bounds)

































