Download as PDF, PPTX


































![• [1] Yu, Lei, Karl Moritz Hermann, Phil Blunsom, and Stephen Pulman. "Deep learning for
answer sentence selection." arXiv preprint arXiv:1412.1632 (2014).- online
here: https://arxiv.org/pdf/1412.1632.pdf
• [2] - Iyyer, Mohit, Jordan L. Boyd-Graber, Leonardo Max Batista Claudino, Richard Socher,
and Hal Daumé III. "A Neural Network for Factoid Question Answering over Paragraphs."
In EMNLP, pp. 633-644. 2014 - online
here: https://cs.umd.edu/~miyyer/pubs/2014_qb_rnn.pdf
• [3] - Tan, Ming, Bing Xiang, and Bowen Zhou. "LSTM-based Deep Learning Models for
non-factoid answer selection." arXiv preprint arXiv:1511.04108 (2015) - online
here: https://arxiv.org/pdf/1511.04108v4.pdf
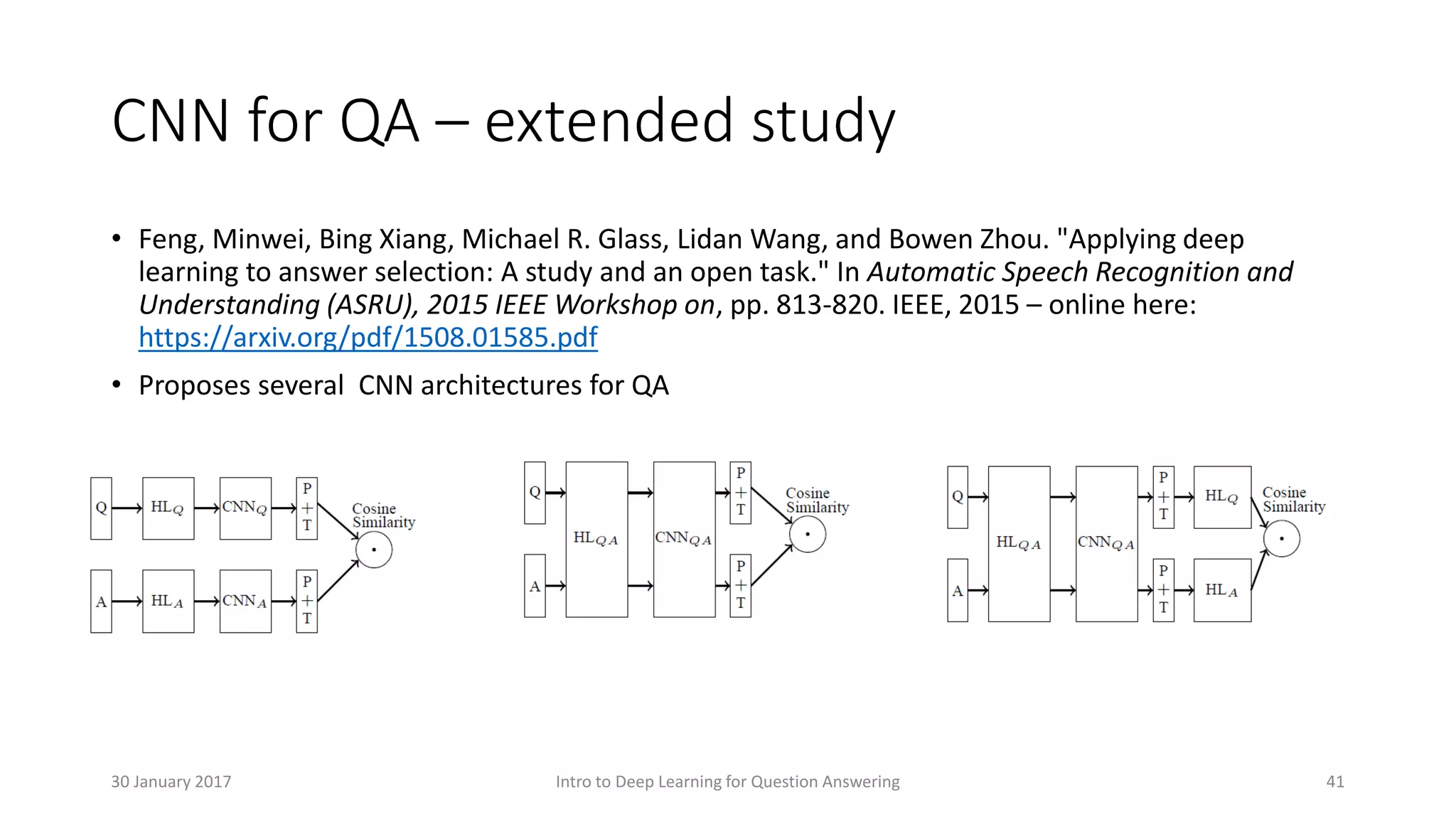
• [4] - Feng, Minwei, Bing Xiang, Michael R. Glass, Lidan Wang, and Bowen Zhou. "Applying
deep learning to answer selection: A study and an open task." In Automatic Speech
Recognition and Understanding (ASRU), 2015 IEEE Workshop on, pp. 813-820. IEEE, 2015
– online here: https://arxiv.org/pdf/1508.01585.pdf
References
Intro to Deep Learning for Question Answering 4230 January 2017](https://image.slidesharecdn.com/introtodeeplearningforquestionanswering-170130223740/75/Intro-to-Deep-Learning-for-Question-Answering-42-2048.jpg)


The document provides an overview of deep learning applications in question answering (QA), detailing the author's academic and industrial background in natural language processing. It discusses the evolution of QA systems, the use of deep learning models such as CNNs and LSTMs, as well as various datasets and metrics used to evaluate QA performance. Additionally, it touches upon various approaches and techniques in answering sentence selection, the role of dependency trees, and advancements in LSTM models for improved accuracy in QA tasks.











































































![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)


