Download as PDF, PPTX




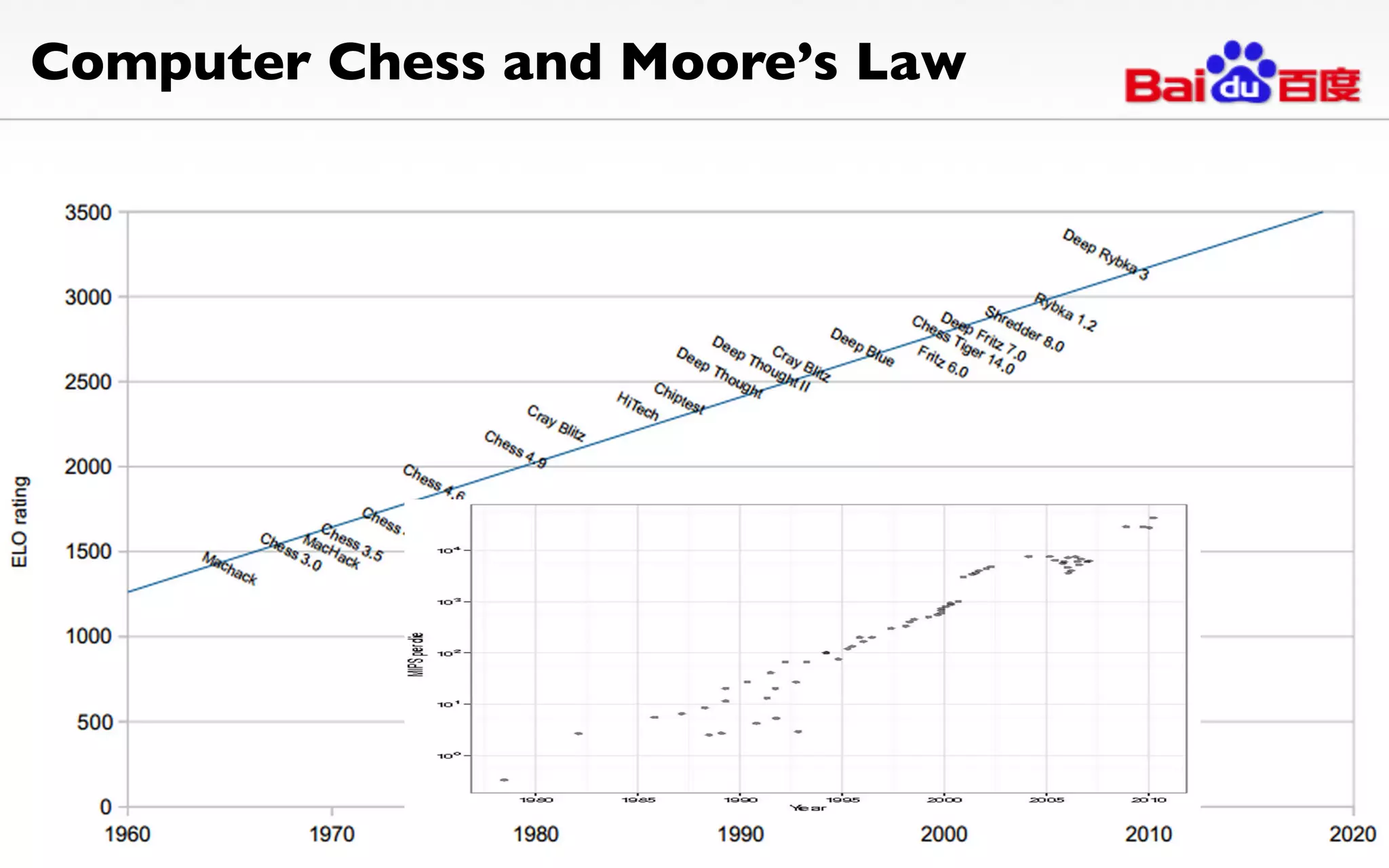

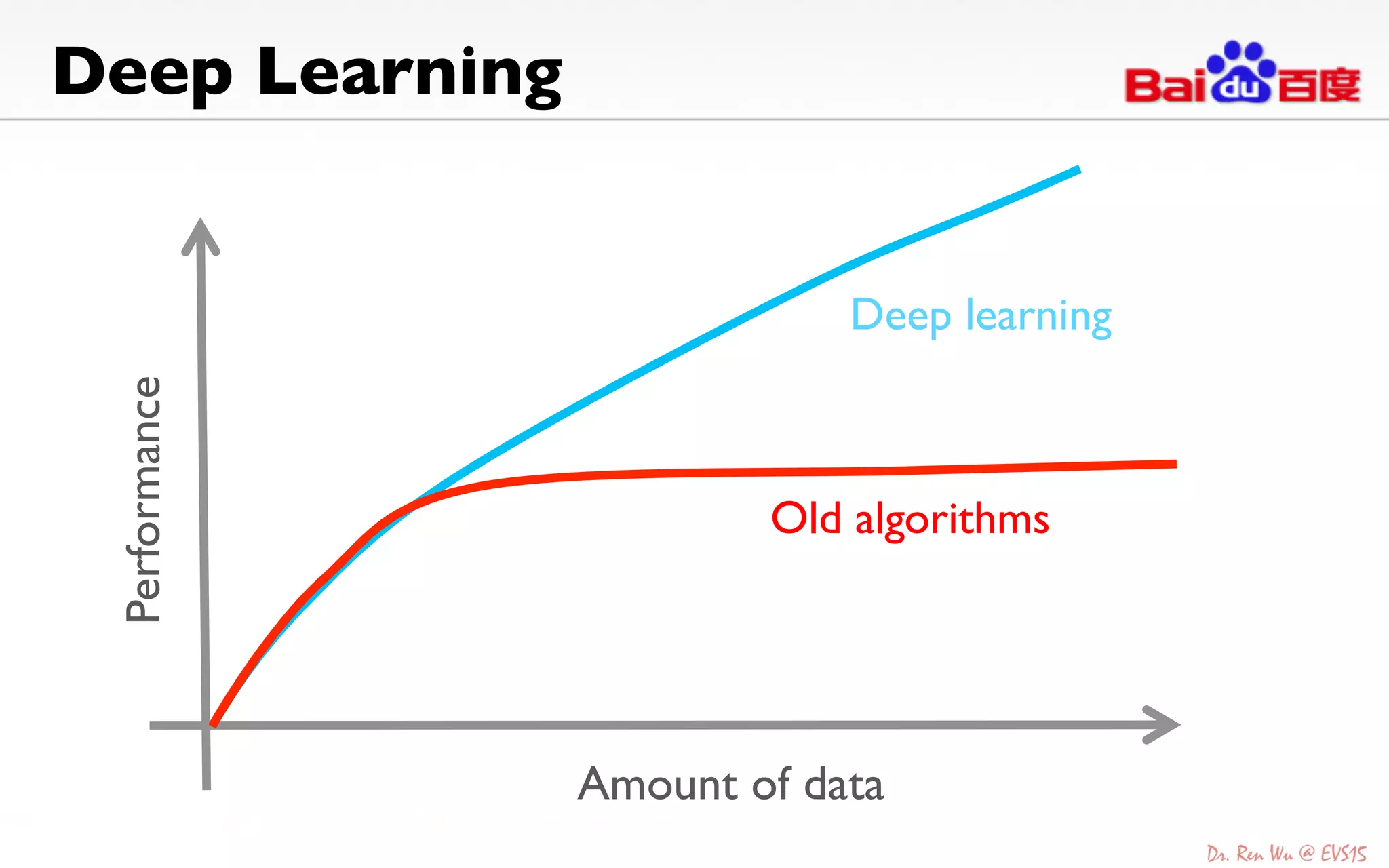
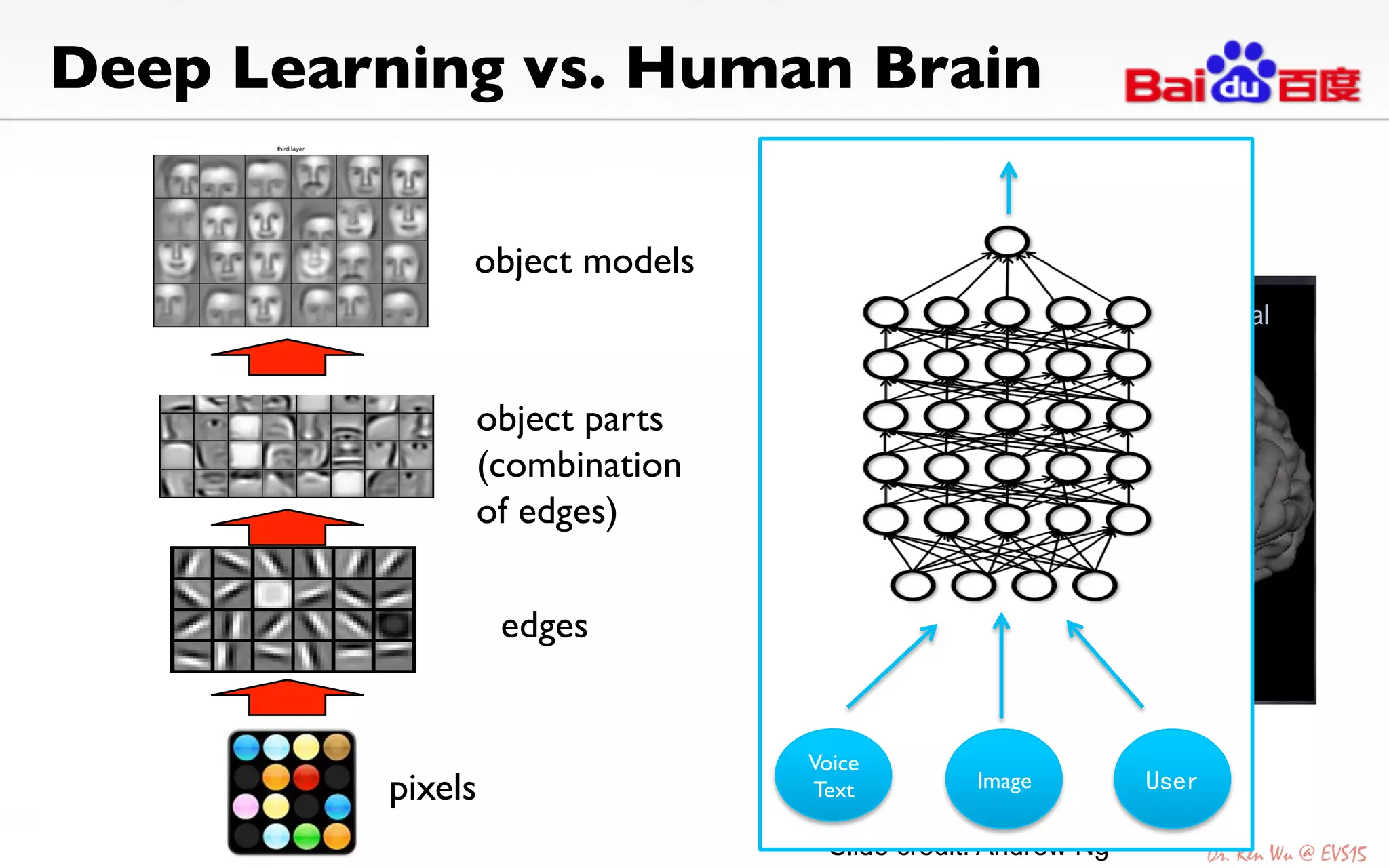
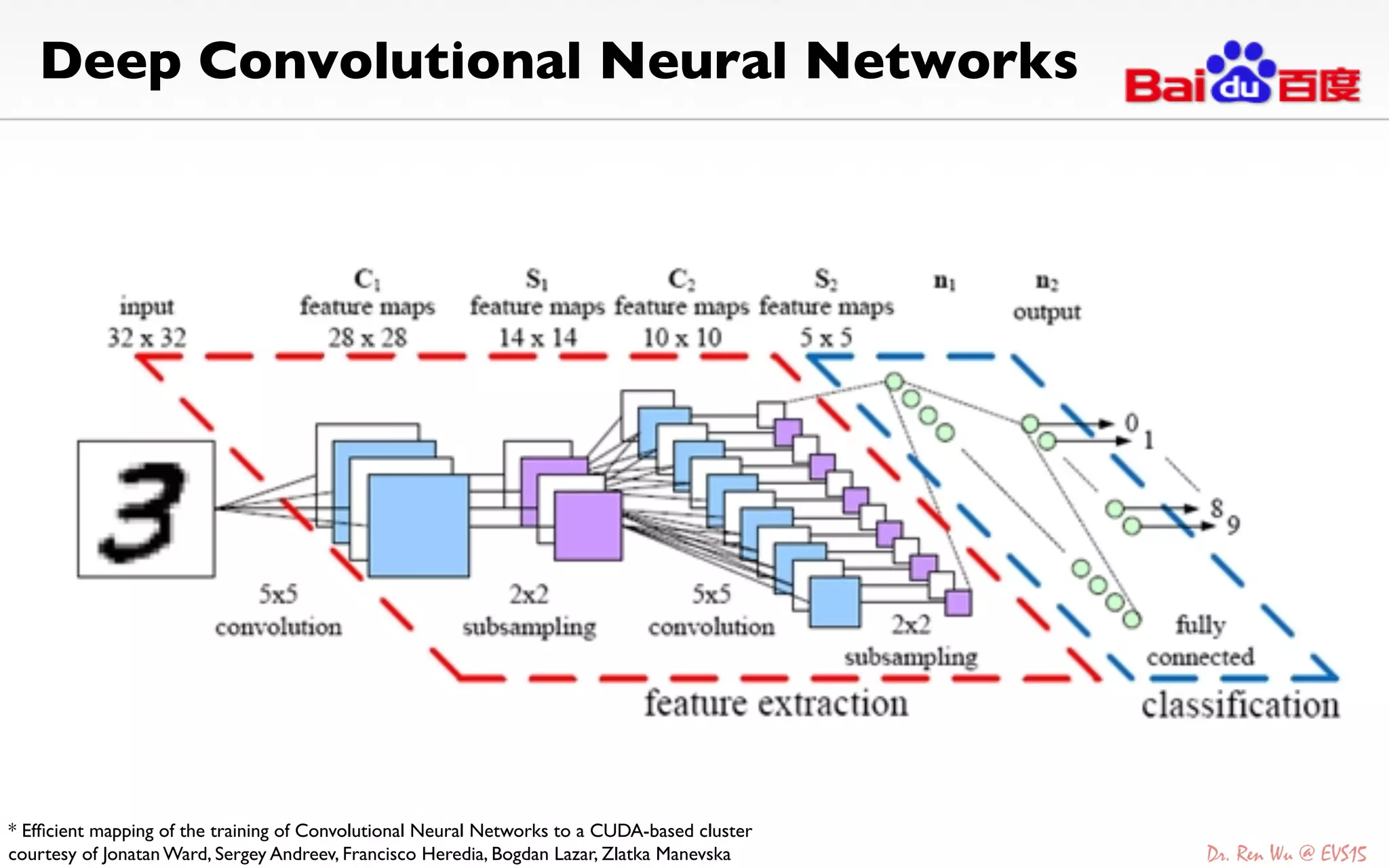


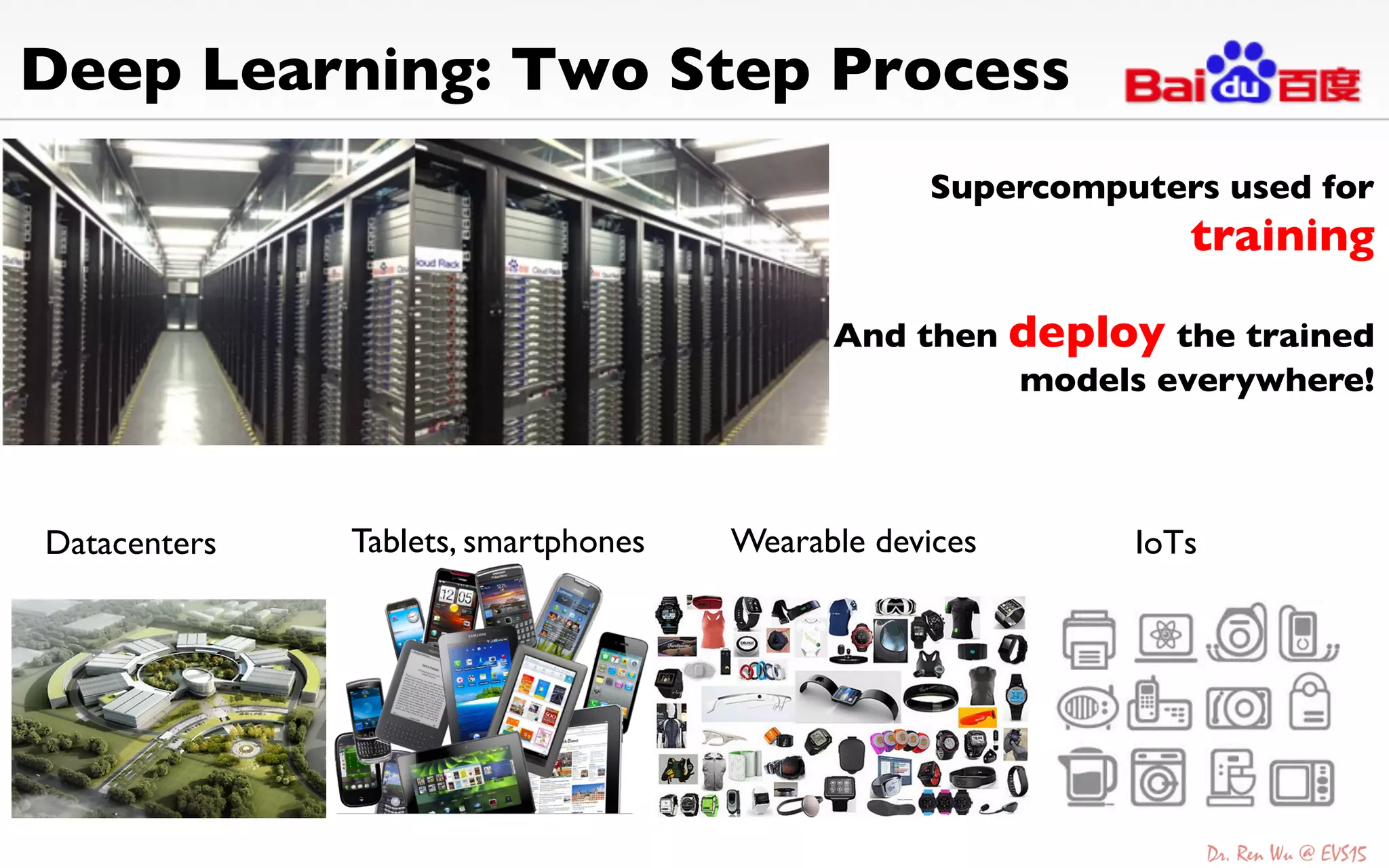





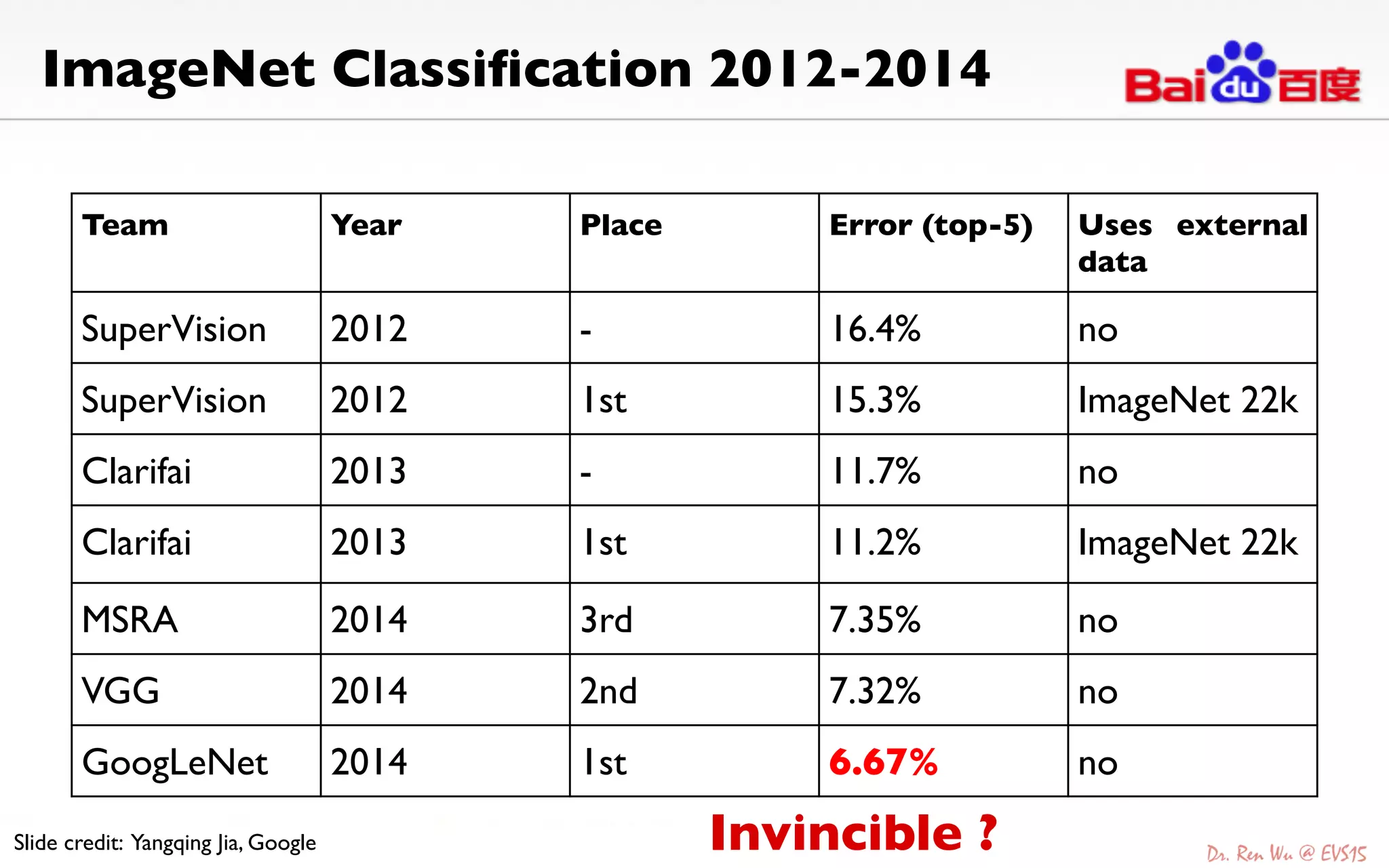
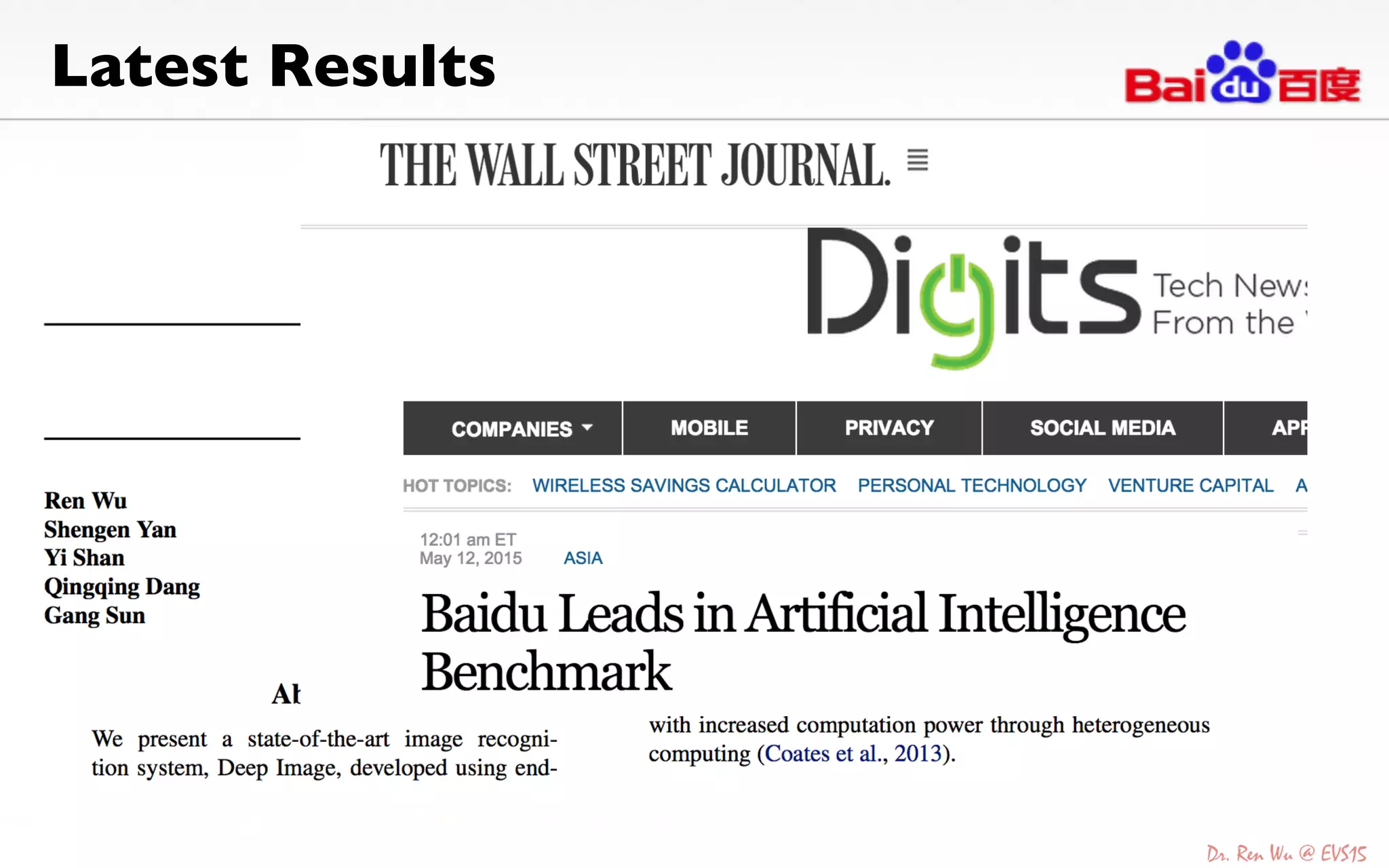
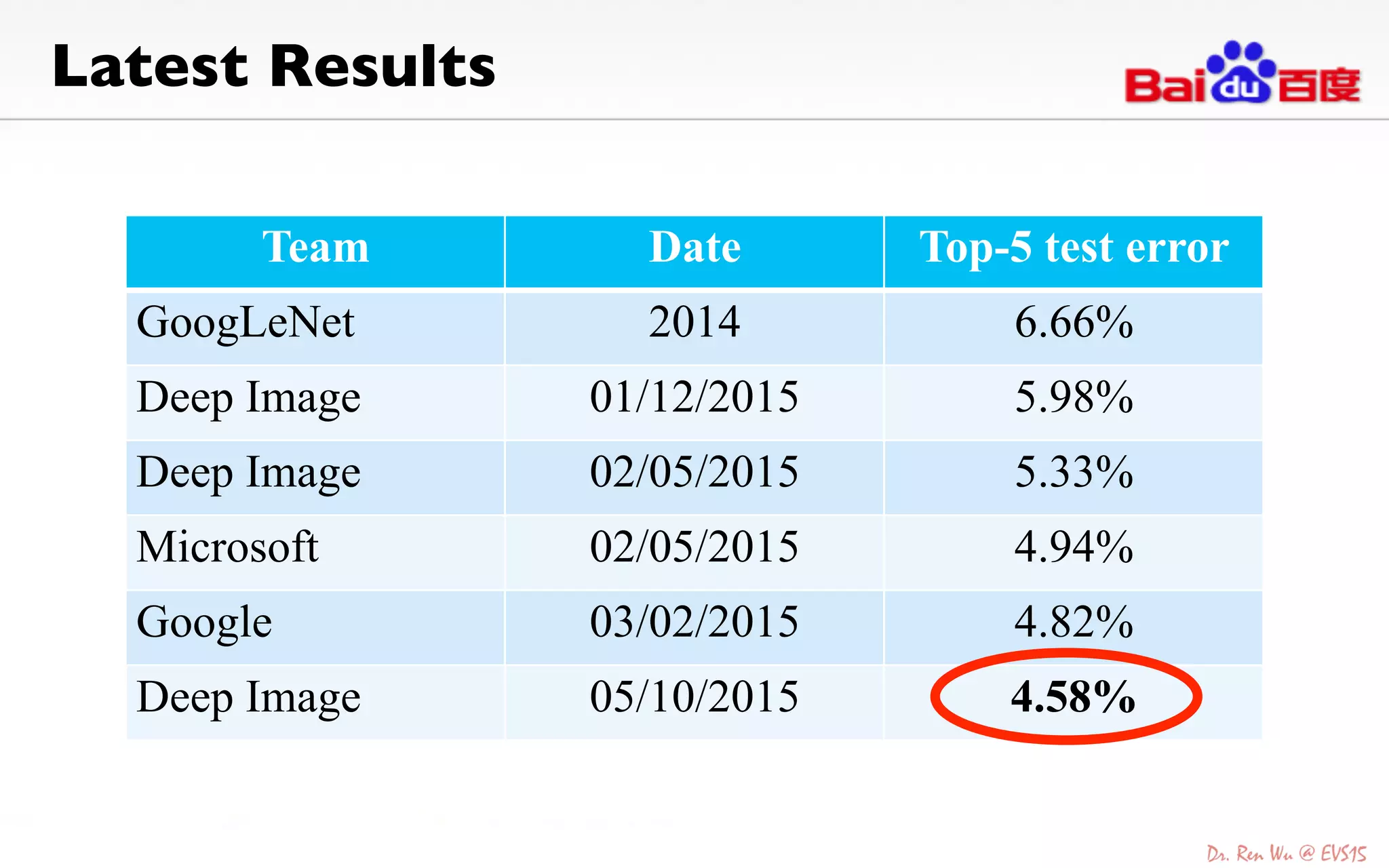




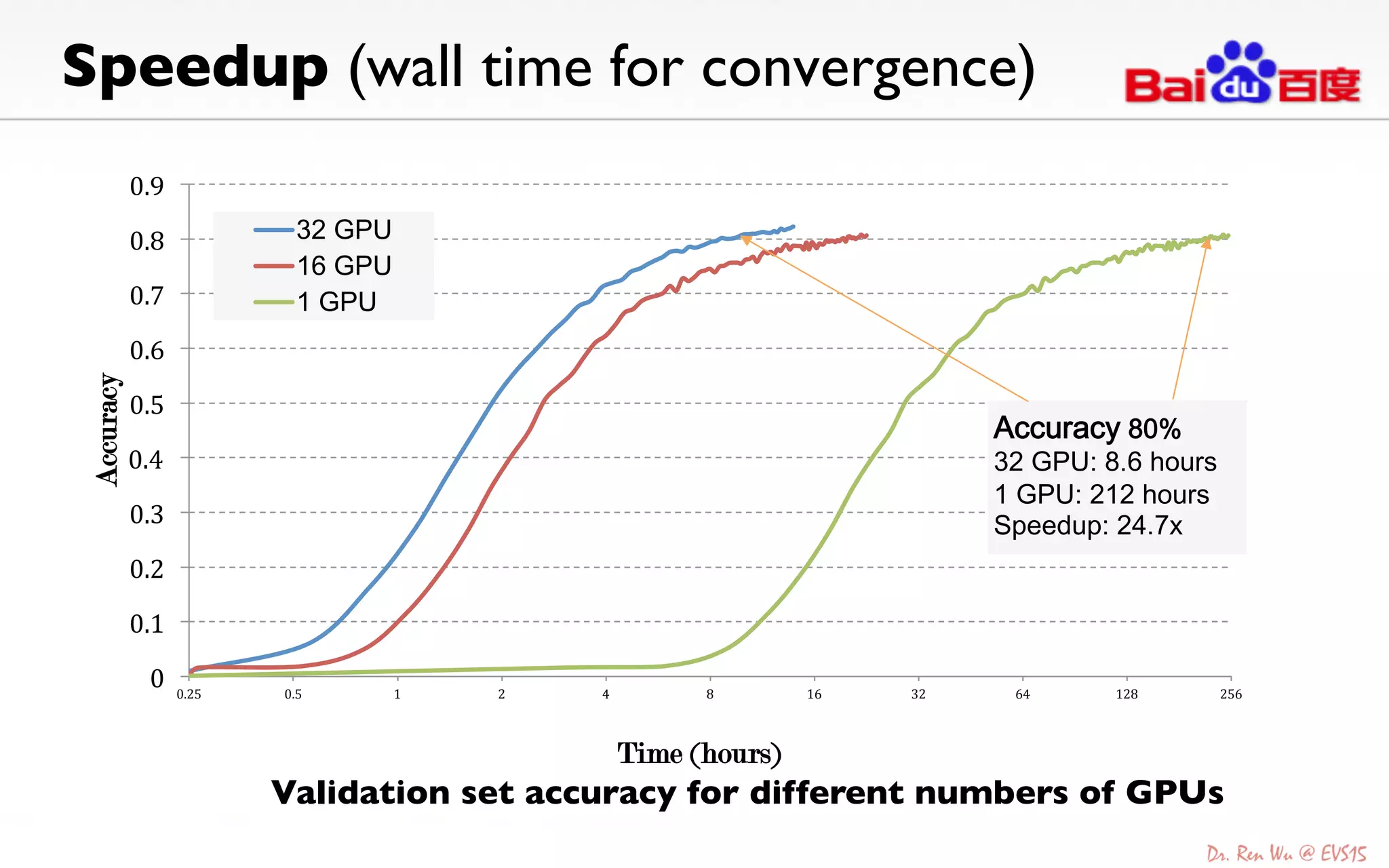



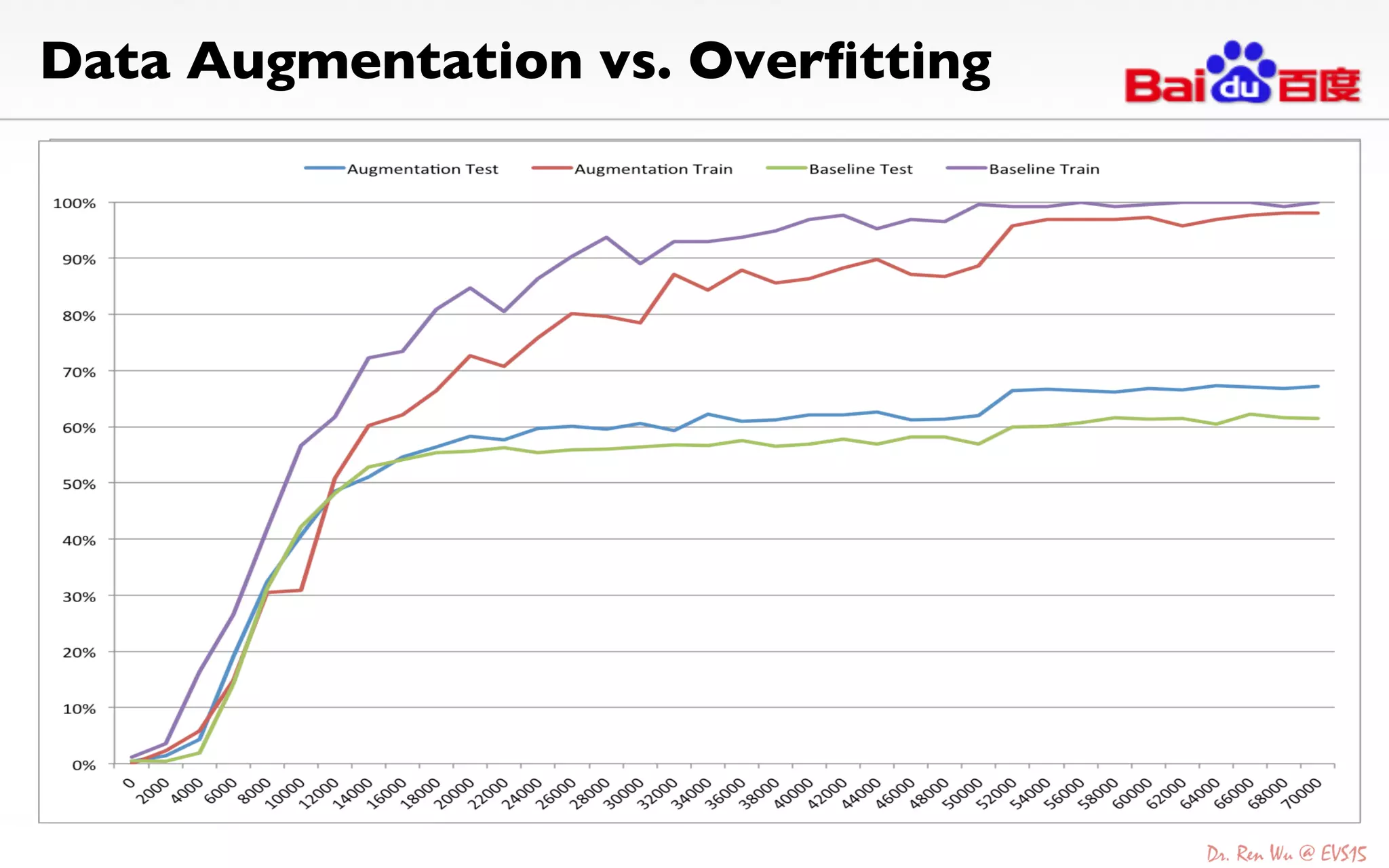




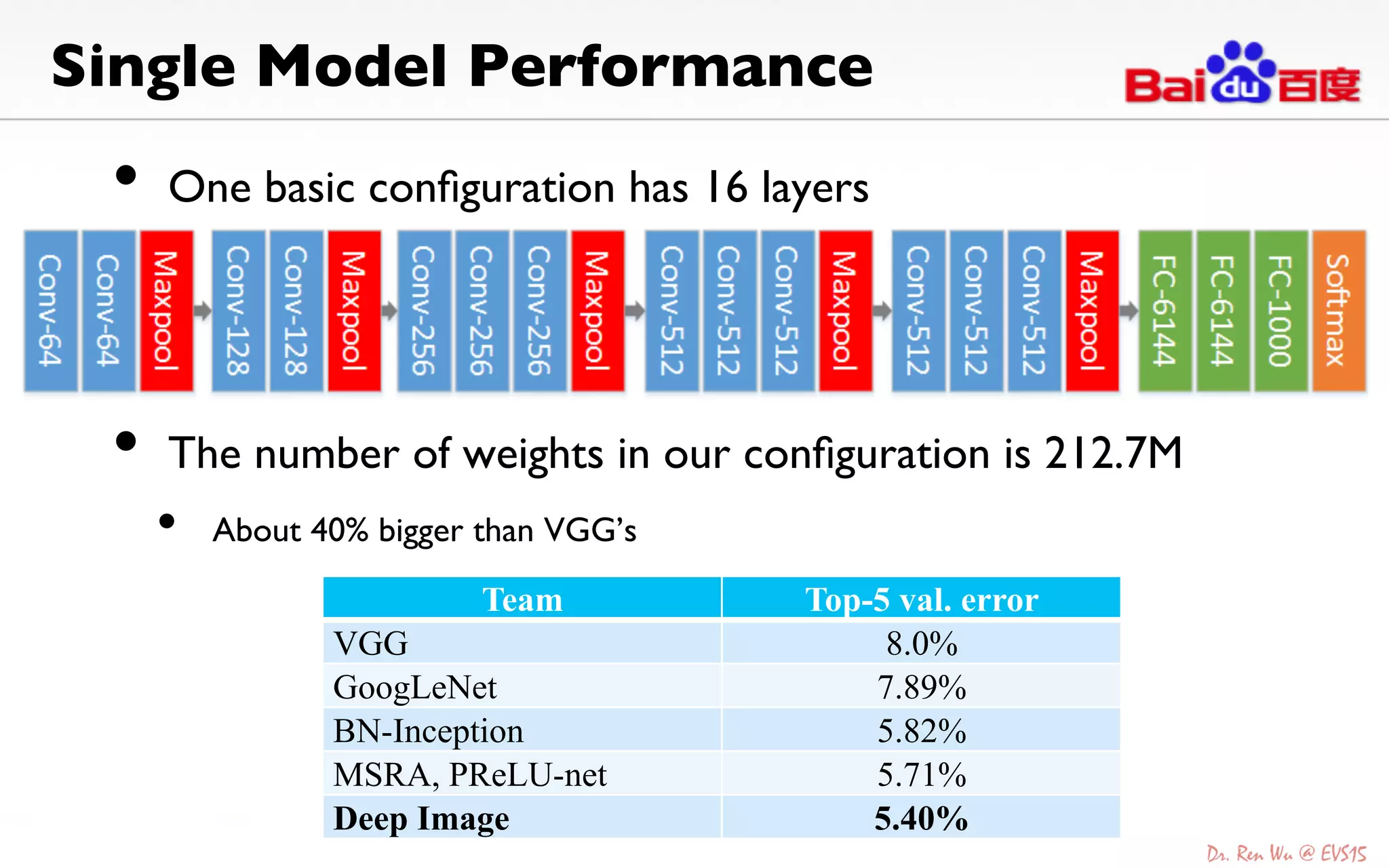




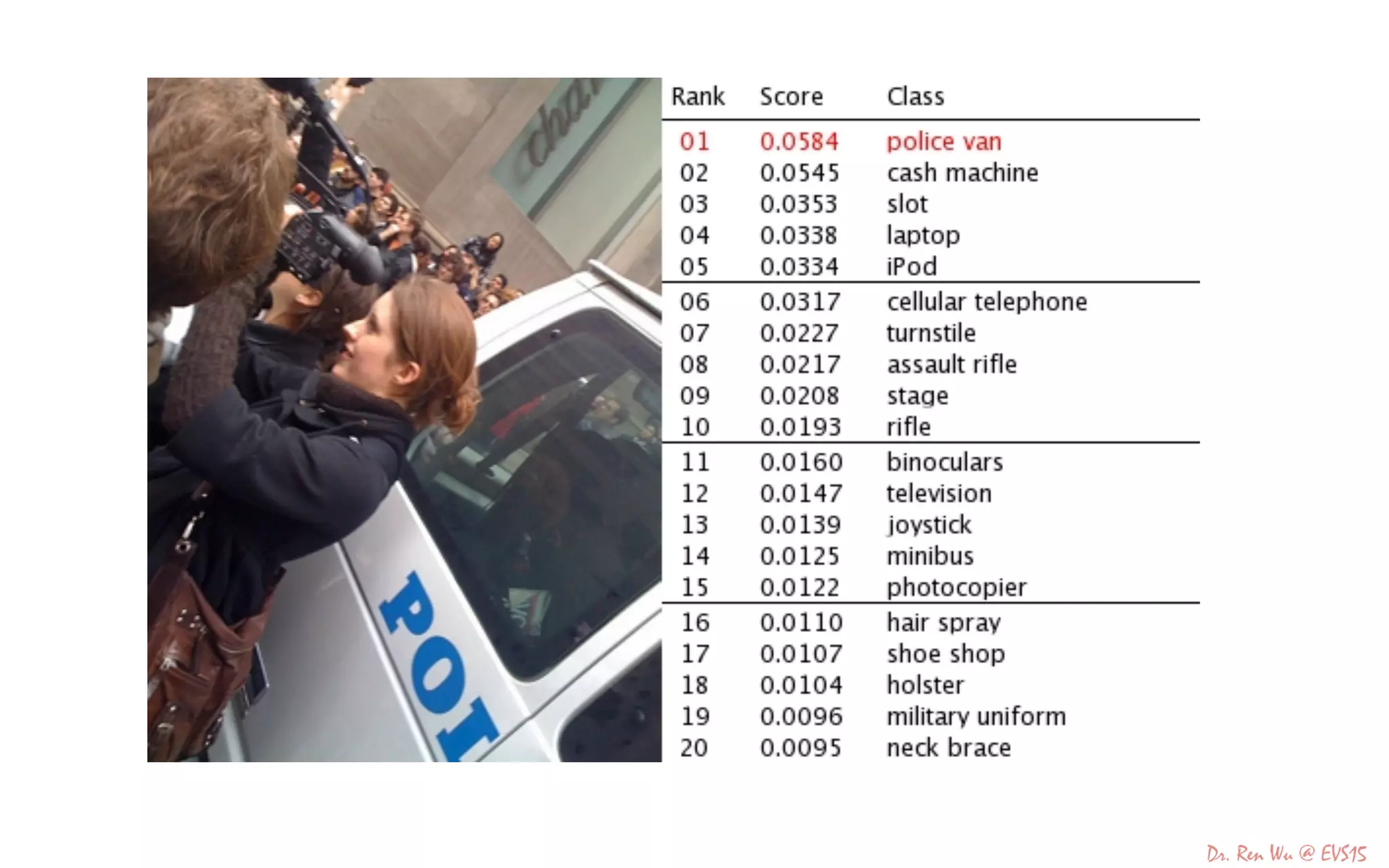




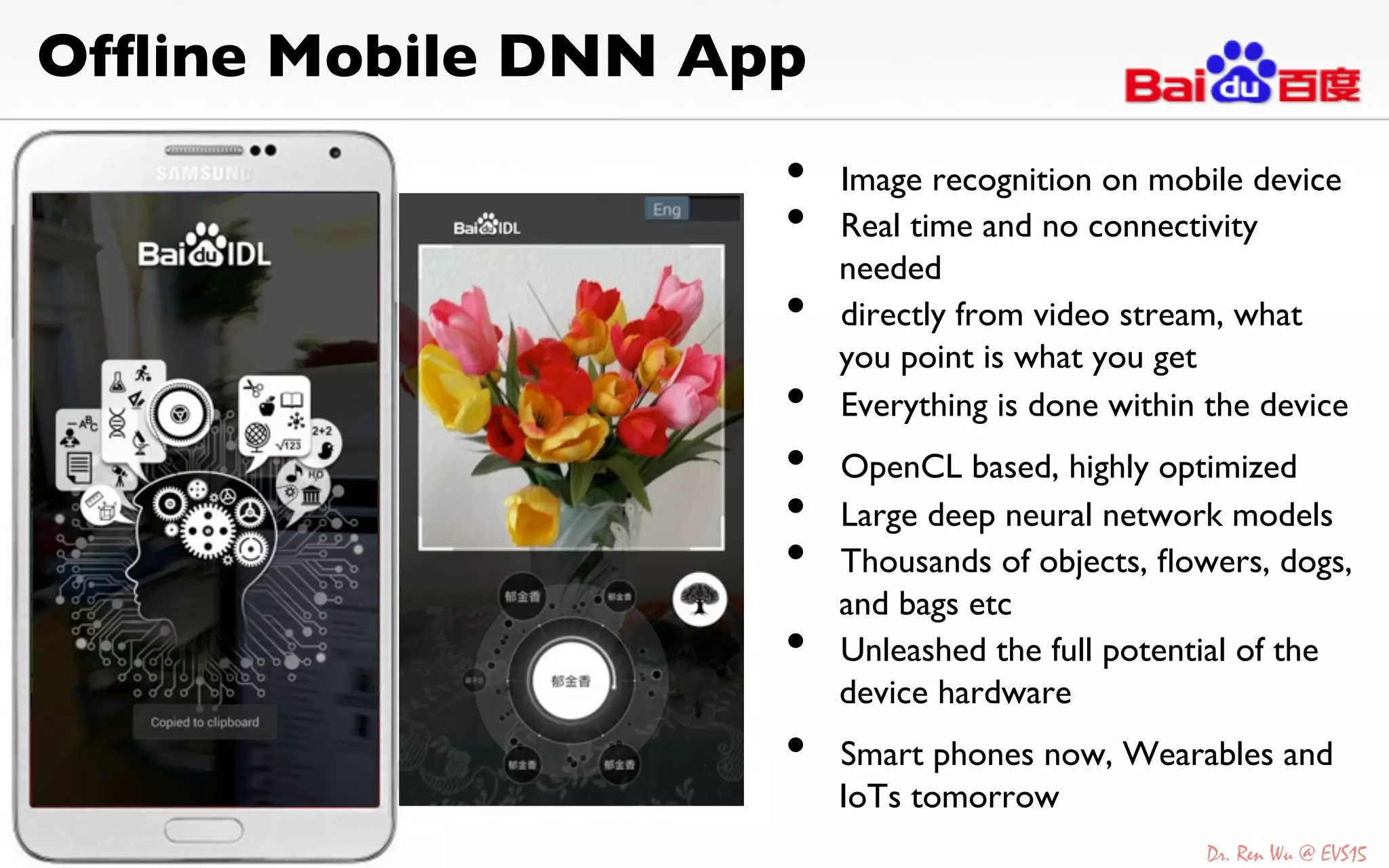
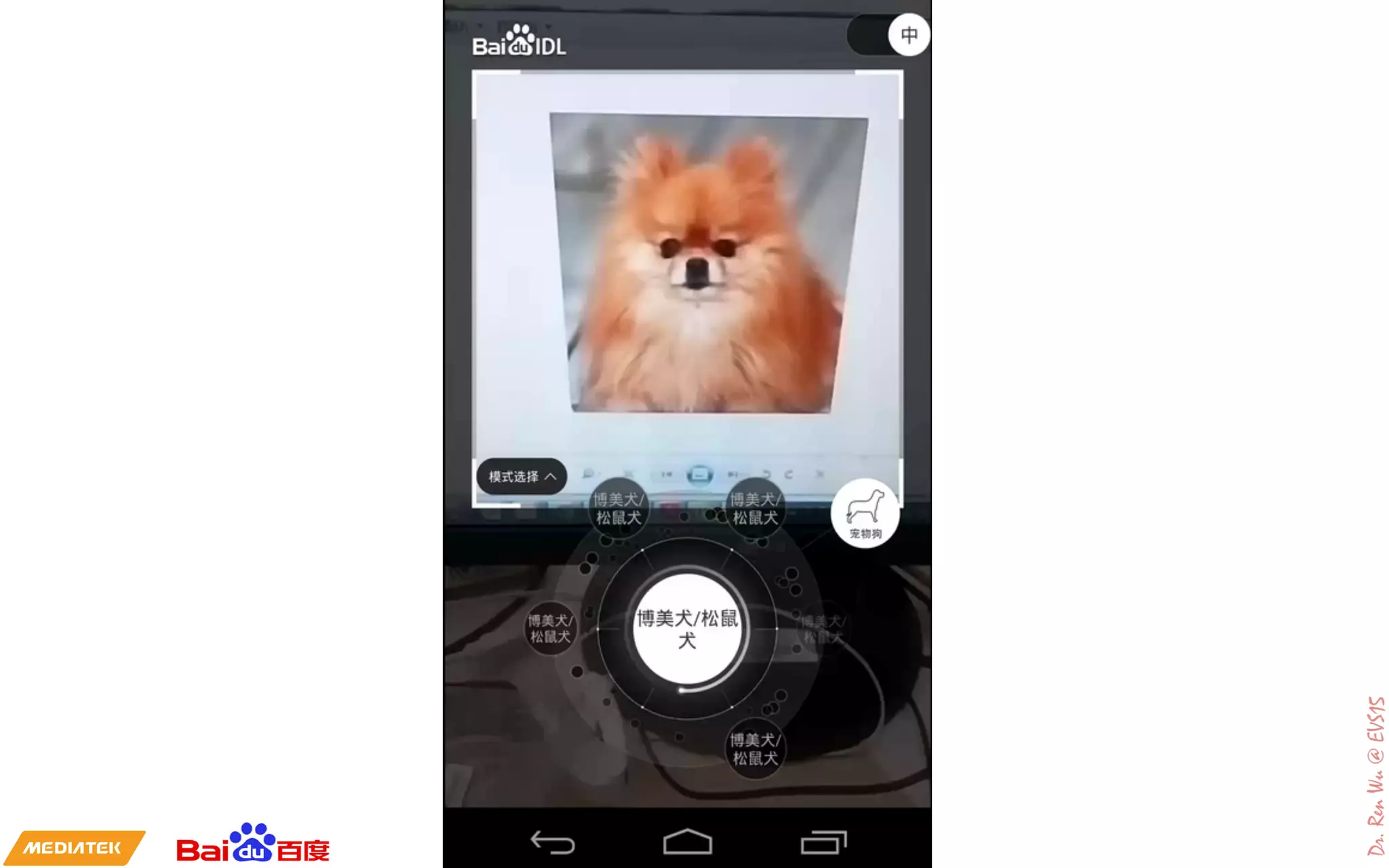
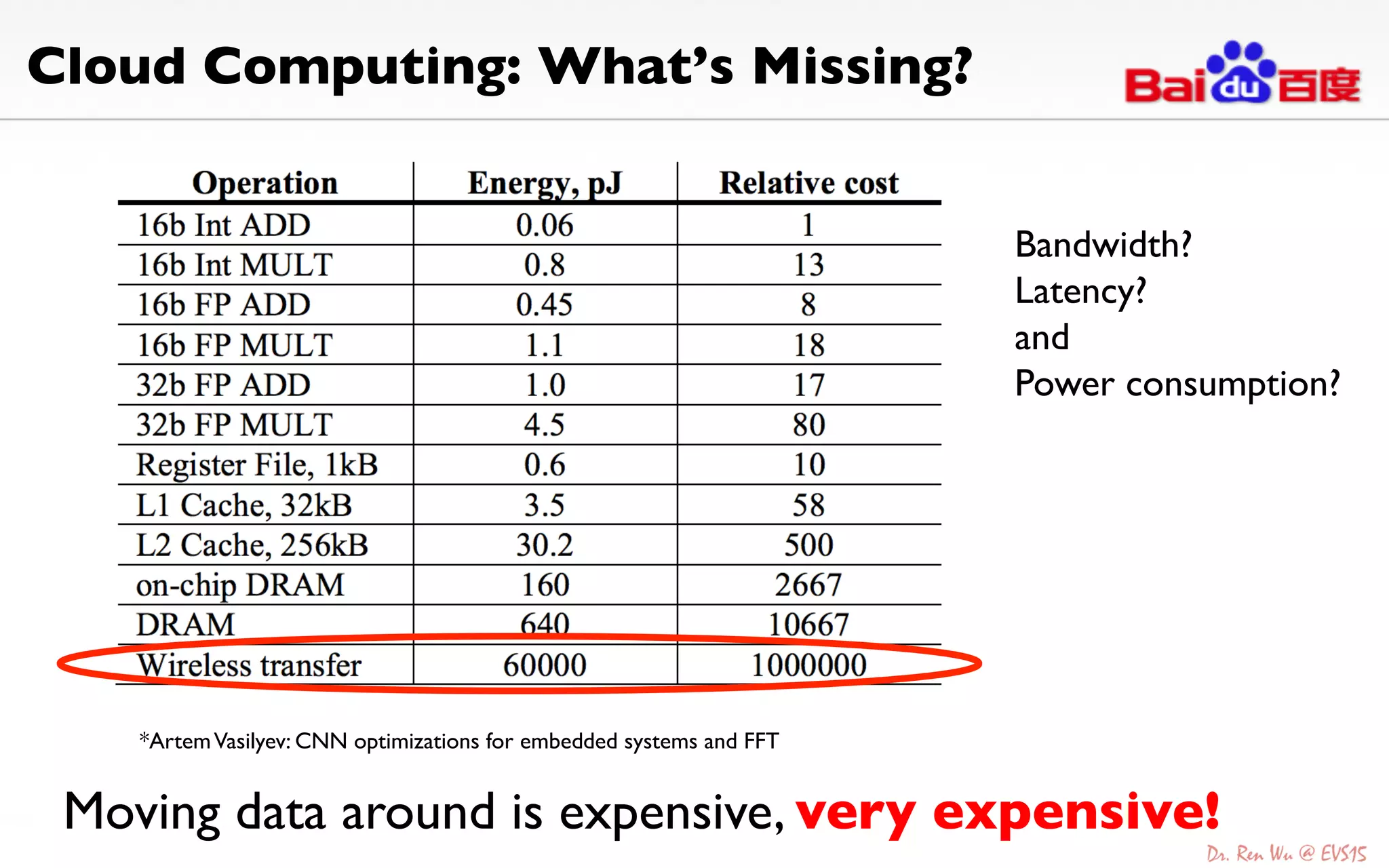

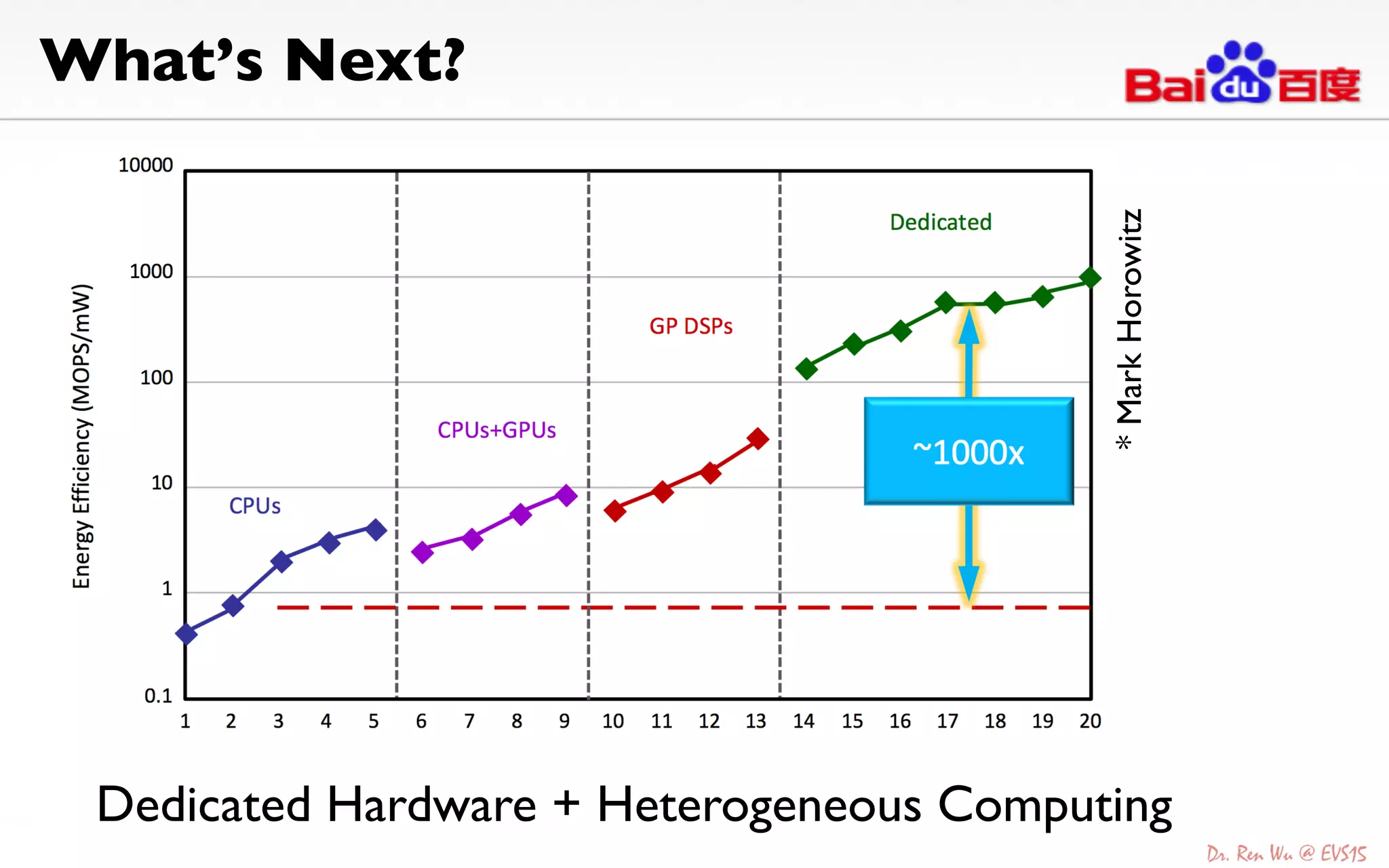



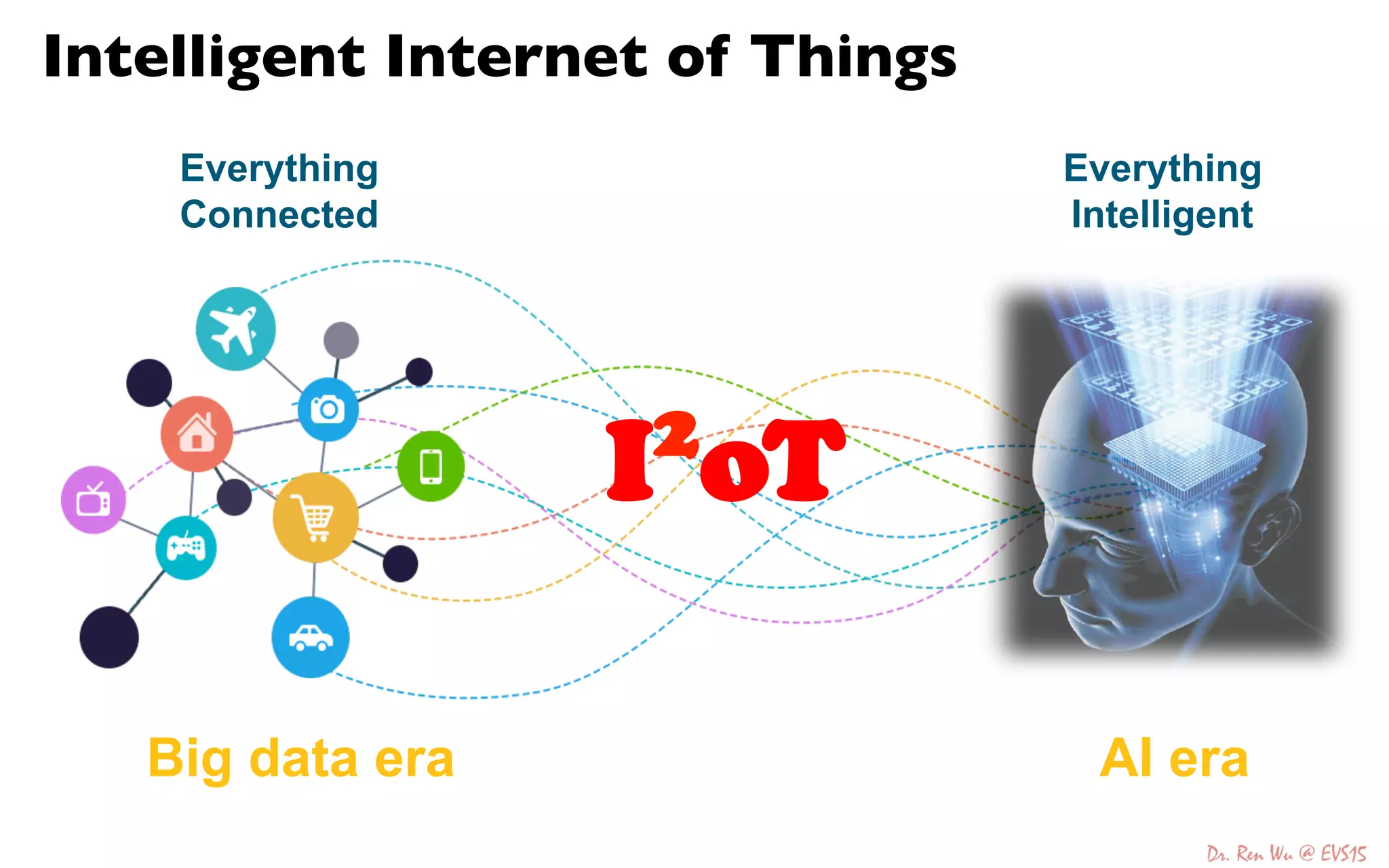


The document discusses advancements in deep learning and its integration into various technologies, highlighting the transformational impact on visual intelligence and data processing. It outlines the evolution of deep learning systems, including notable milestones such as the ImageNet challenges, and emphasizes the importance of big data and high-performance computing in developing intelligent solutions. Additionally, it covers the deployment of deep neural networks across diverse platforms like smartphones, wearables, and IoTs, underscoring the necessity for optimized hardware and efficient algorithms.










































































































