Download as PDF, PPTX
![[course site]
Optimizing deep
networks
Day 3 Lecture 3
Kevin McGuinness
kevin.mcguinness@dcu.ie
Research Fellow
Insight Centre for Data Analytics
Dublin City University](https://image.slidesharecdn.com/dlcvd3l3optimization-160803161325/85/Deep-Learning-for-Computer-Vision-Optimization-UPC-2016-1-320.jpg)
![[course site]
Optimizing deep
networks
Day 3 Lecture 3
Kevin McGuinness
kevin.mcguinness@dcu.ie
Research Fellow
Insight Centre for Data Analytics
Dublin City University](https://image.slidesharecdn.com/dlcvd3l3optimization-160803161325/75/Deep-Learning-for-Computer-Vision-Optimization-UPC-2016-1-2048.jpg)
![Convex optimization
A function is convex if for all α ∈ [0,1]:
Examples
● Quadratics
● 2-norms
Properties
● Local minimum is global minimum
x
f(x)
Tangent
line
2](https://image.slidesharecdn.com/dlcvd3l3optimization-160803161325/85/Deep-Learning-for-Computer-Vision-Optimization-UPC-2016-2-320.jpg)
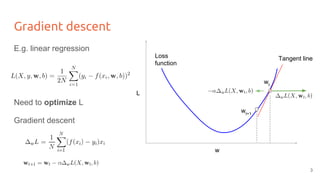

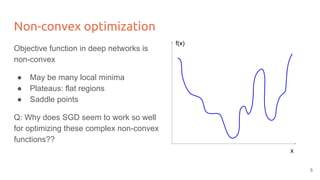
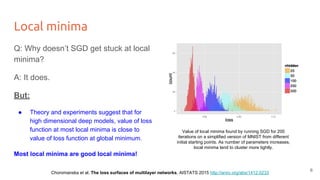

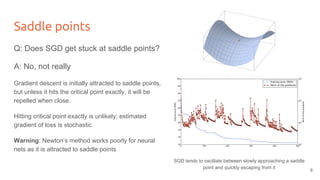
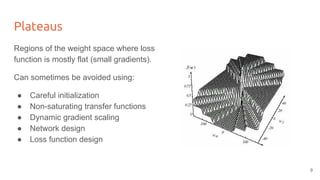

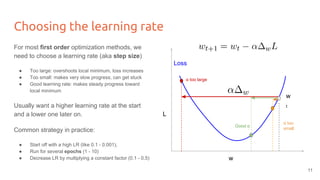

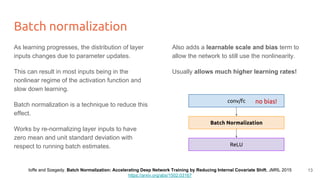


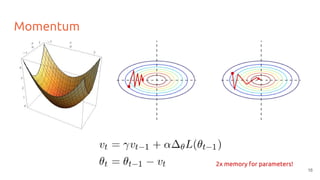




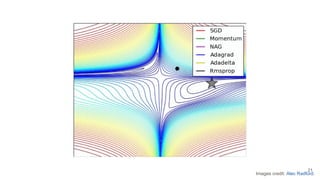
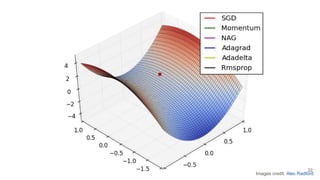


The lecture discusses optimizing deep networks using stochastic gradient descent (SGD) and addresses challenges such as non-convex optimization, local minima, and saddle points. It highlights the importance of learning rate selection, weight initialization, and techniques like batch normalization to improve convergence. Various extensions of SGD, including momentum and Adam, are presented to enhance the optimization process.






















































































