Downloaded 17 times







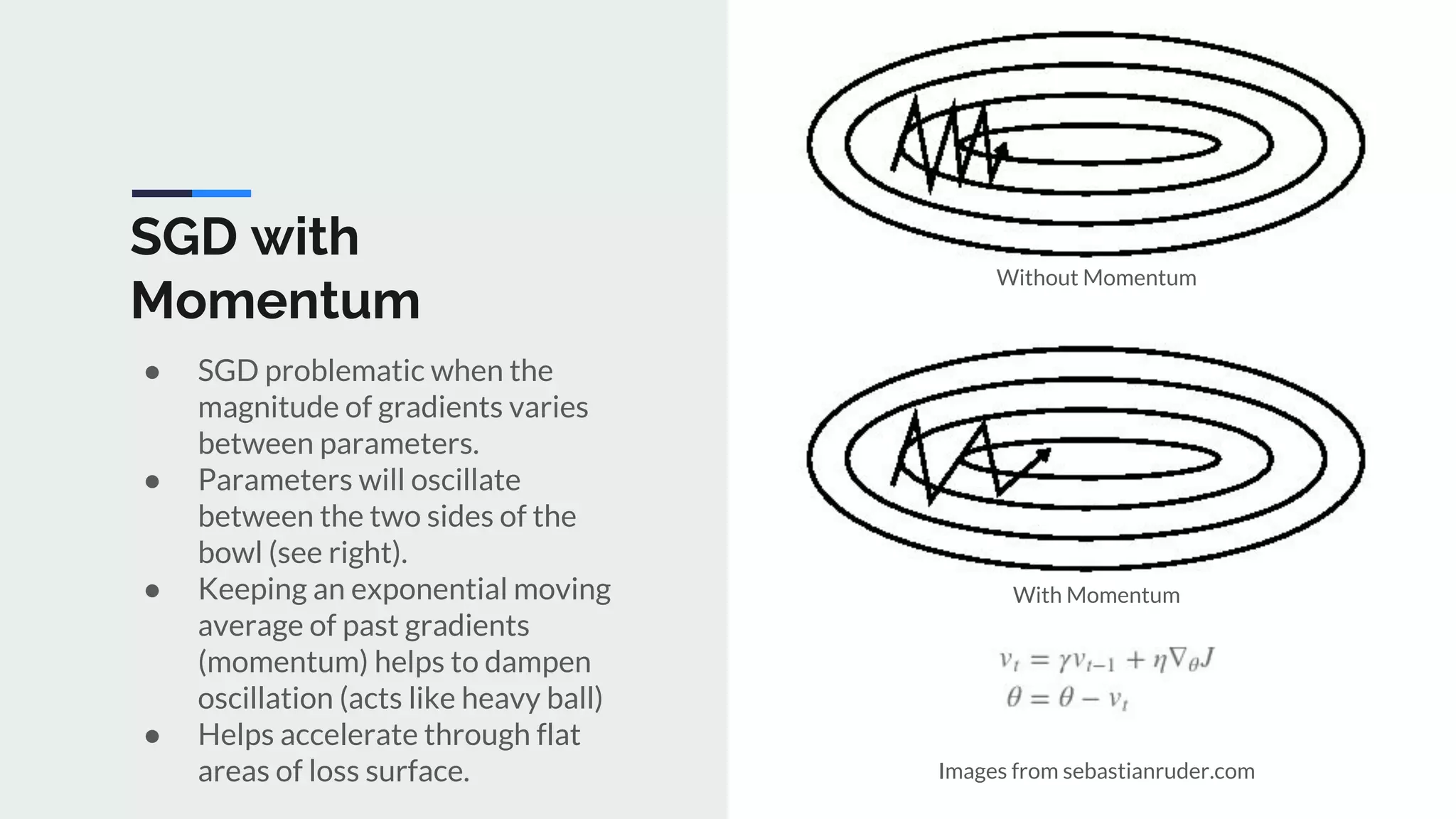
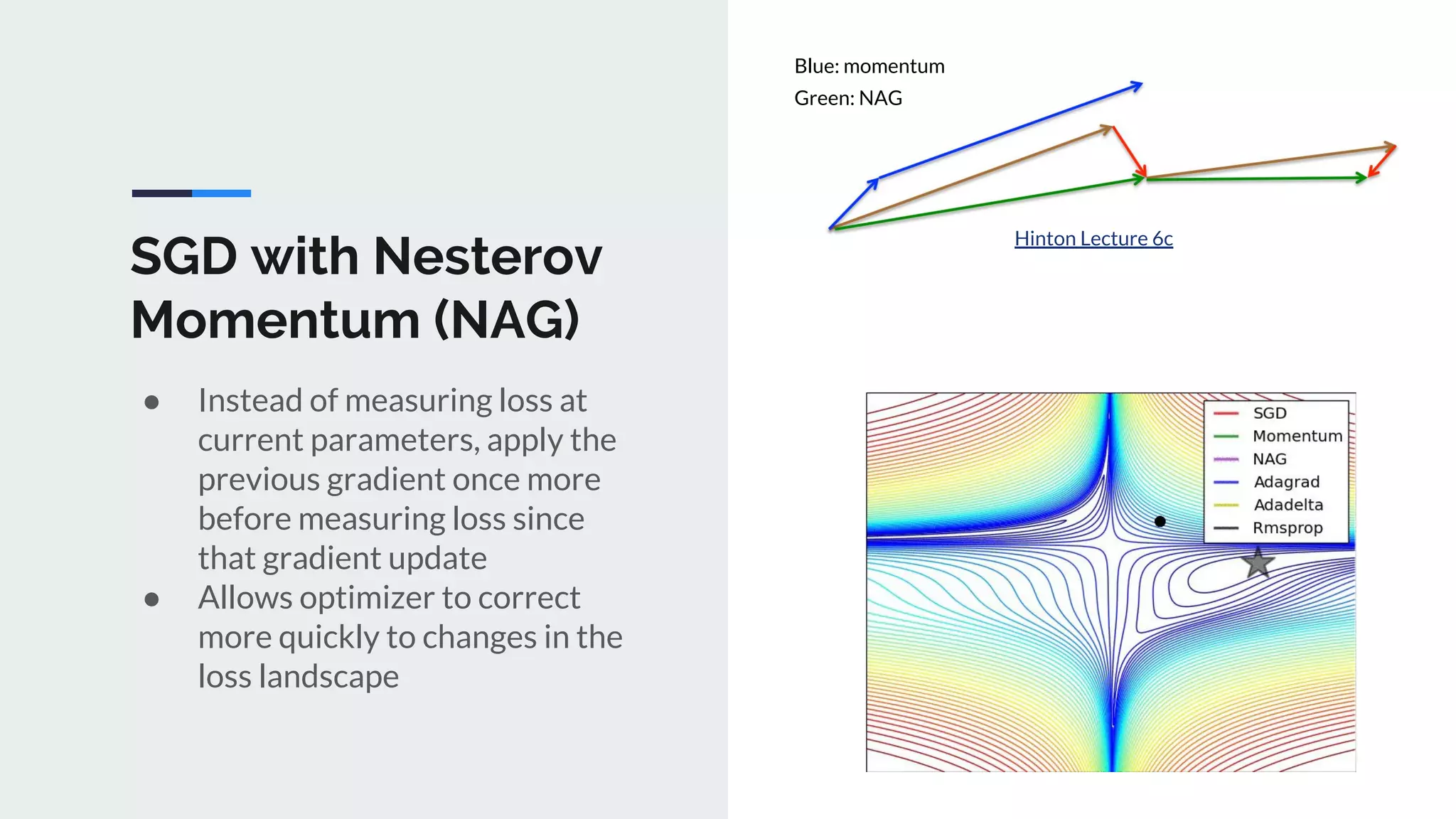

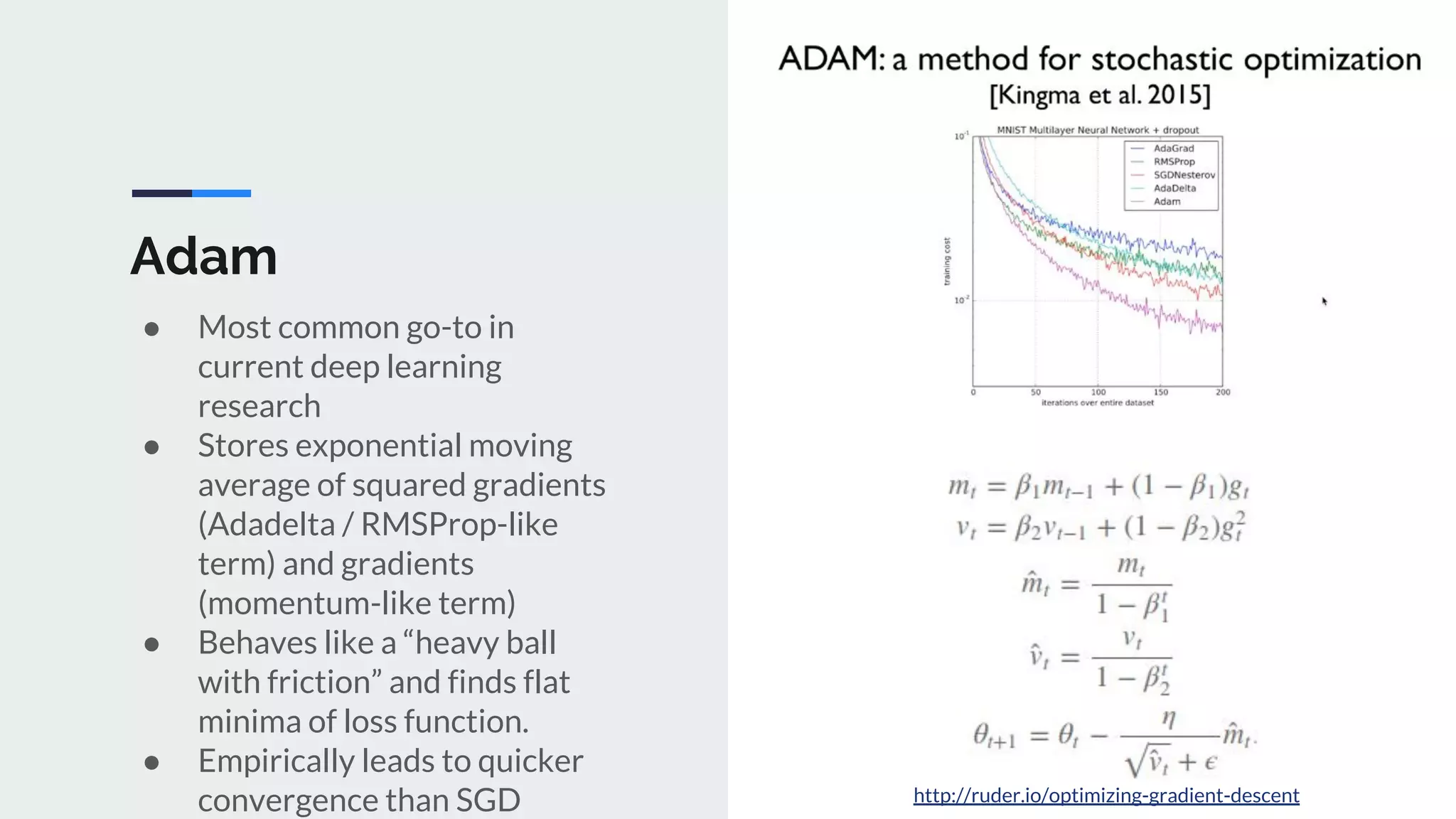


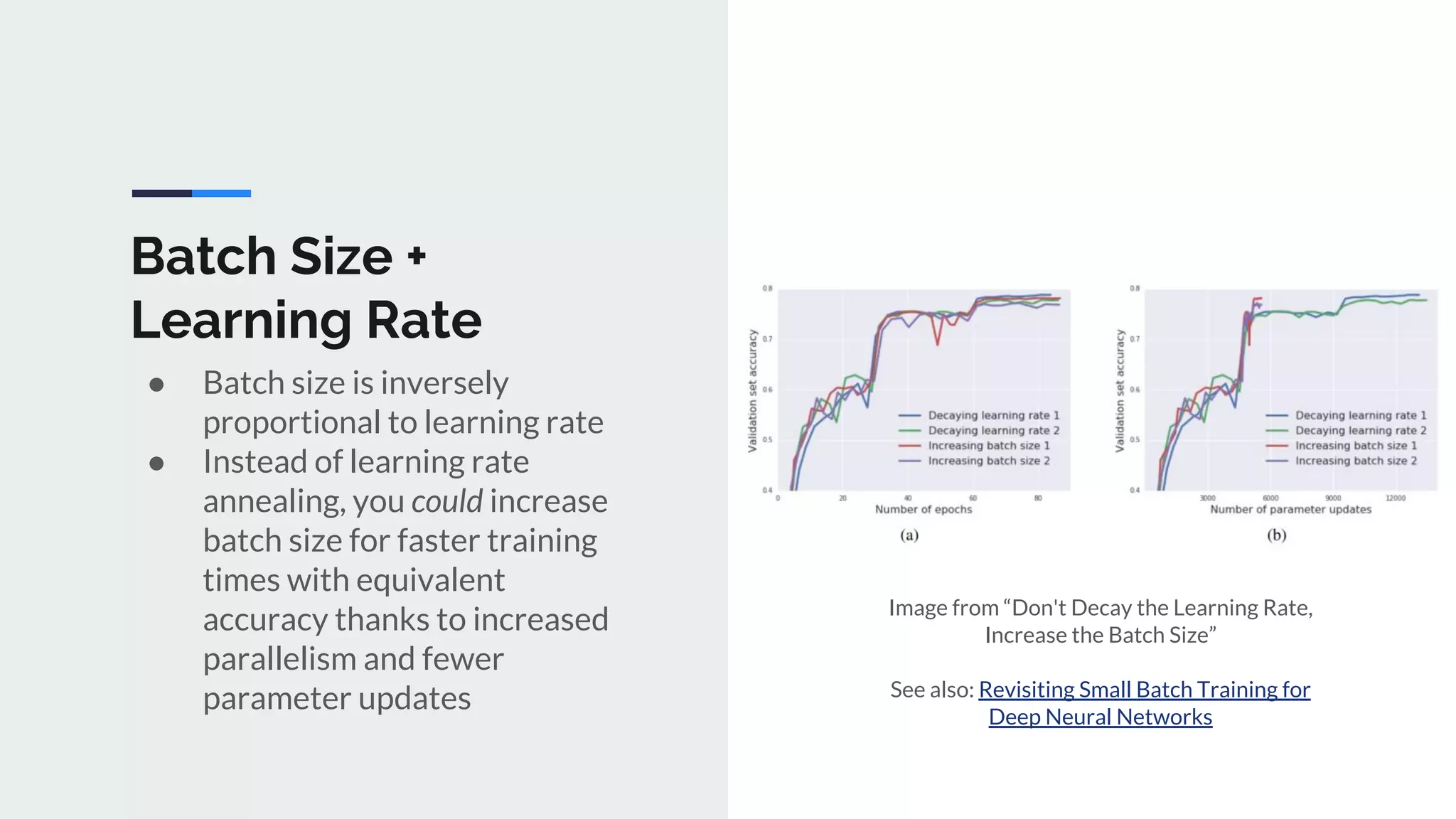
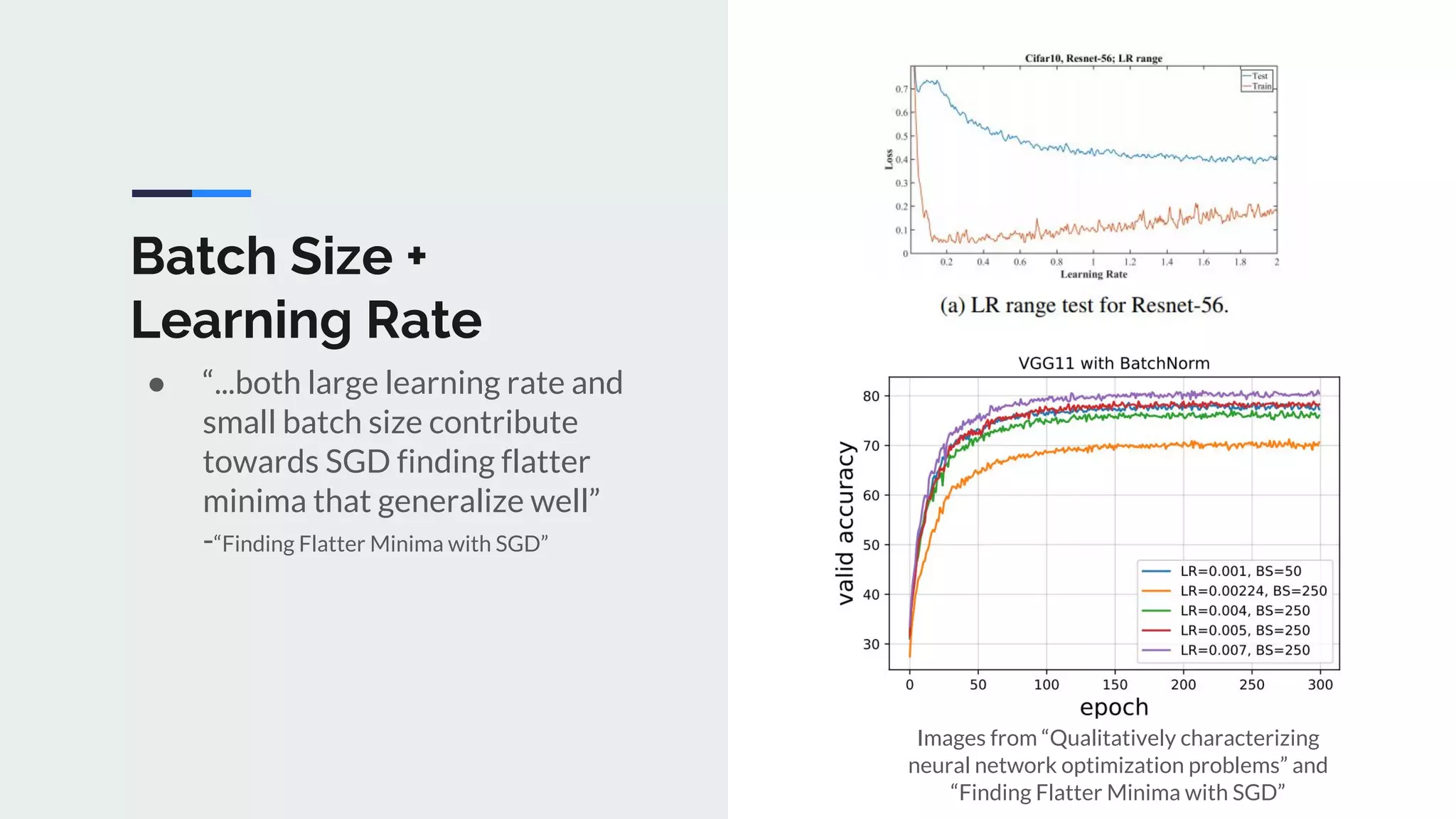
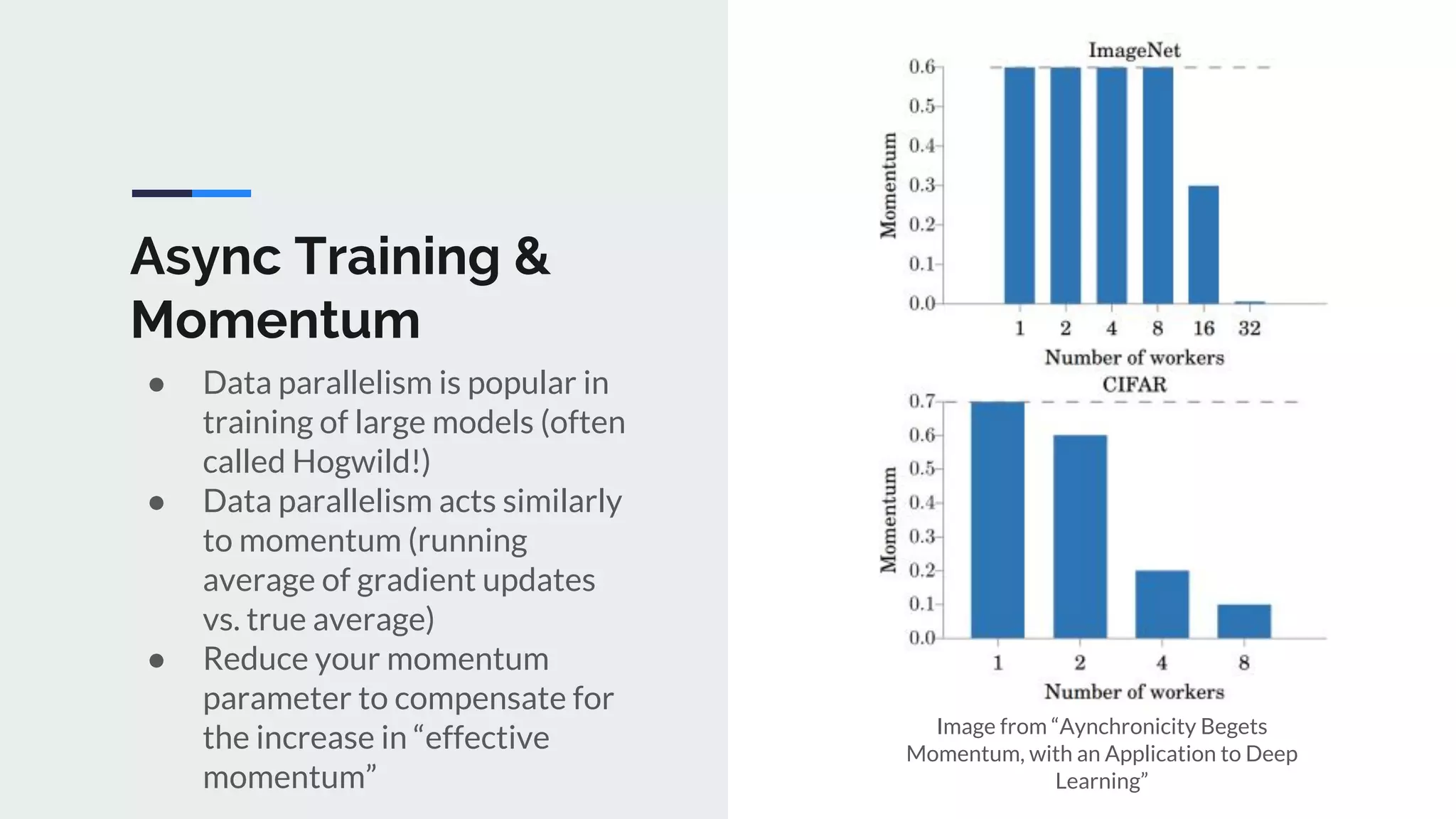
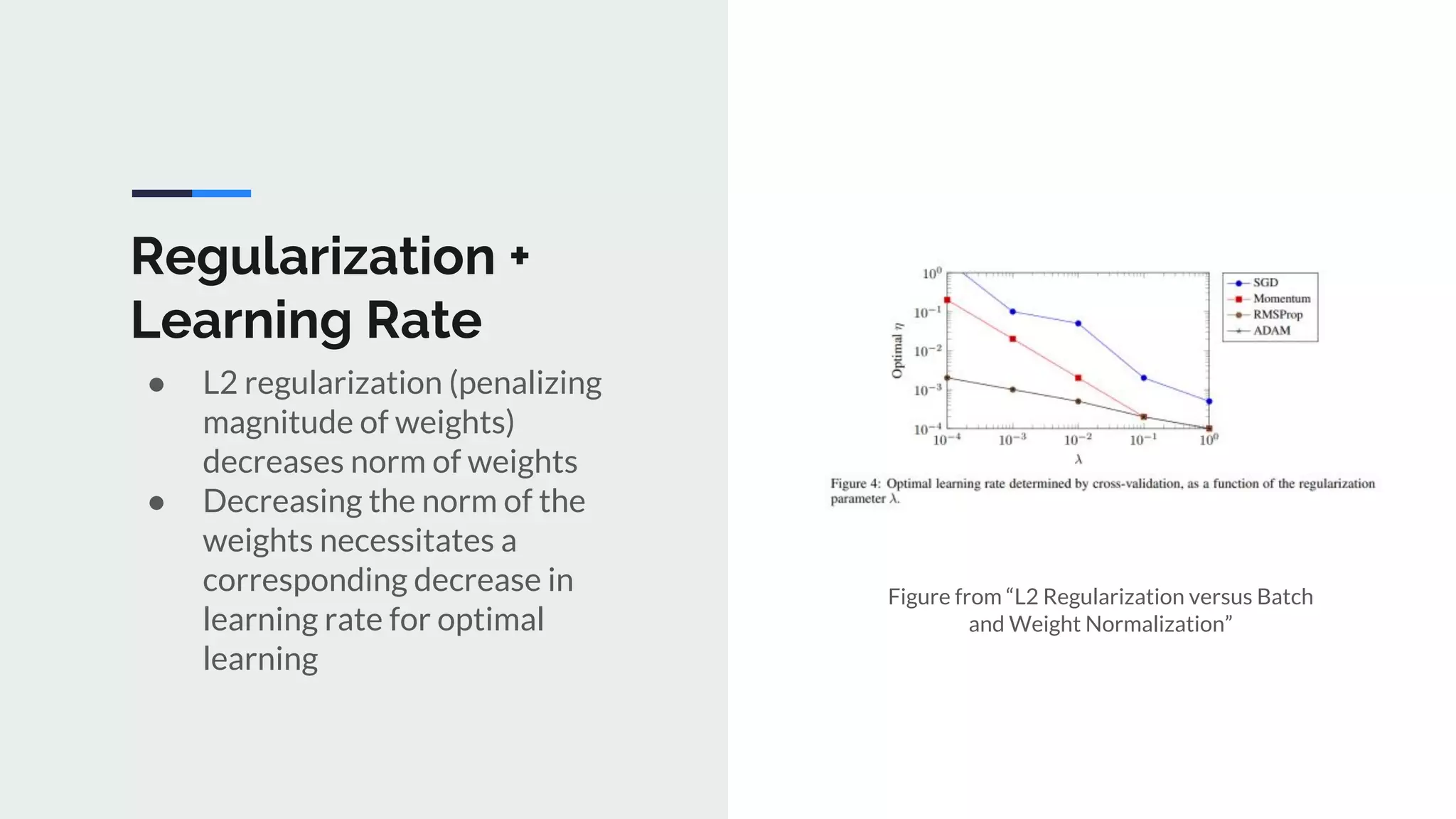


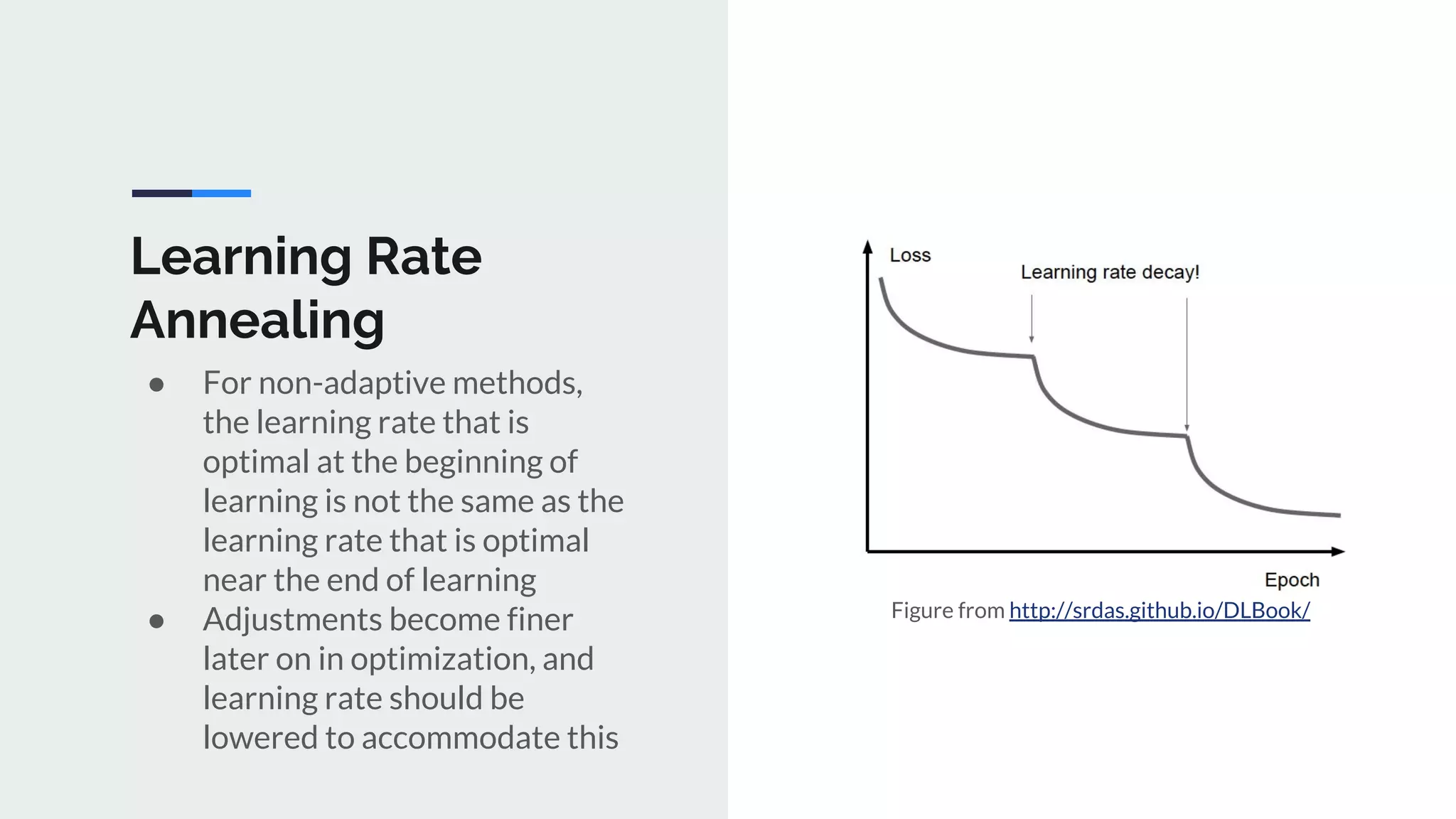
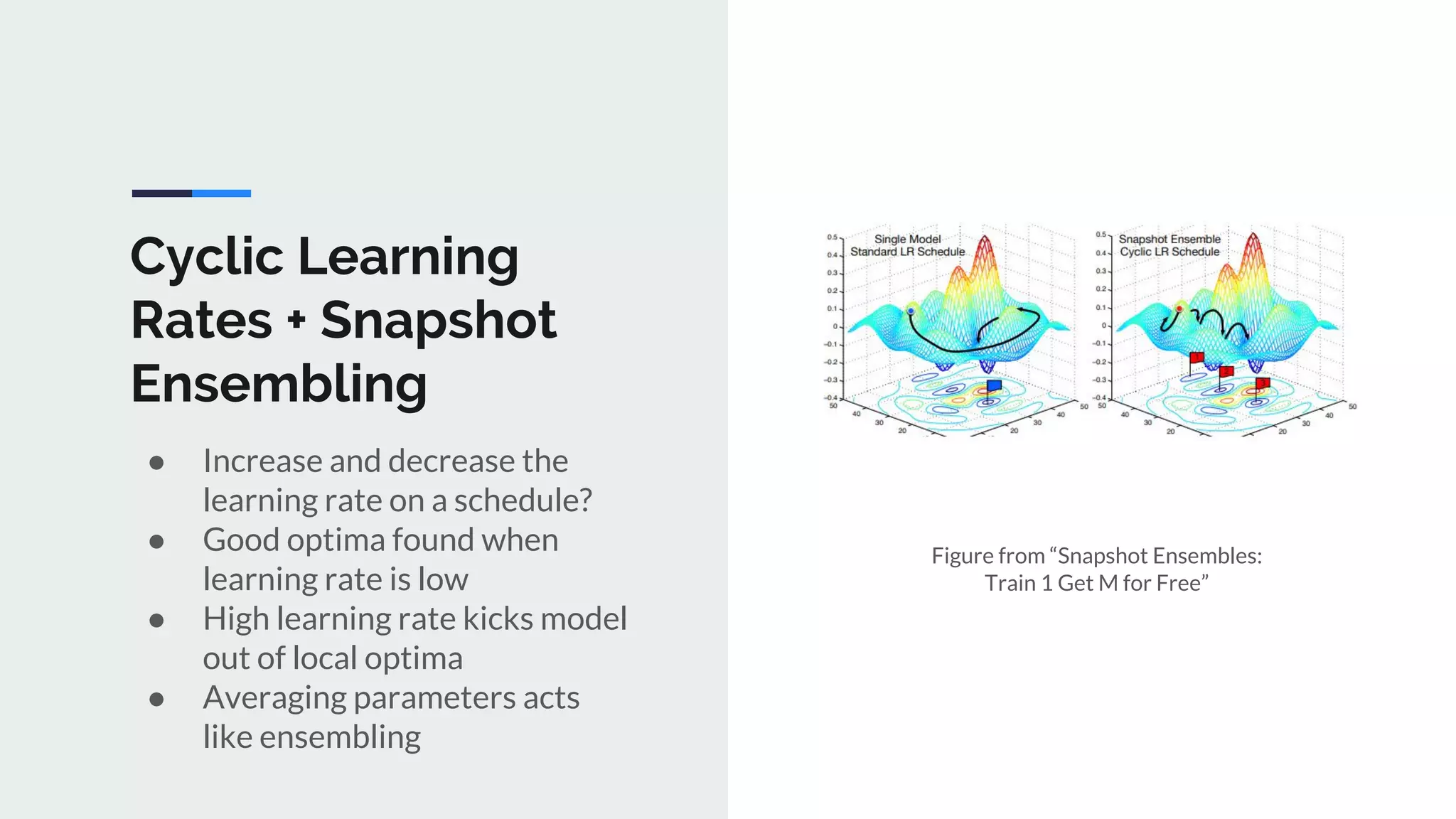


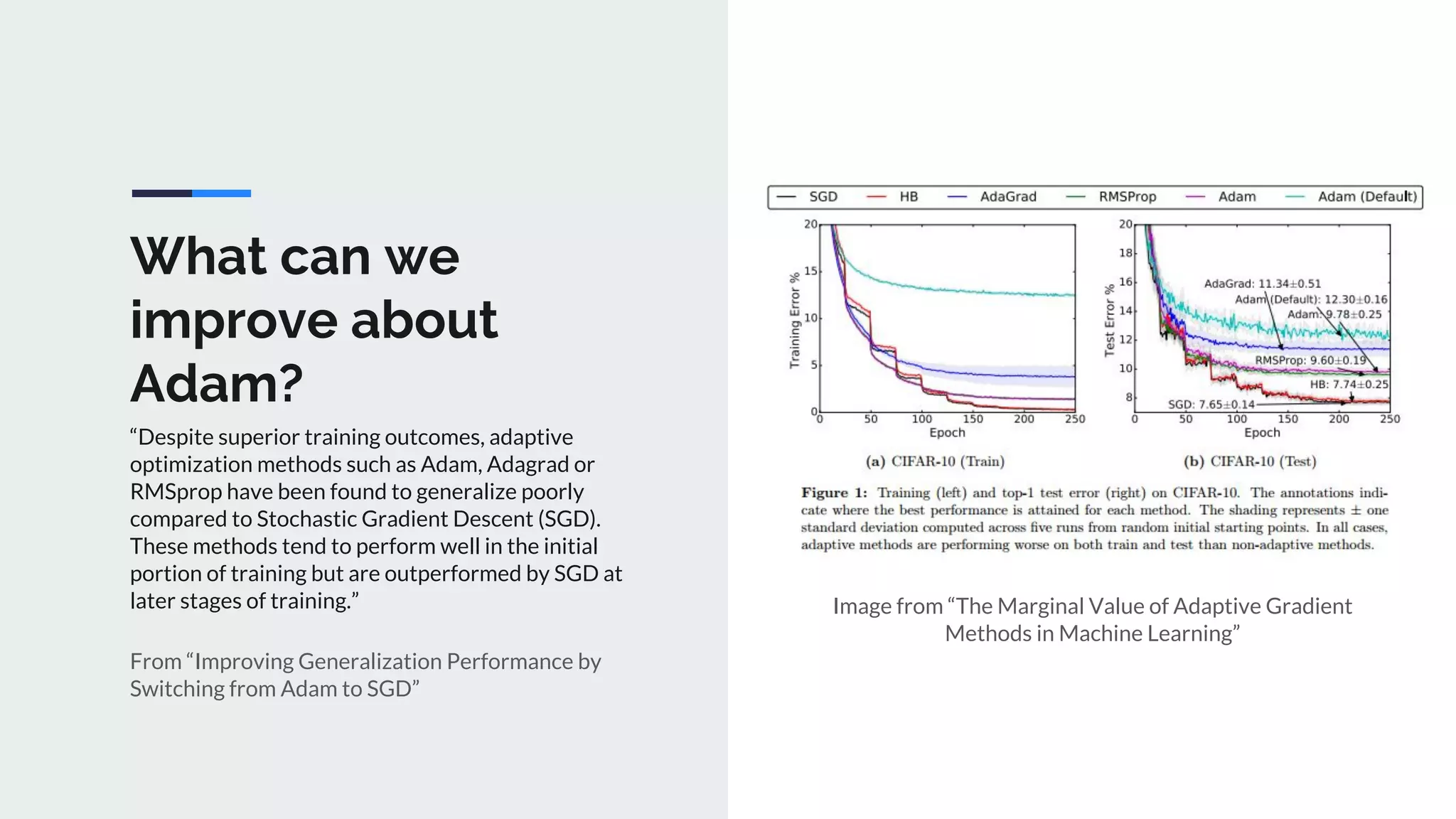
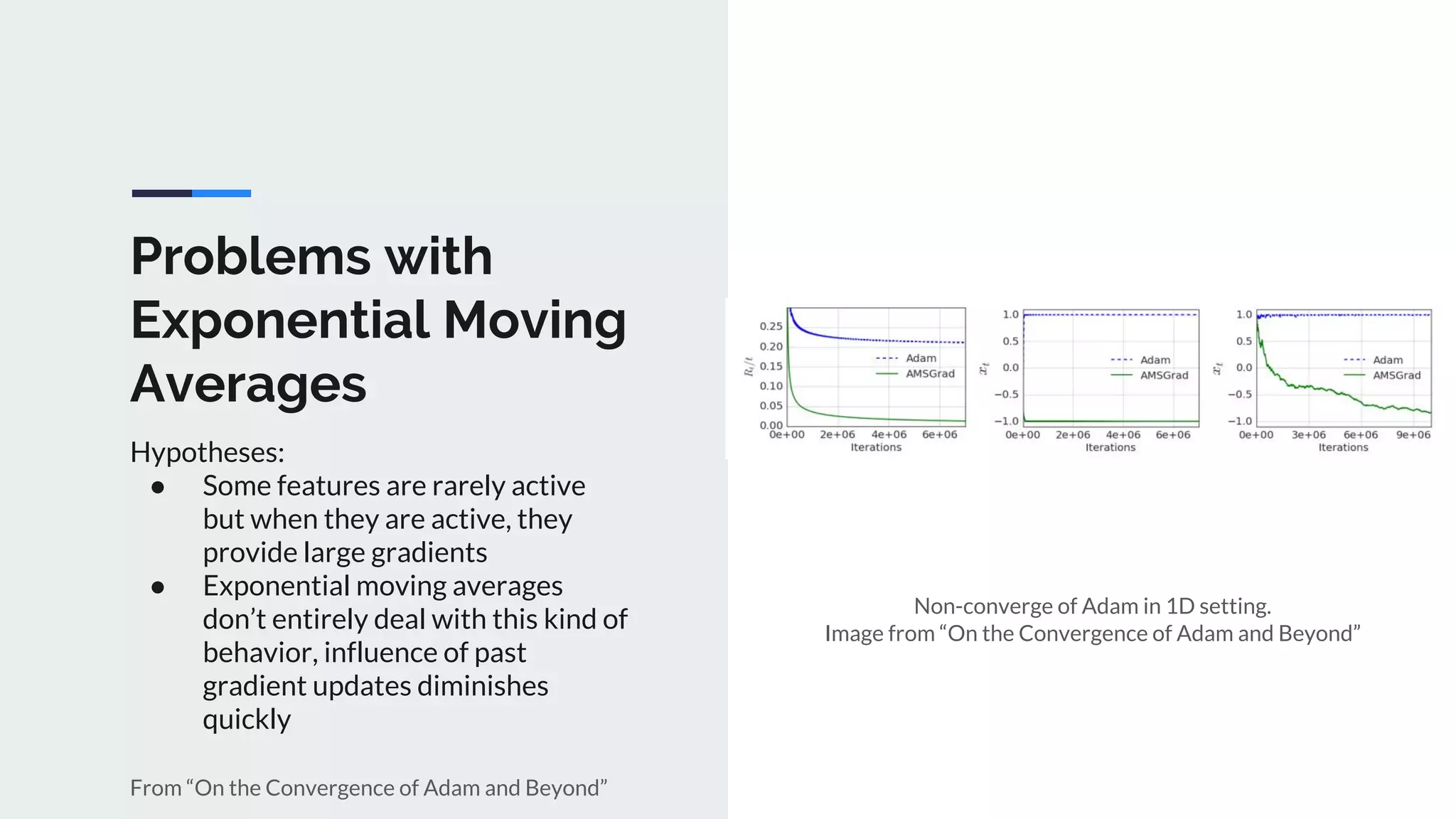



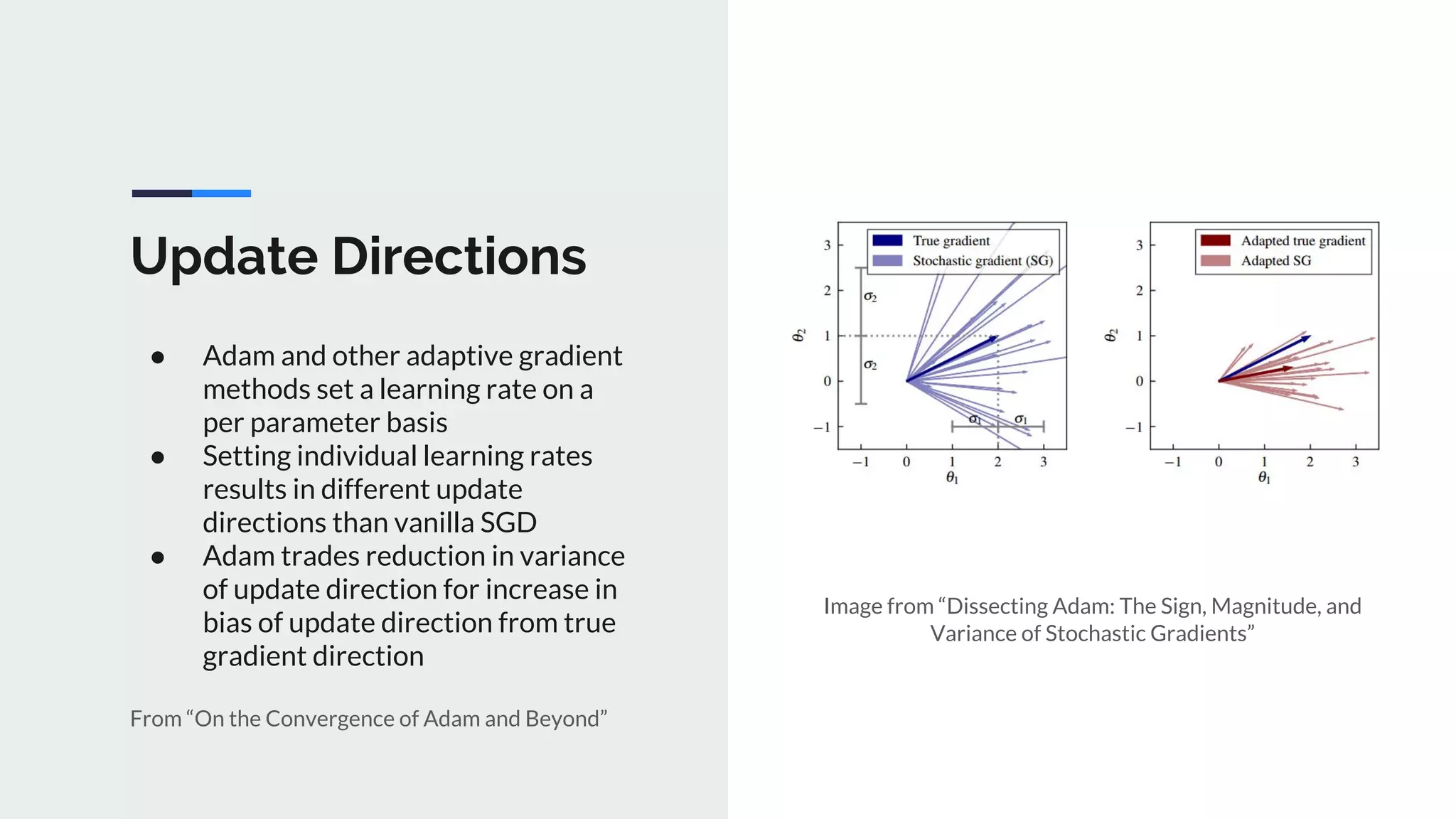
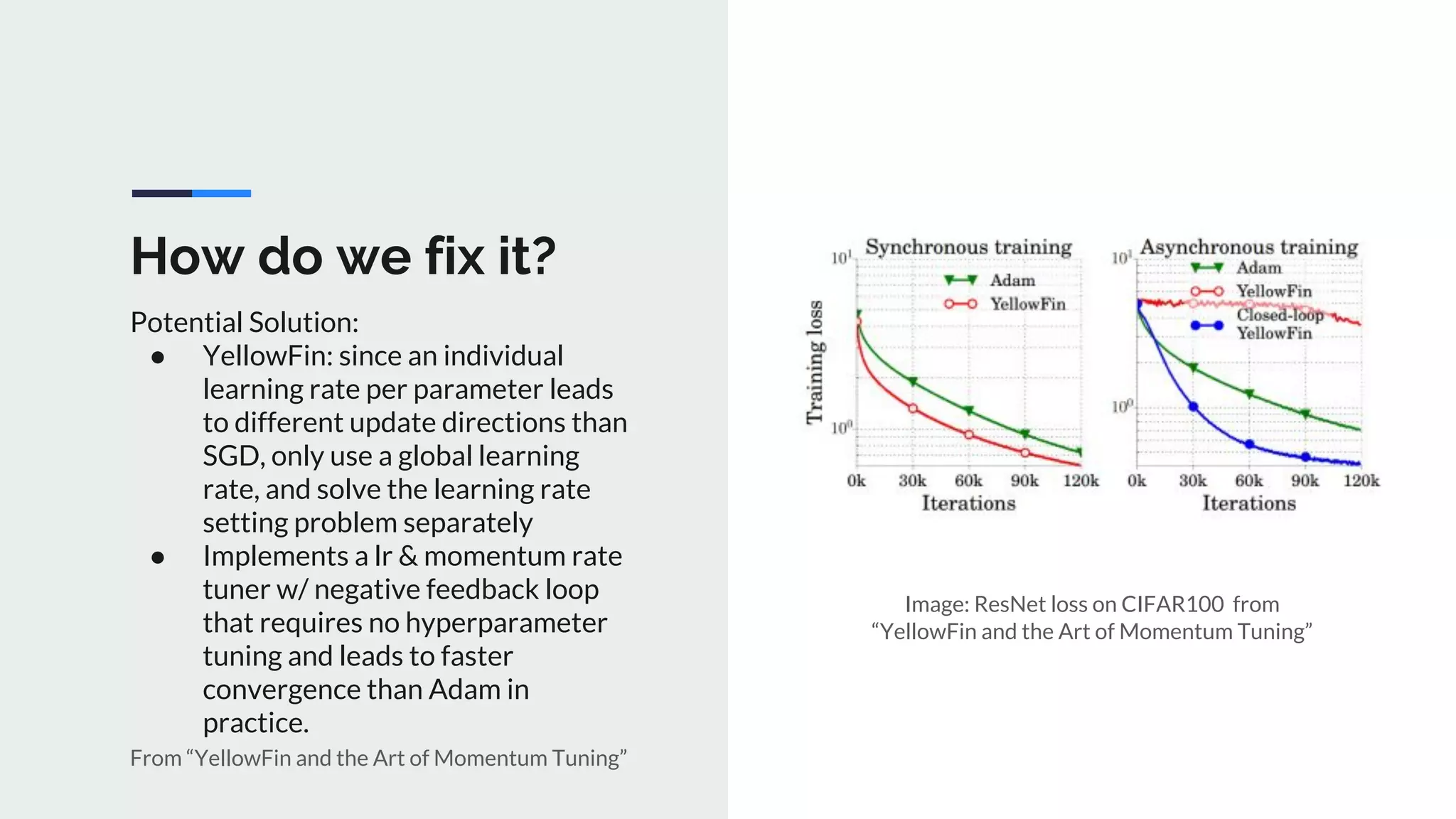




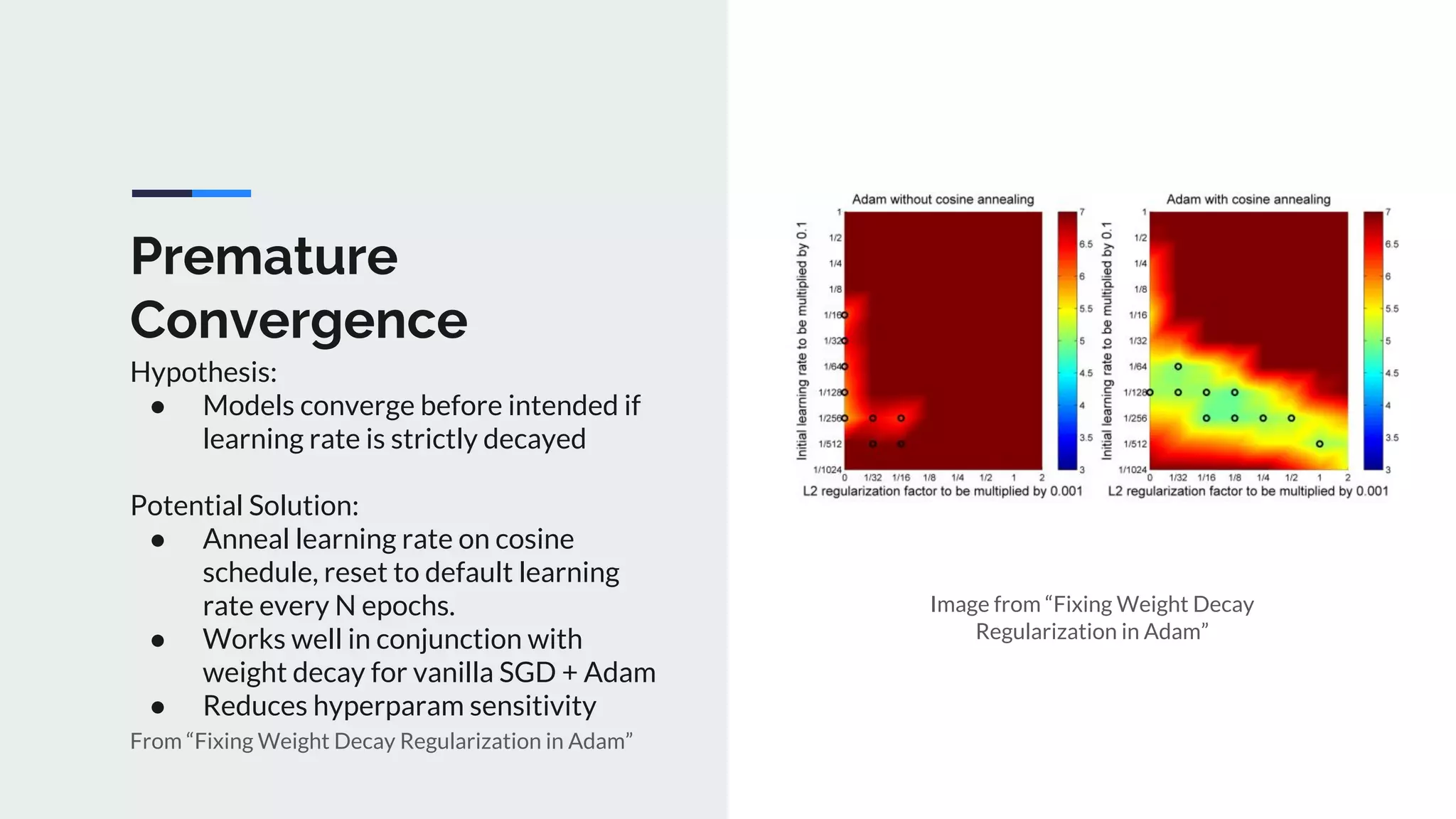

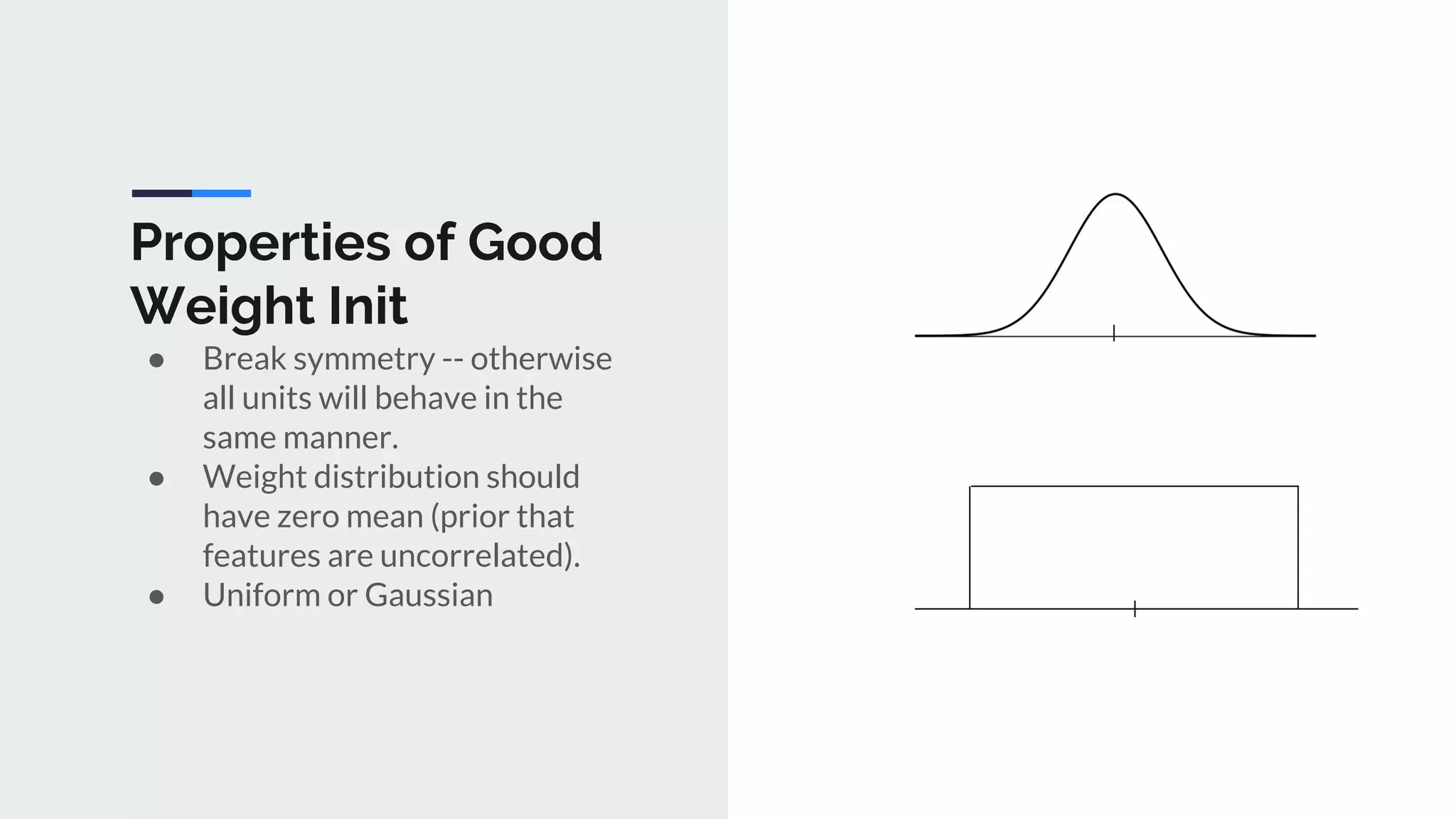



The document provides an extensive overview of optimization techniques in machine learning, particularly focusing on gradient descent methods such as SGD, momentum, and Adam. It discusses the benefits of adjustments like learning rate scheduling and batch size variations, as well as potential issues with adaptive methods and strategies for improvement. Key takeaways include the importance of parameter initialization, the need for careful consideration of hyperparameters, and ongoing developments in the field of optimization.



































![Getting started with indico APIs [Python]](https://cdn.slidesharecdn.com/ss_thumbnails/papisconference-141204130351-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





















