Downloaded 99 times











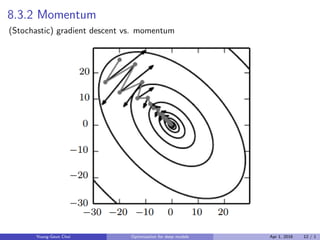














Chapter 8 of Goodfellow et al. (2016) discusses optimization techniques for training deep models, highlighting the distinctions between learning and pure optimization, and detailing various algorithms like stochastic gradient descent (SGD), momentum, and adaptive methods such as Adam. It tackles challenges such as ill-conditioning, local minima, and issues specific to neural networks, like the vanishing and exploding gradient problems. The chapter also outlines strategies for parameter initialization and the importance of batch normalization in improving the training process.



































































