Download as PDF, PPTX
![Day 1 Lecture 3
Deep Networks
Elisa Sayrol
[course site]](https://image.slidesharecdn.com/dlcvd1l3deepnetworks-160722104854/85/Deep-Learning-for-Computer-Vision-Deep-Networks-UPC-2016-1-320.jpg)
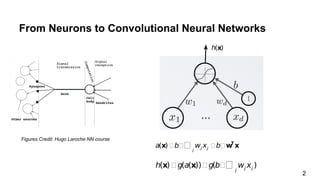
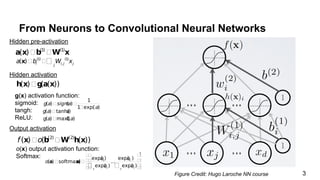
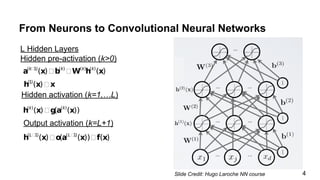


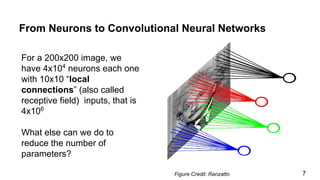

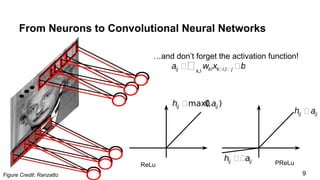
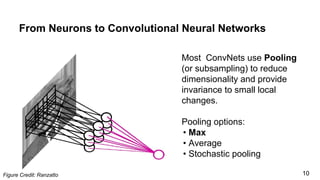





The document discusses the architecture and functioning of Convolutional Neural Networks (CNNs), emphasizing the layers involved, such as hidden, output, and convolutional layers. It describes techniques for reducing the number of parameters, including the use of local connections, translation invariance, pooling, padding, and stride. The examples provided reference specific architectures, such as lenet-5, to illustrate how these concepts are applied in practice.






















































































