Download as PDF, PPTX
![Day 1 Lecture 4
Backward Propagation
Elisa Sayrol
[course site]](https://image.slidesharecdn.com/dlcvd1l4backpropagation-160722105109/75/Deep-Learning-for-Computer-Vision-Backward-Propagation-UPC-2016-1-2048.jpg)

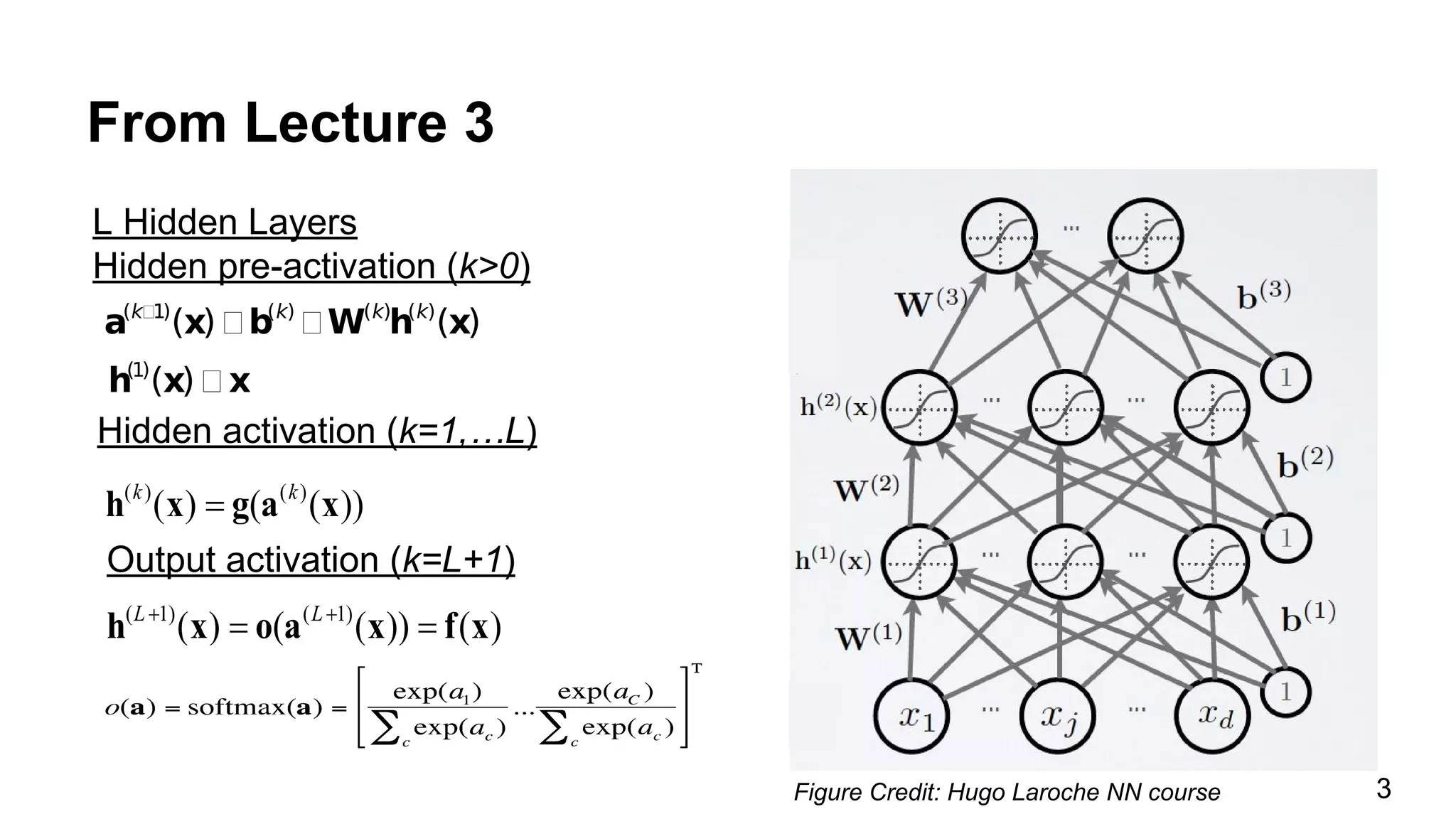

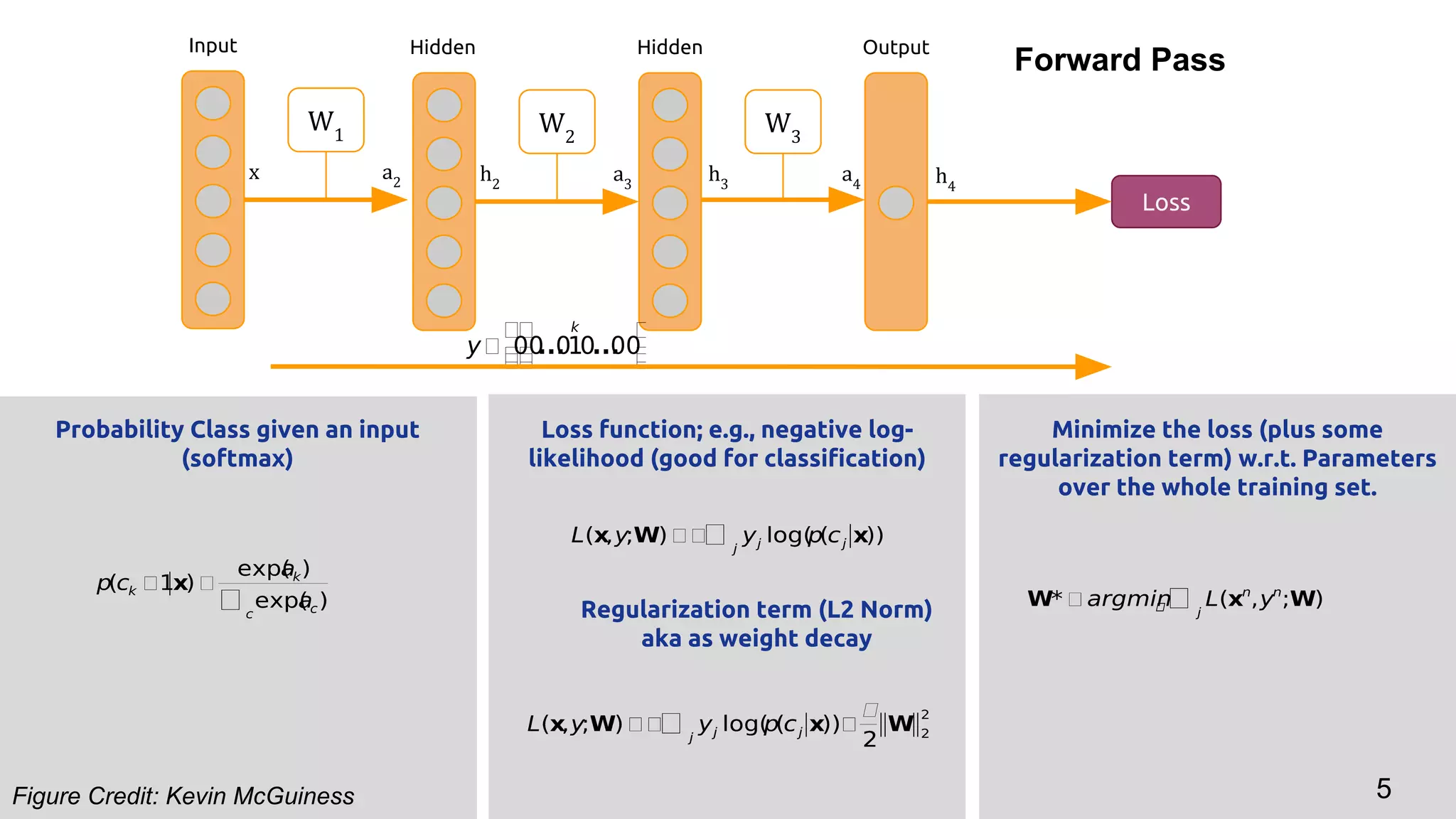

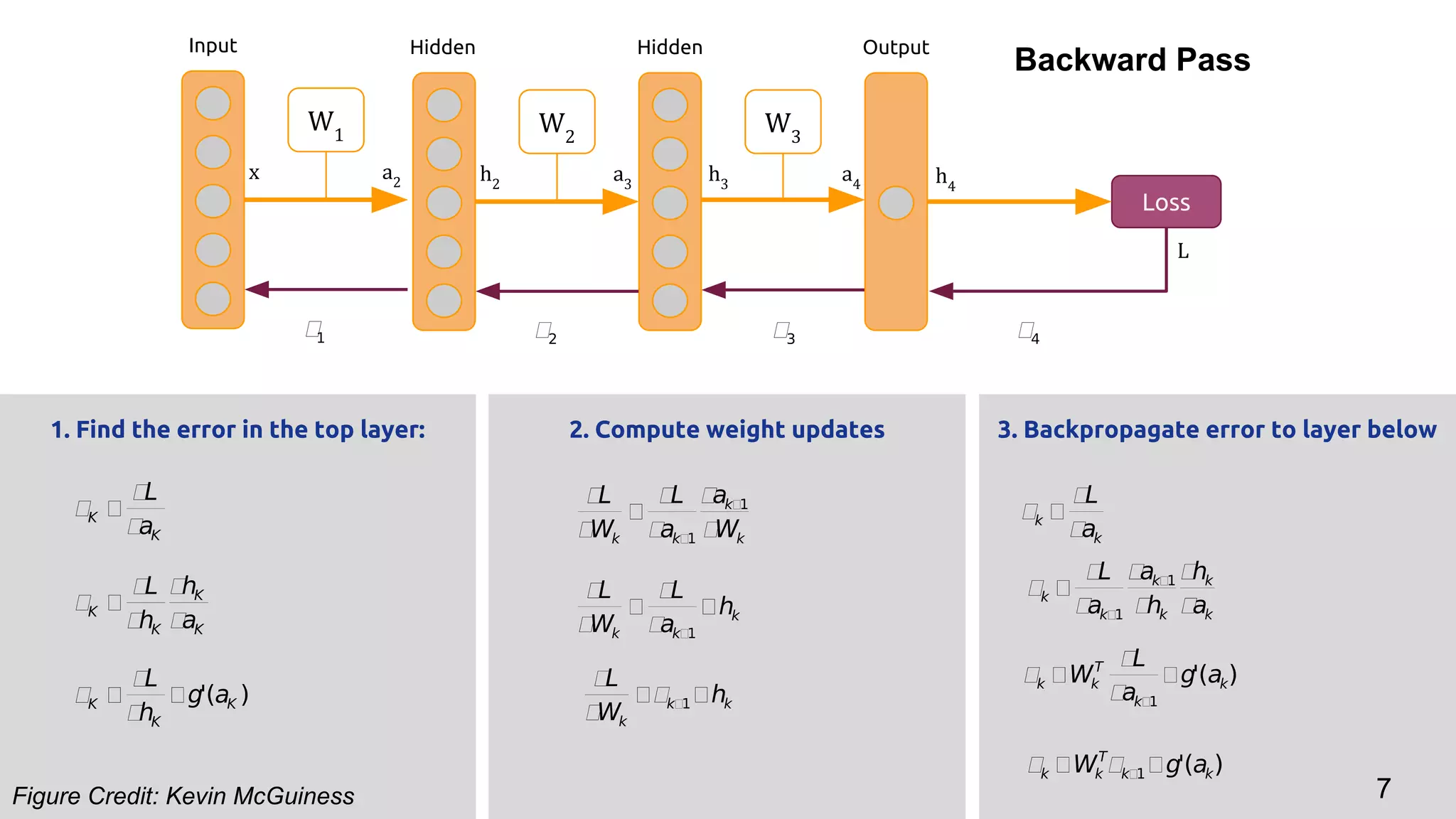


The document discusses backpropagation and optimization techniques in neural networks, emphasizing the use of supervised and unsupervised learning methods to train models effectively. It details the backpropagation algorithm's functionality, which involves minimizing a loss function using stochastic gradient descent and its variants. Additionally, it illustrates how to compute gradients iteratively through the network layers to improve parameter fitting.






















































































