





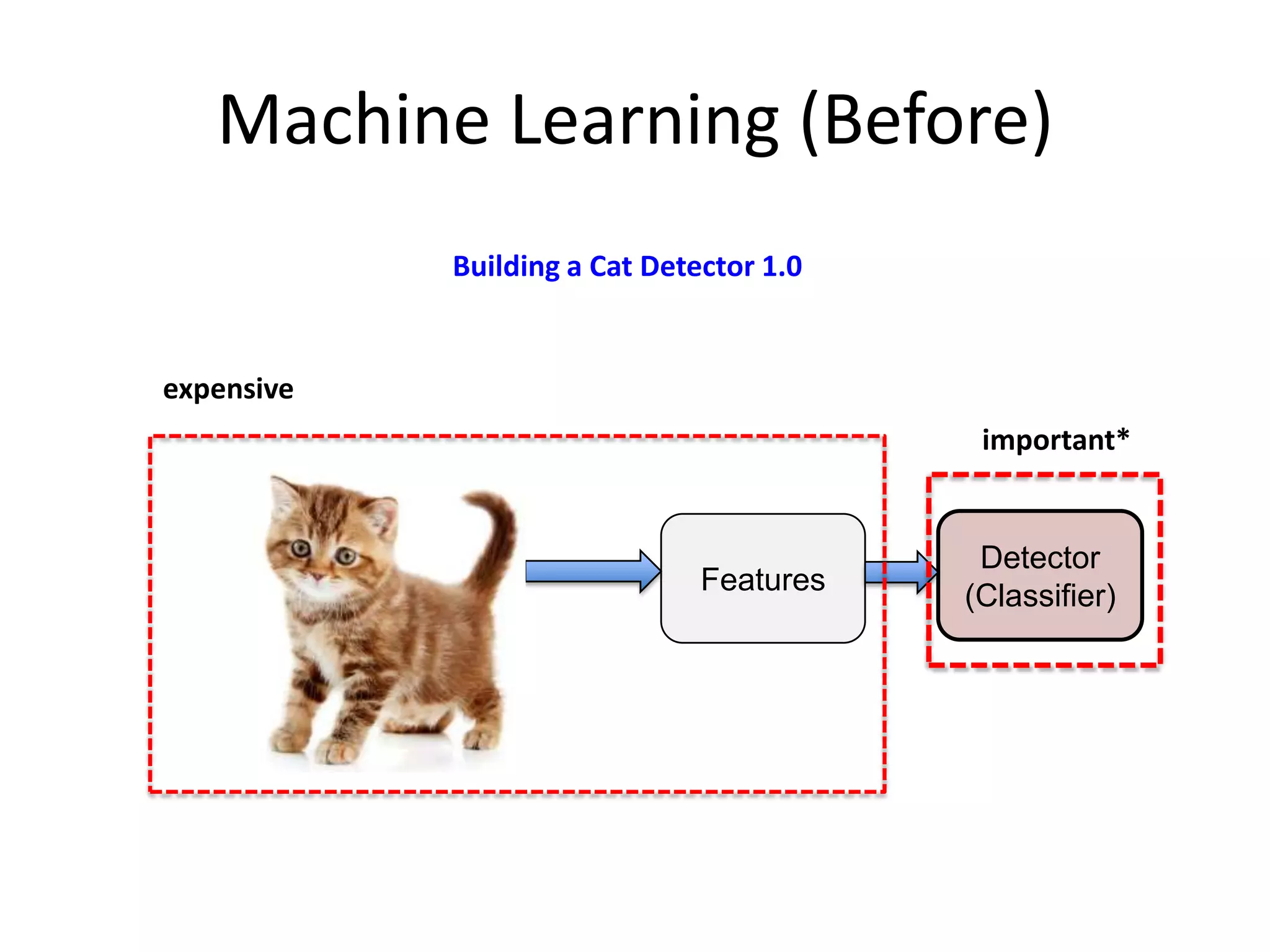
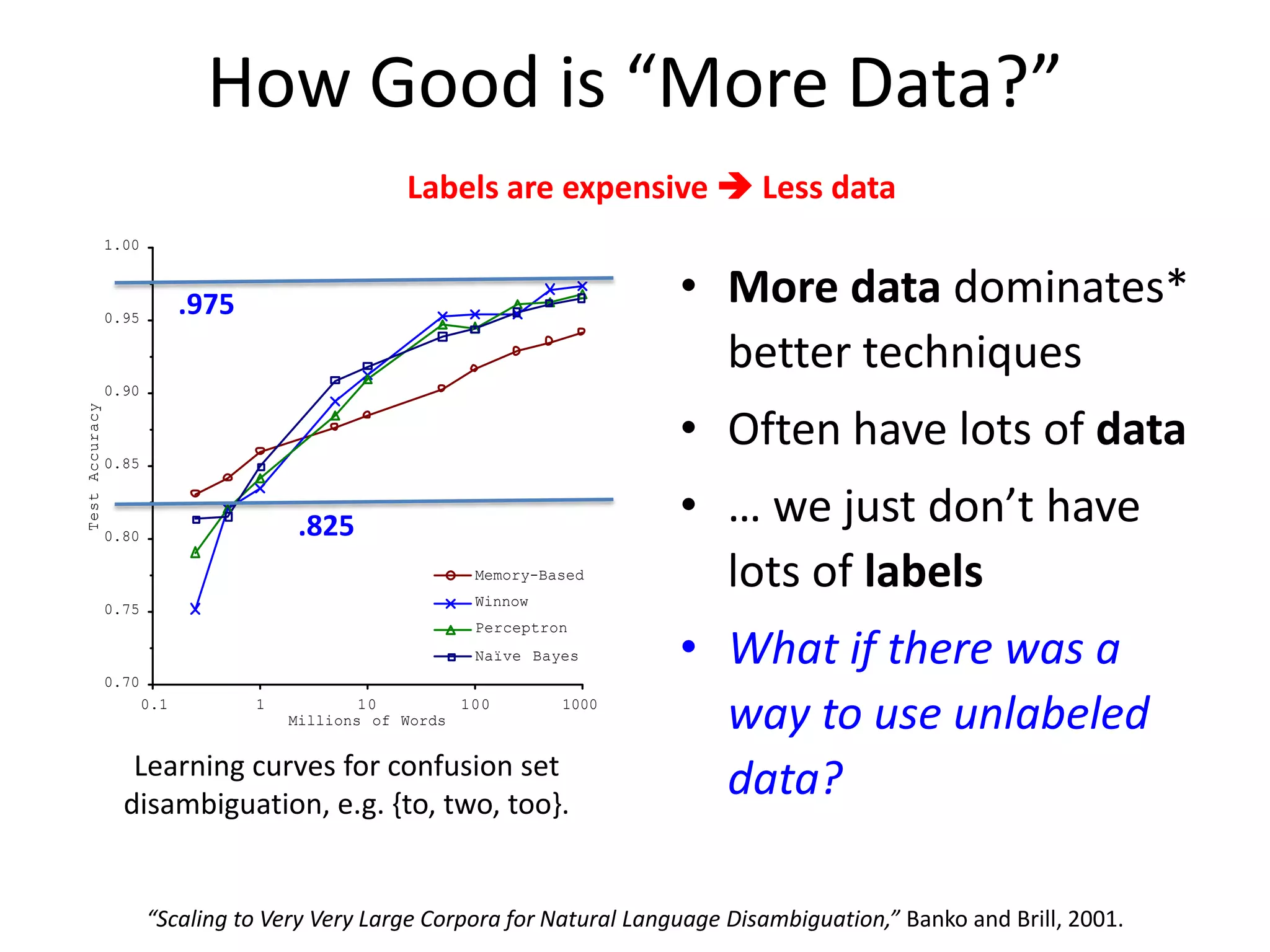

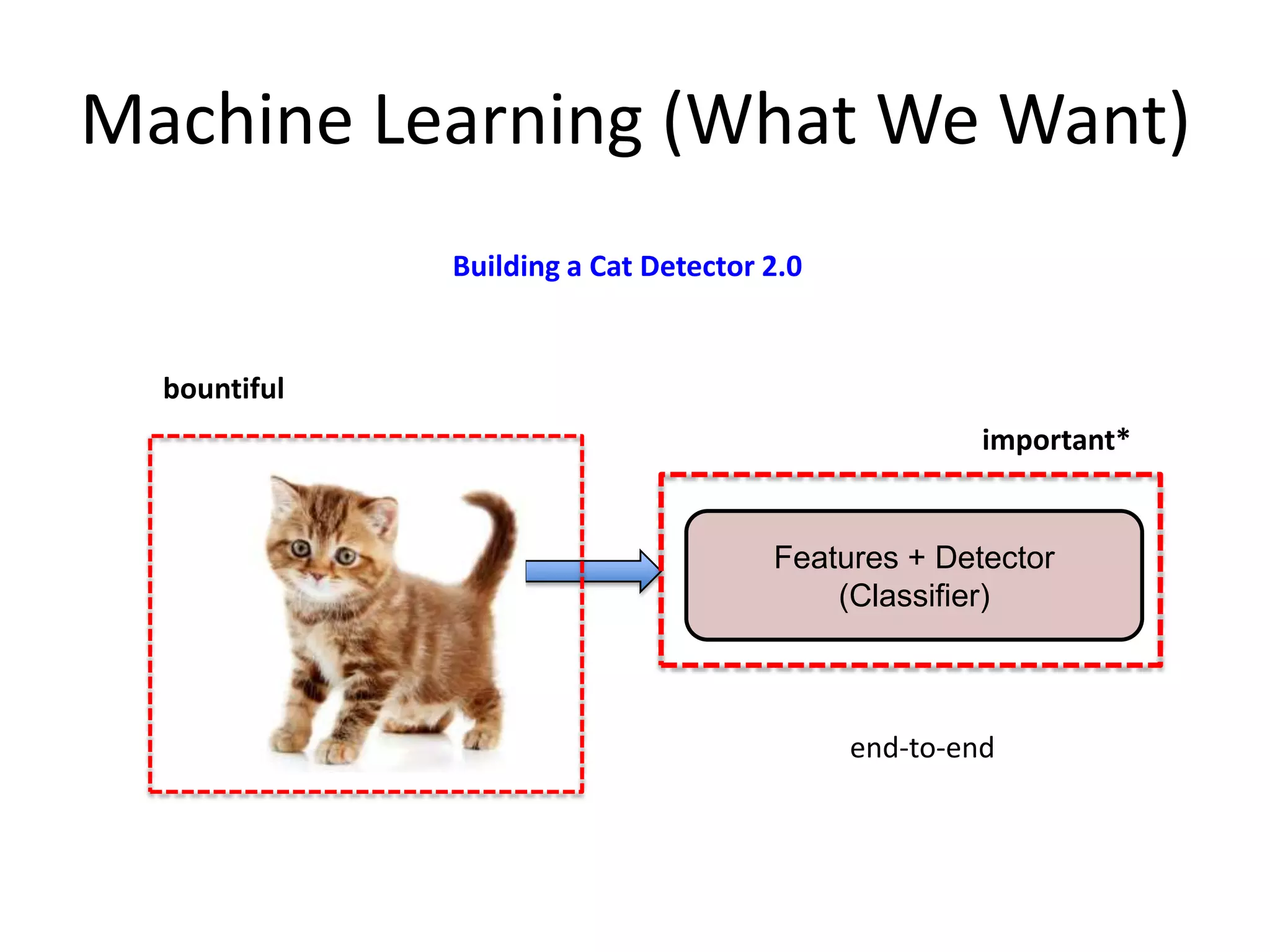
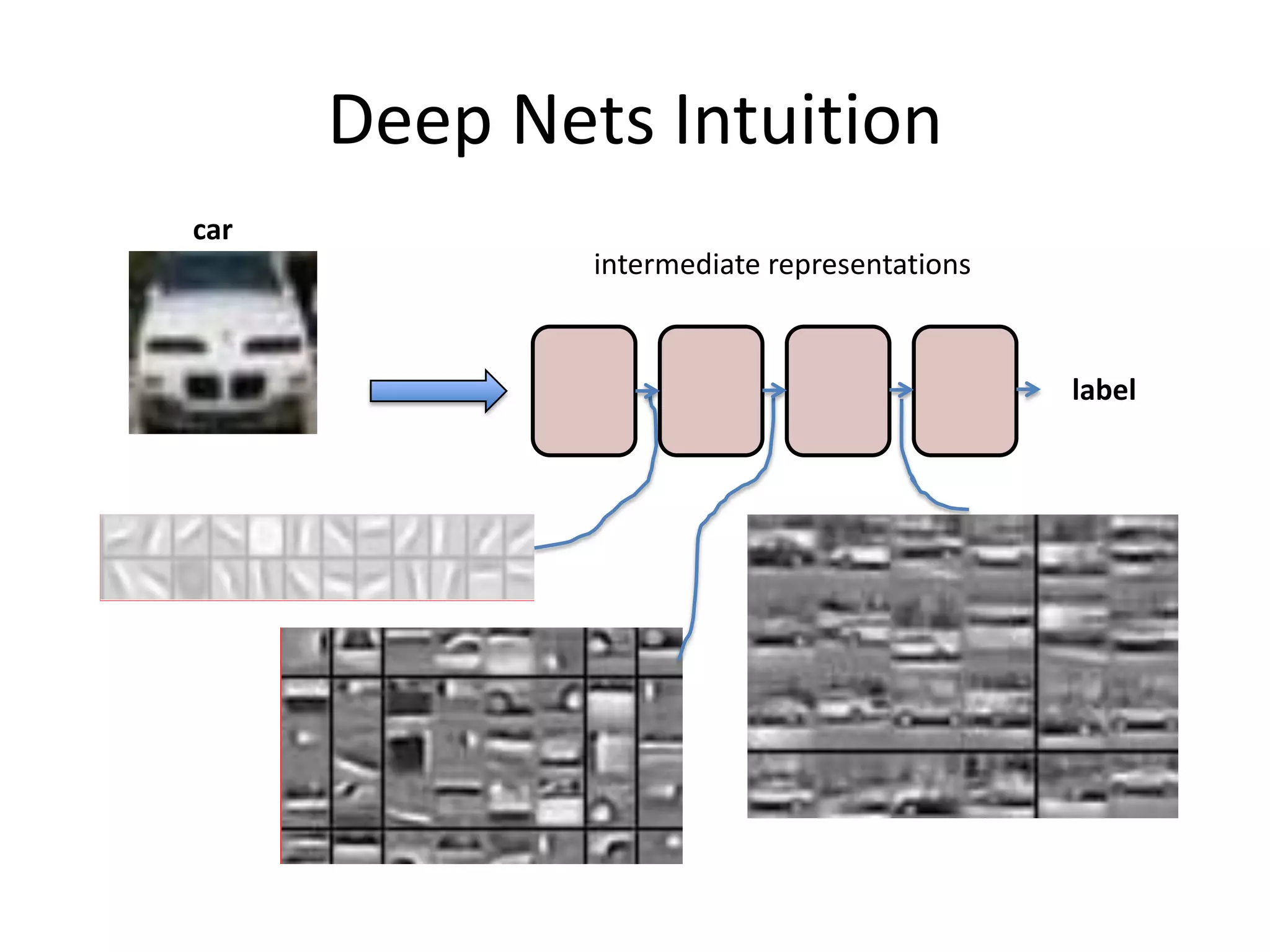





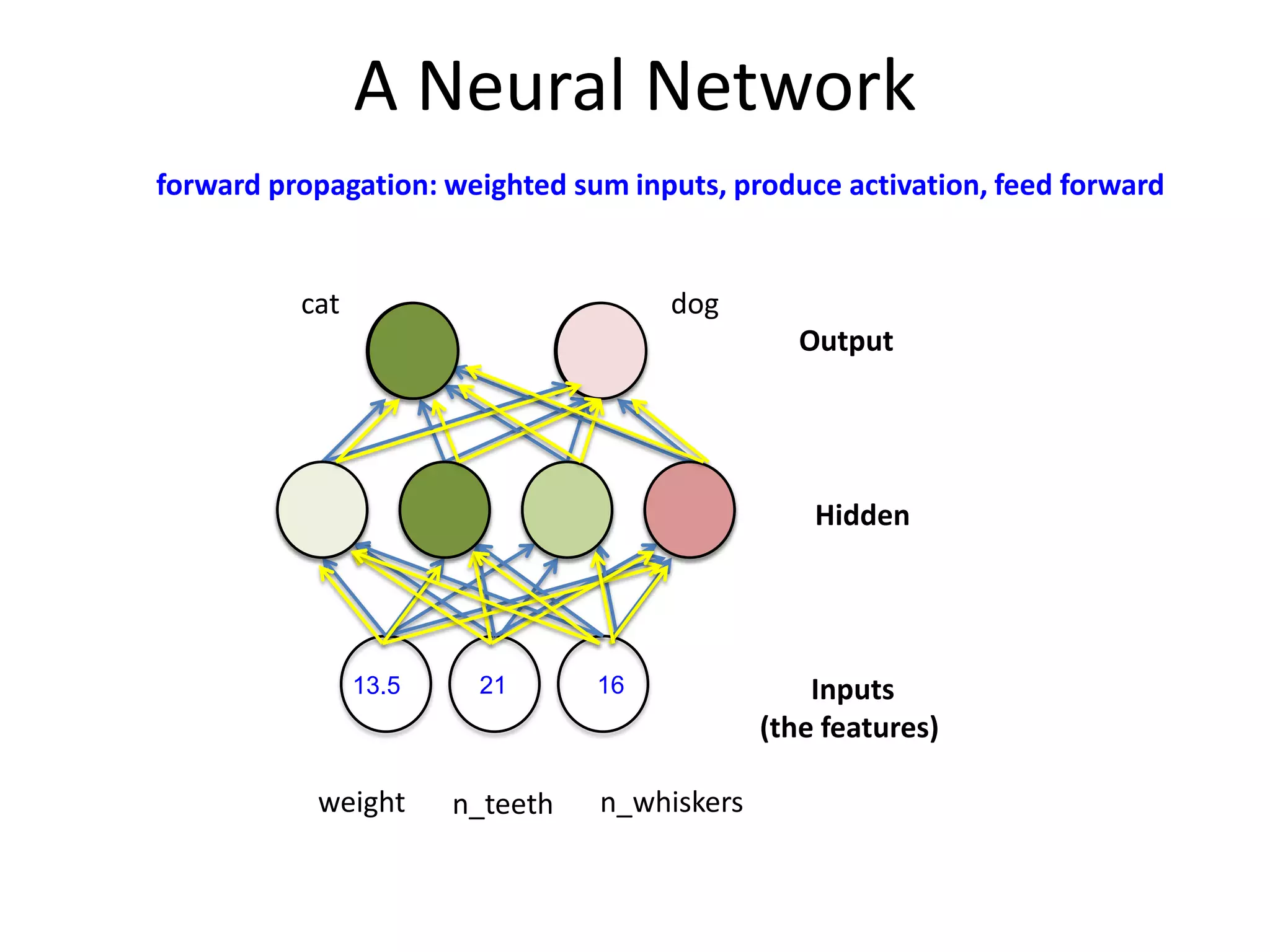

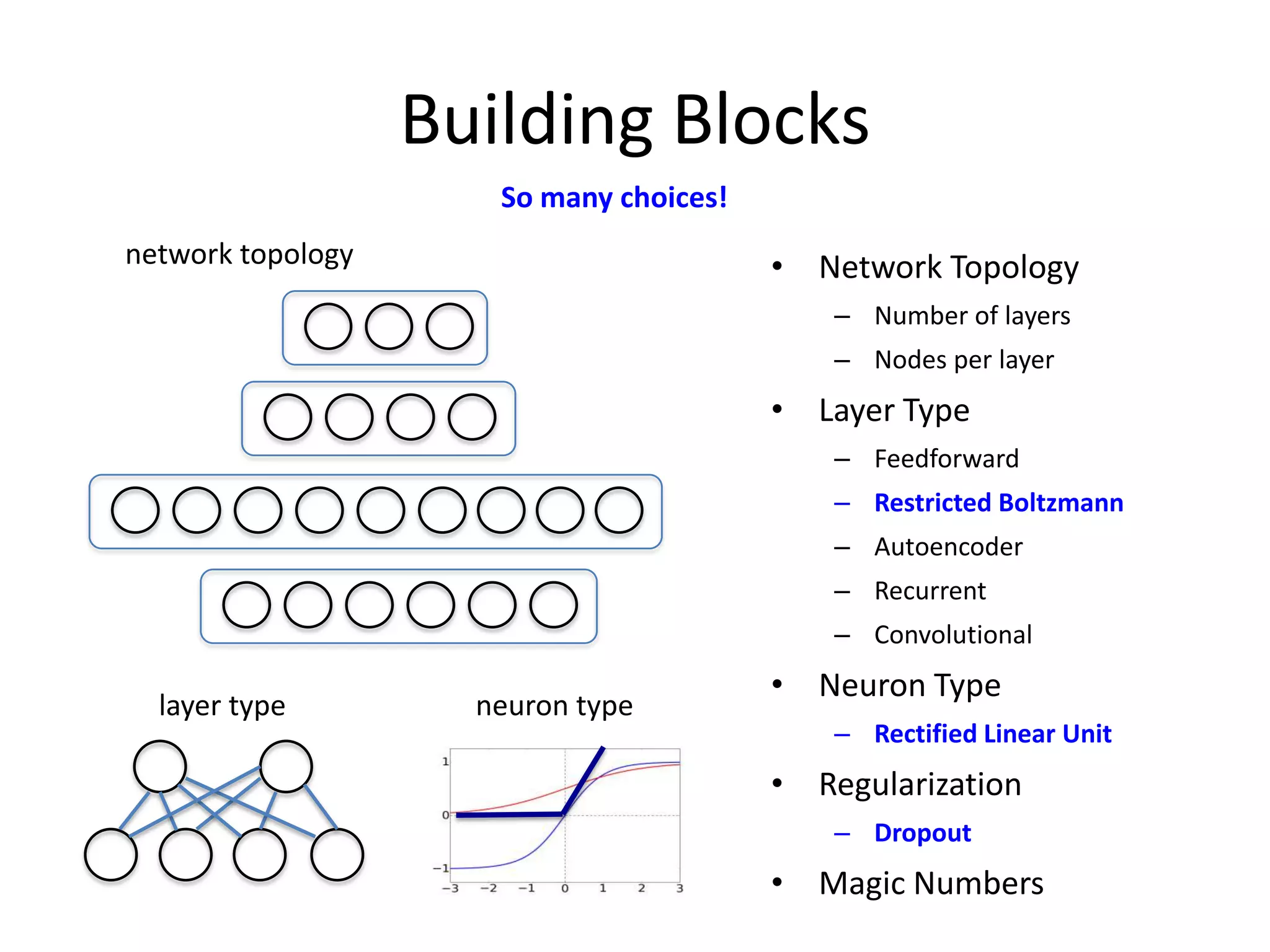
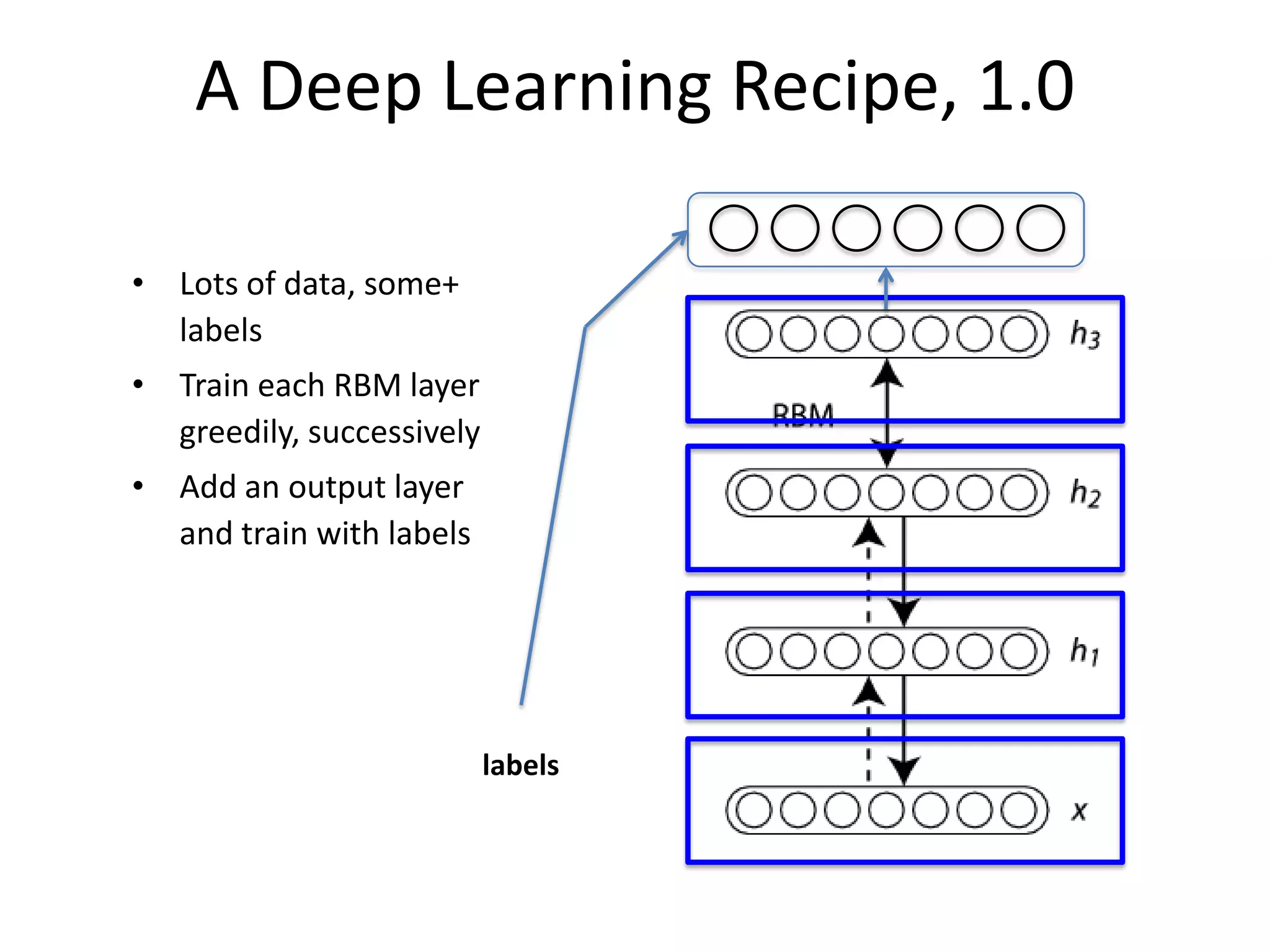
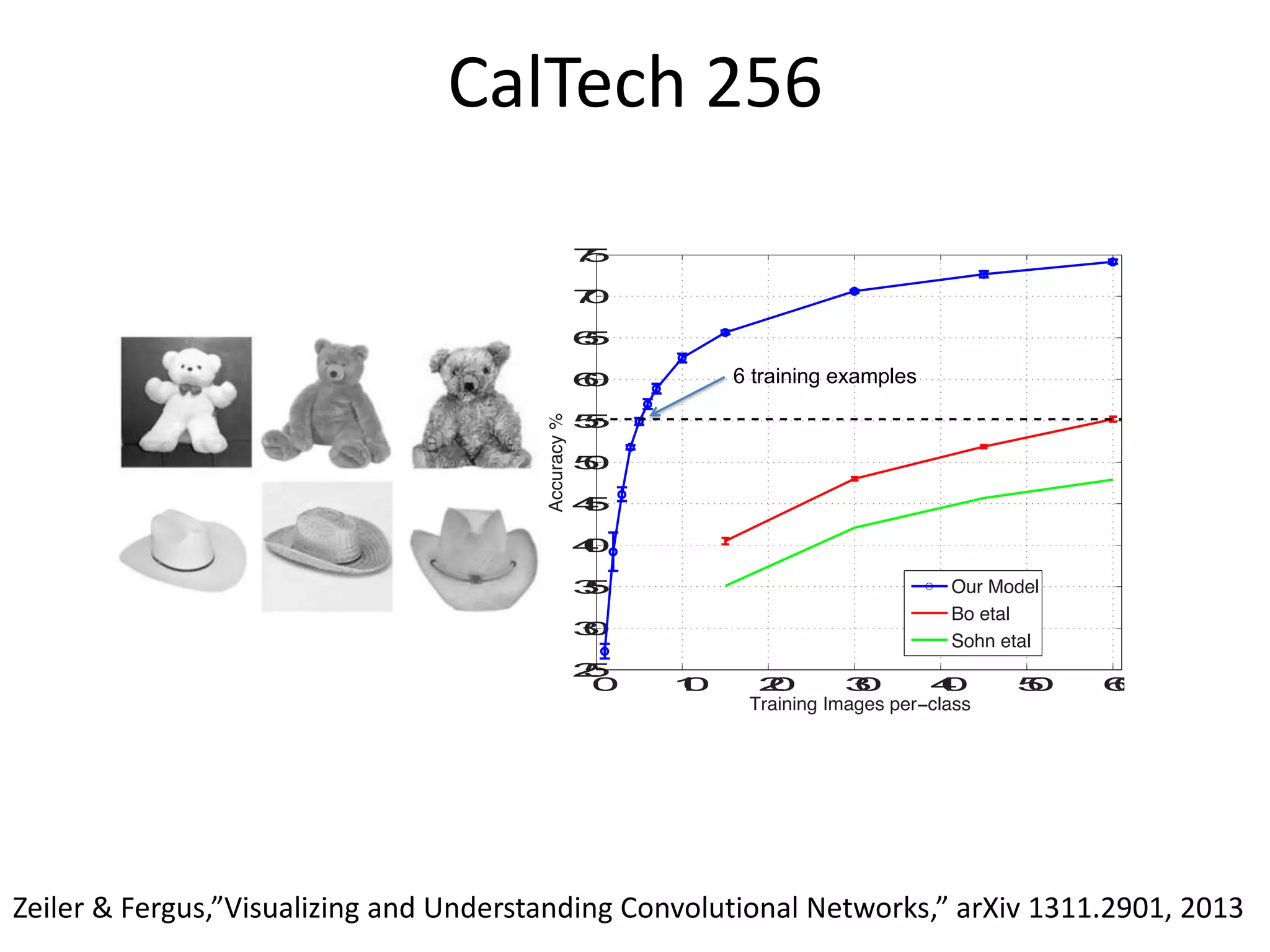
![After Training
network
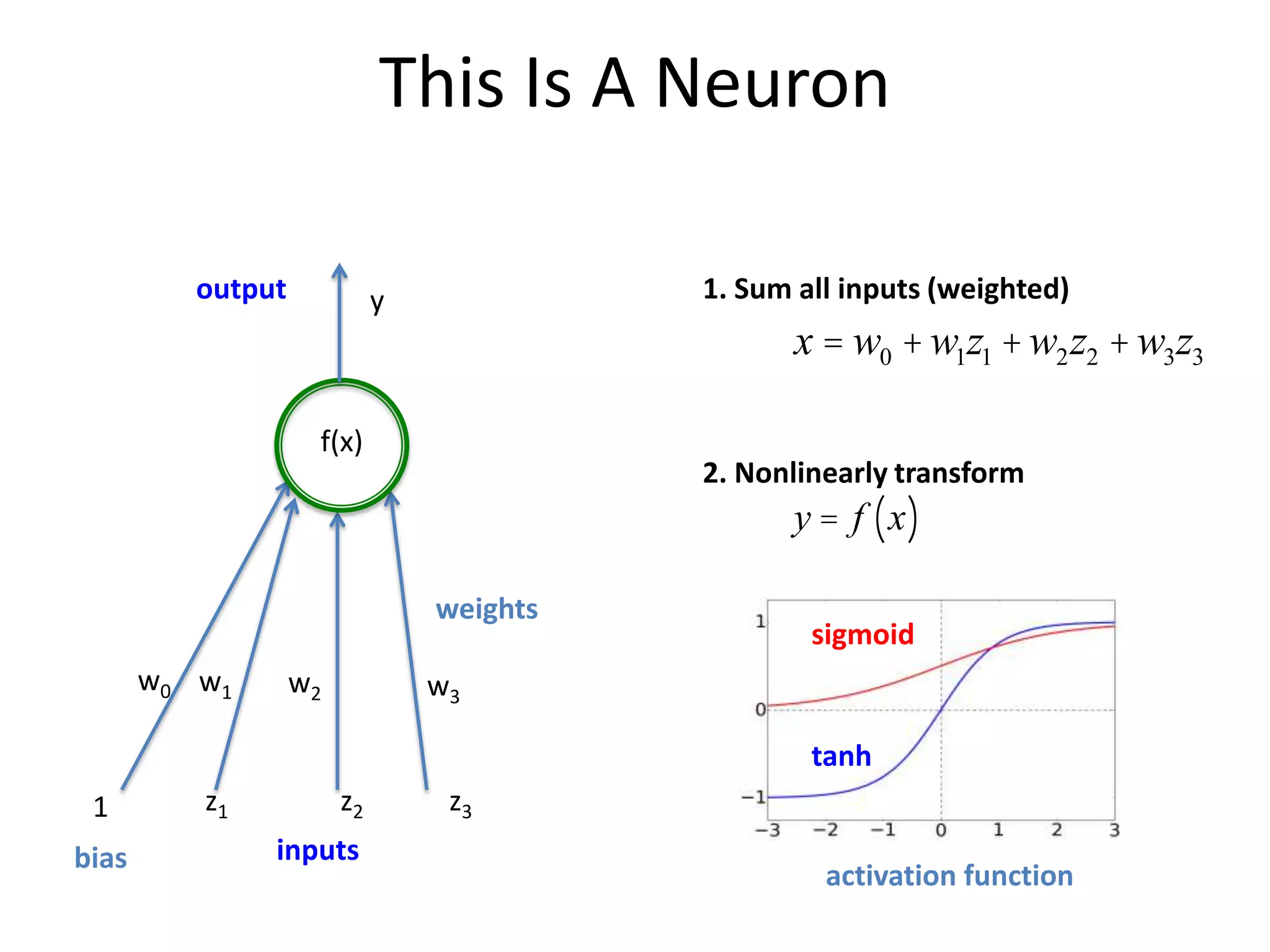
layer weights
weights as a matrix
[.5, -.2, 4, .15, -1,…]
-.5
.4
0
.1
.1
.5
-1
2
[-.5, -.3, .4, 0, …]
-.3
.7
-.2
.4
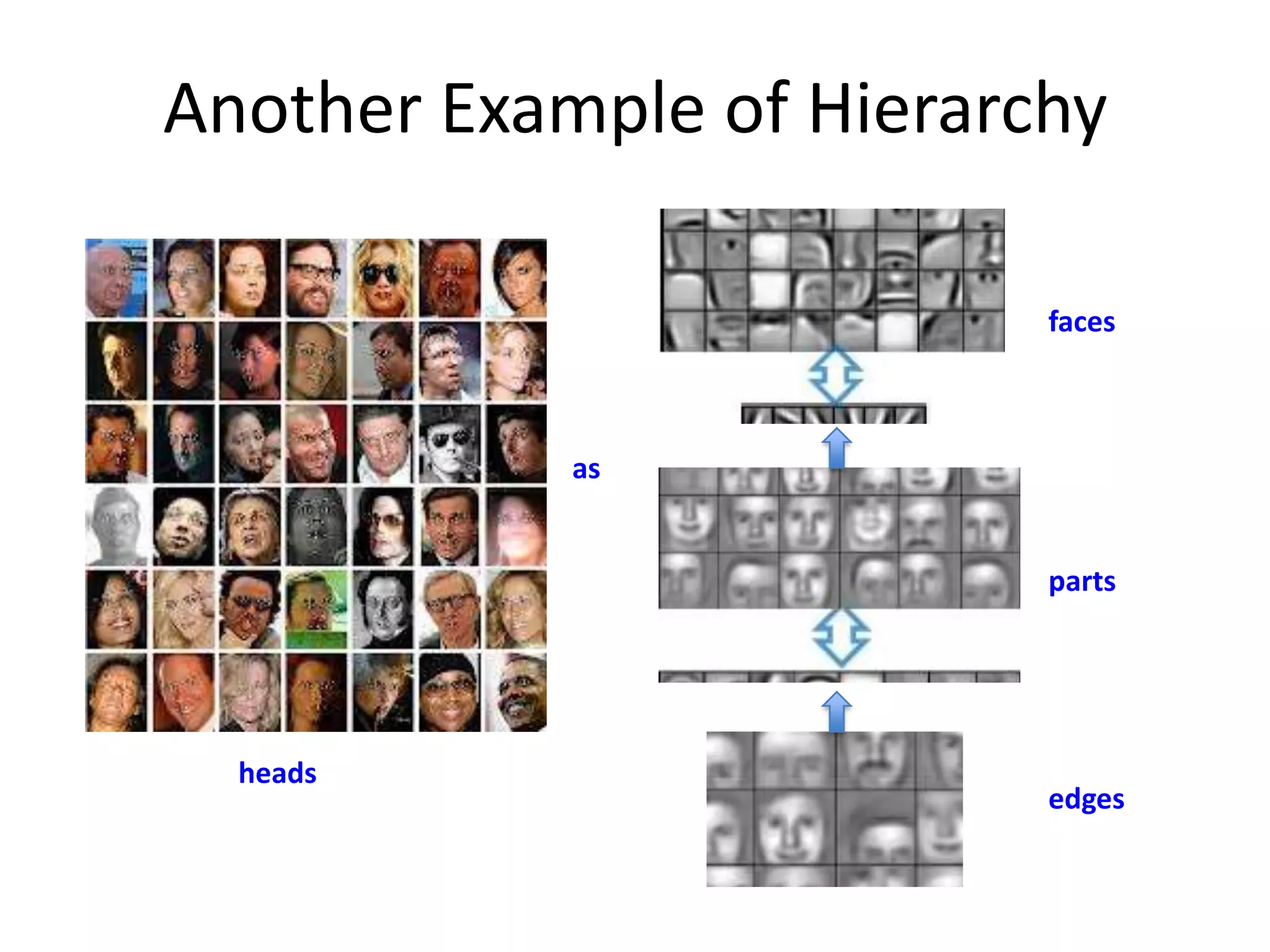
we can view weight matrix as image
… plus performance evaluation & logging](https://image.slidesharecdn.com/dsatl-deeplearning-alpharetta-slideshare-140108235833-phpapp01/75/Deep-Learning-for-Data-Scientists-Data-Science-ATL-Meetup-Presentation-2014-01-08-27-2048.jpg)









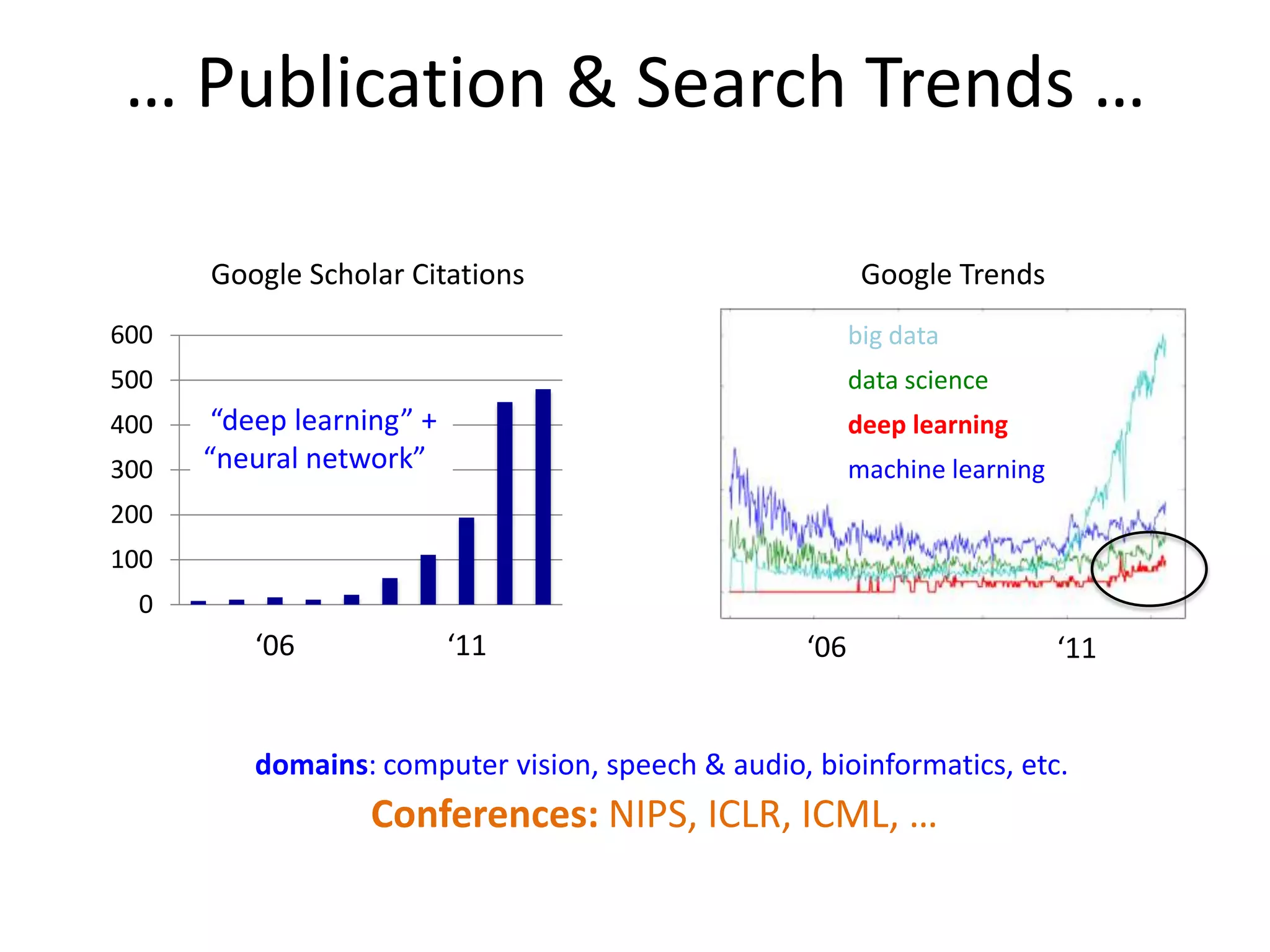
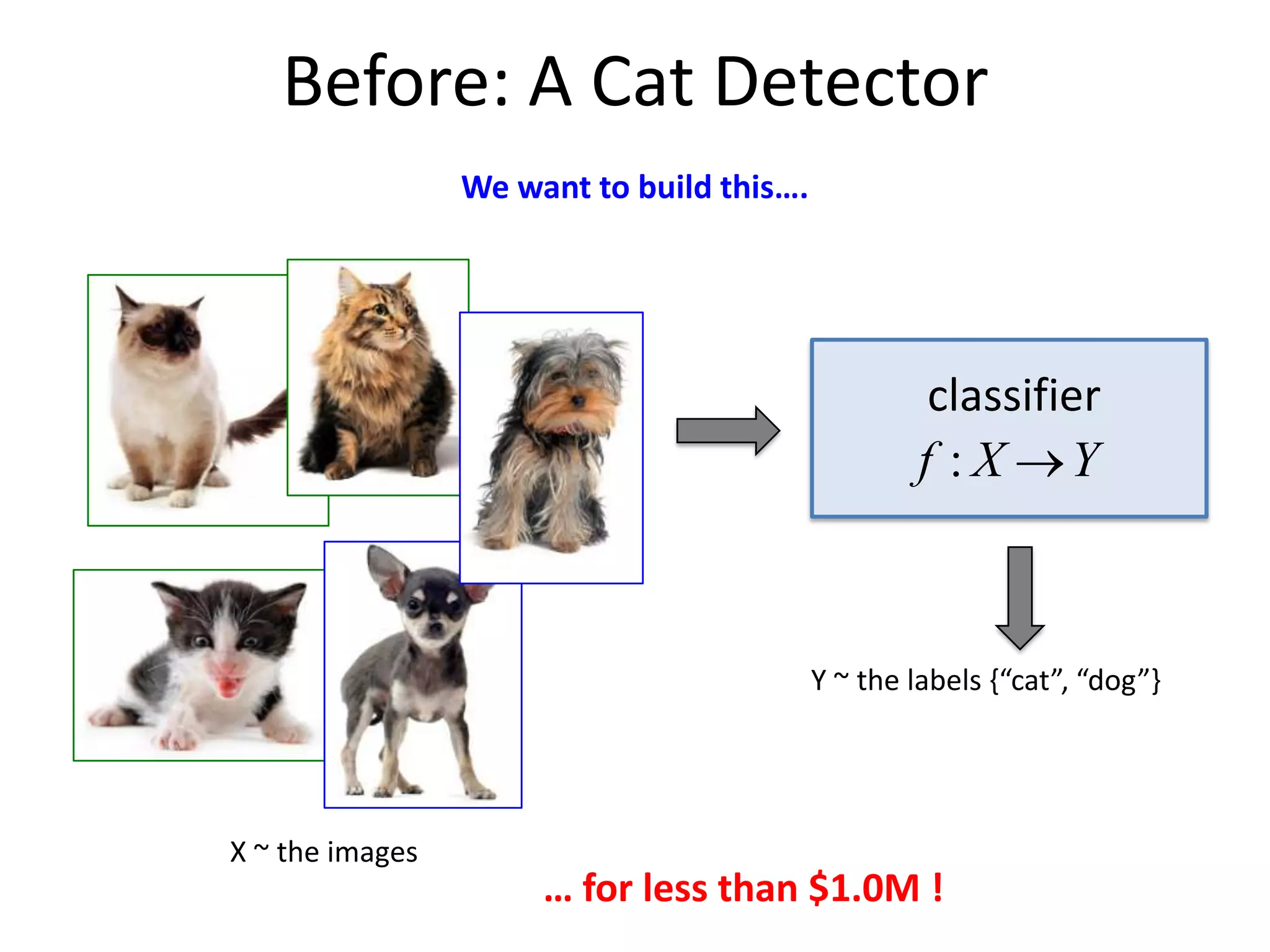
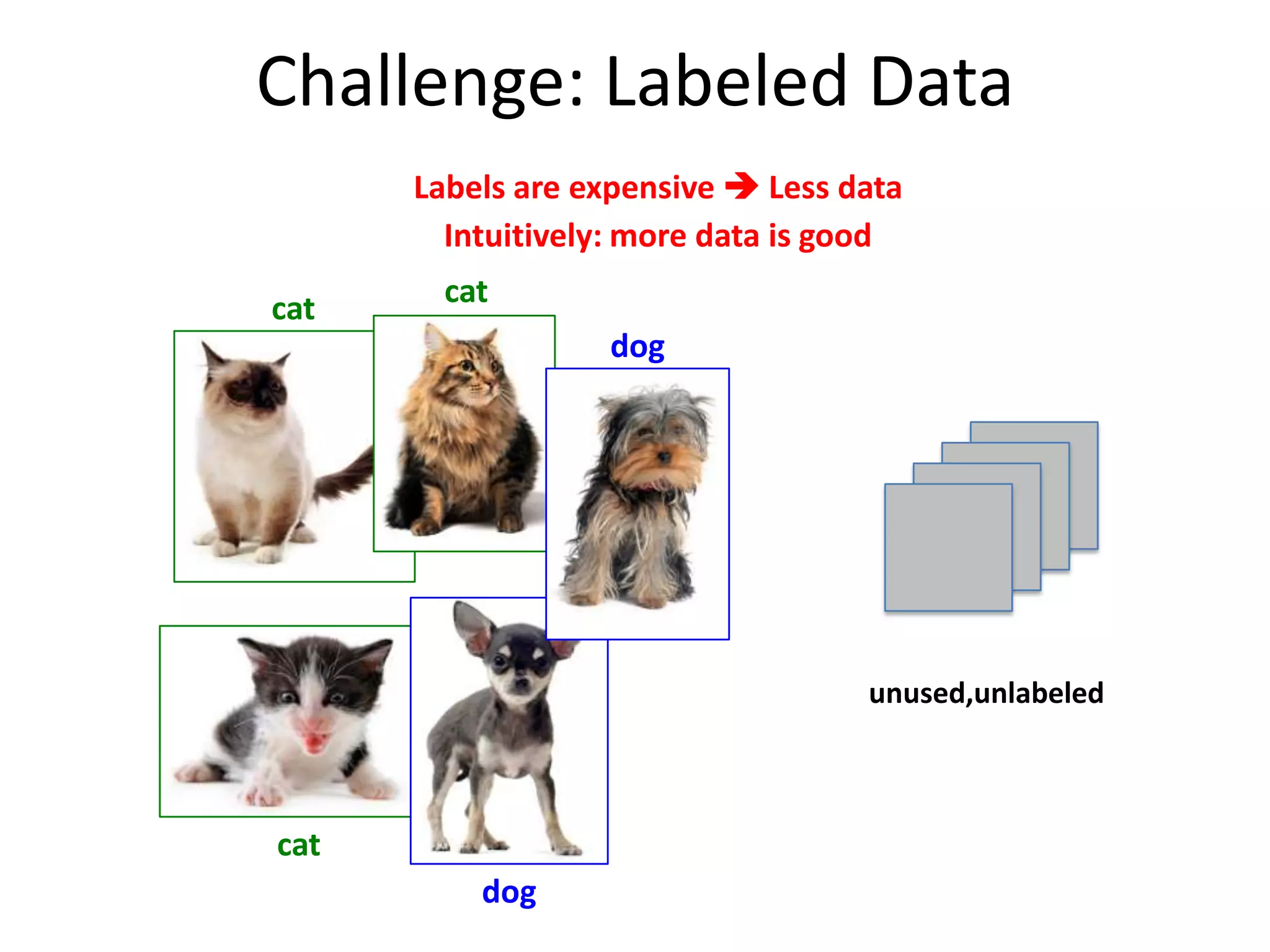
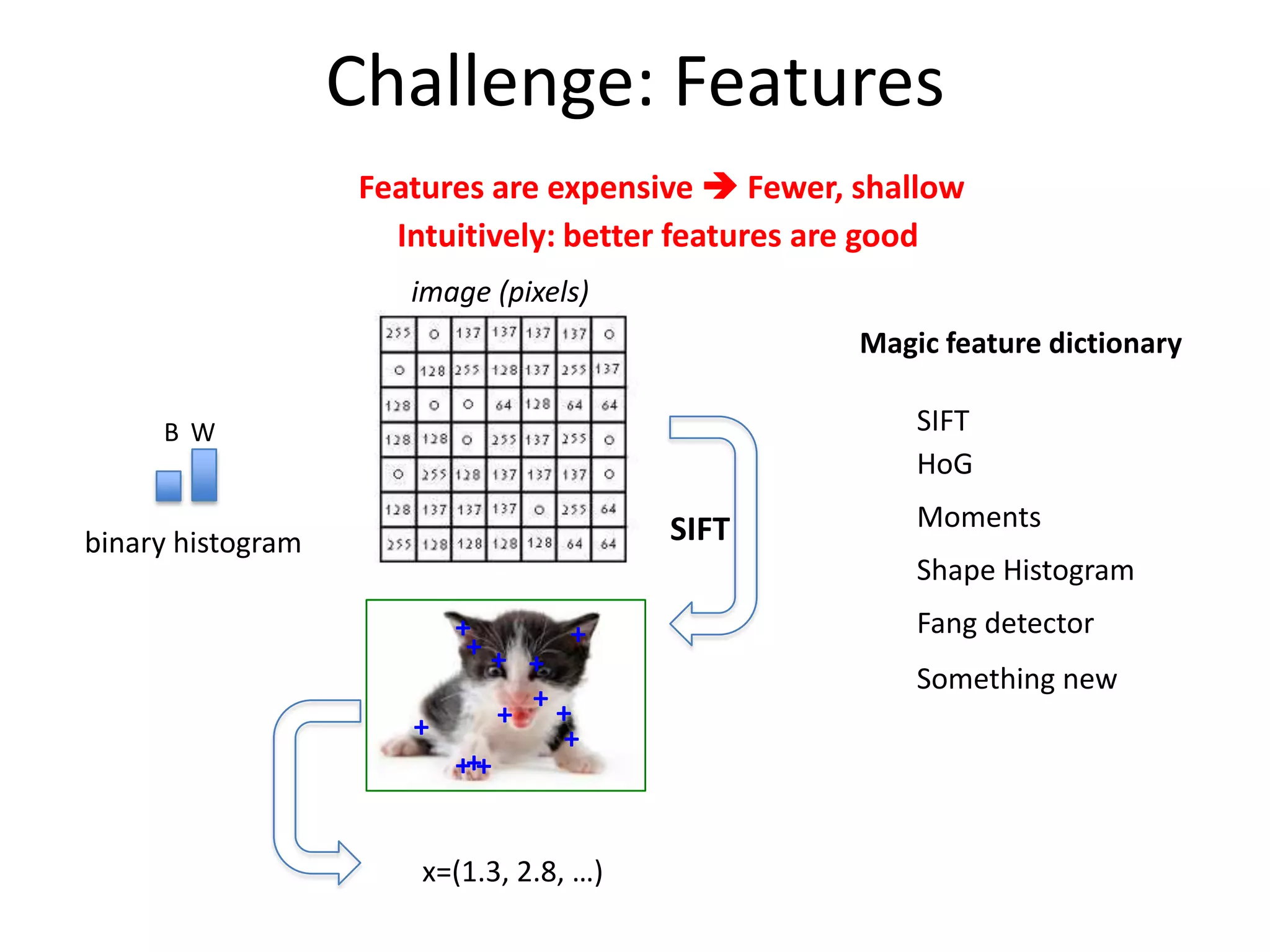
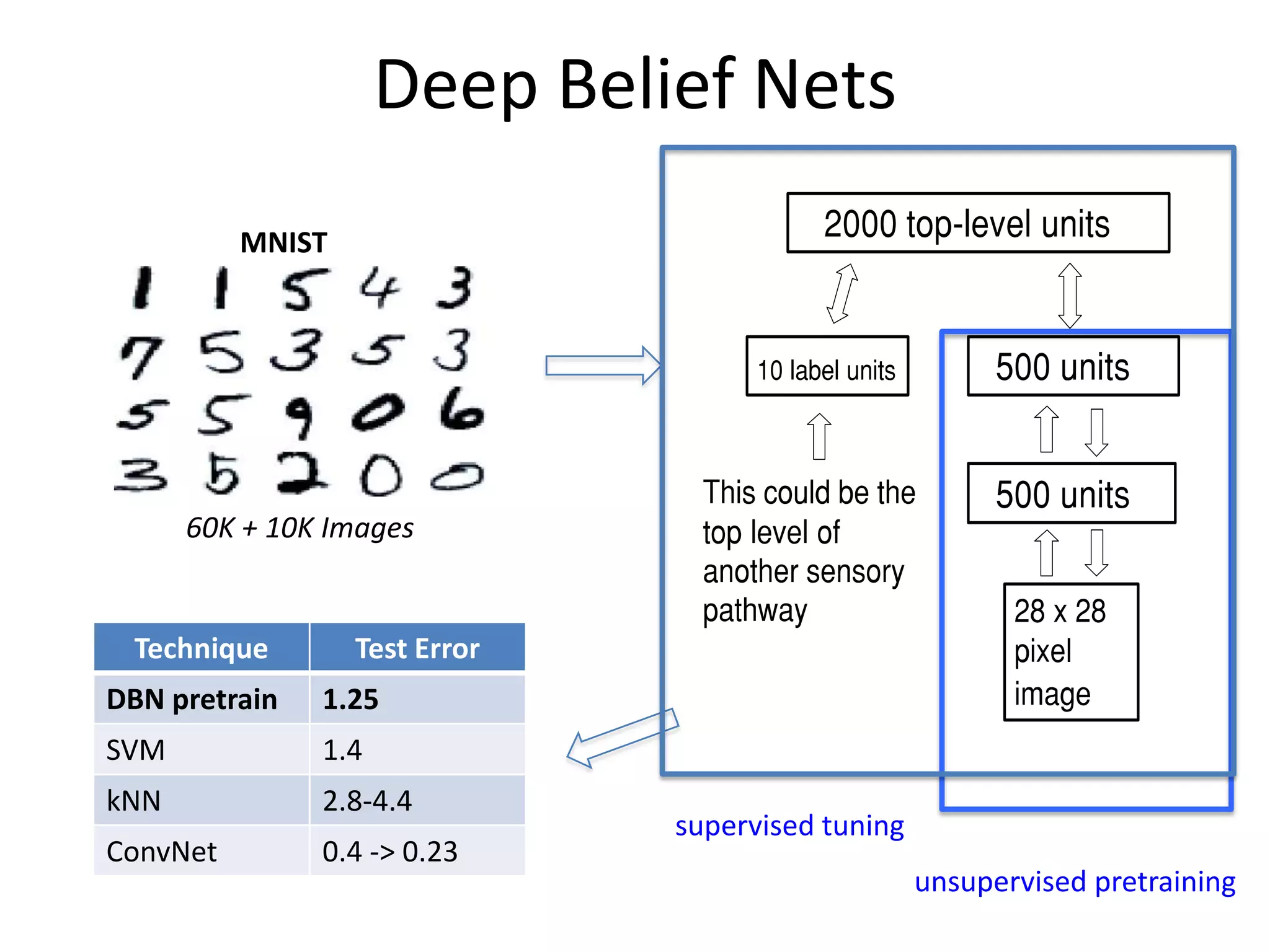
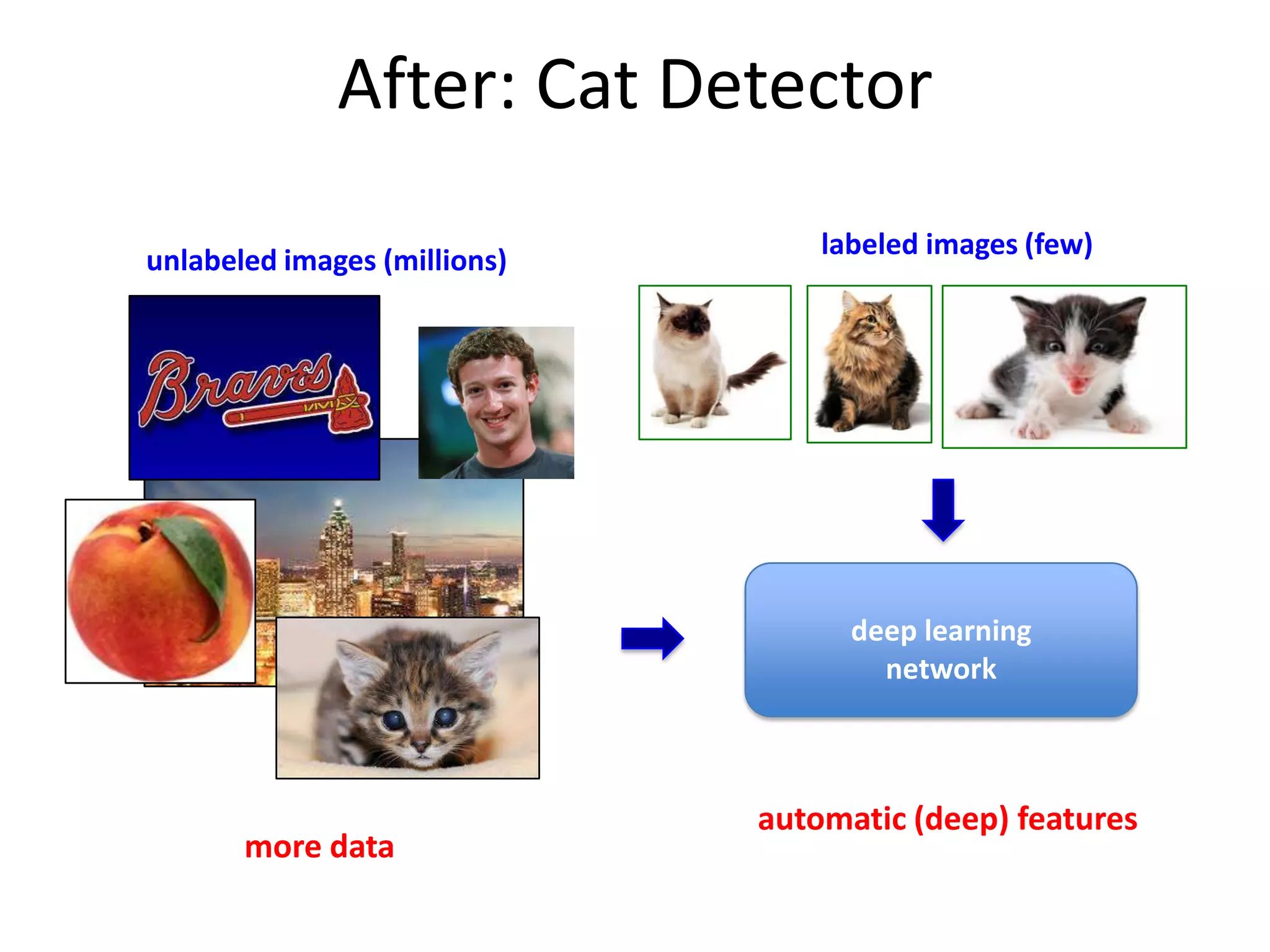
This document discusses the evolution and impact of deep learning in artificial intelligence, highlighting key figures and institutions involved in its development. It reviews the advantages of using unlabeled data to improve model performance and emphasizes the significance of feature learning and deep architectures. Additionally, it covers various applications of deep learning across fields such as speech recognition, image classification, and natural language processing.






























































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)





