Download as PDF, PPTX





















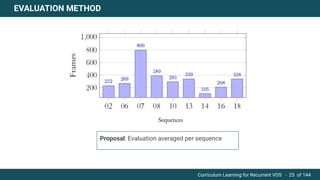

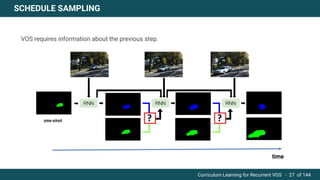
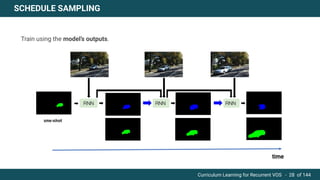
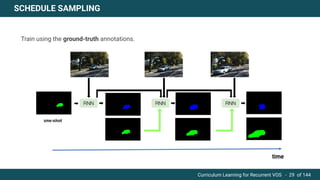
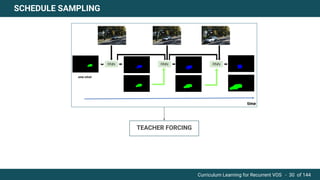
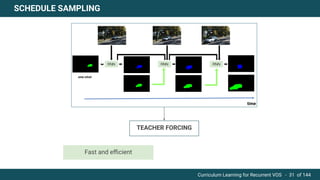
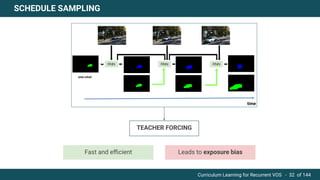



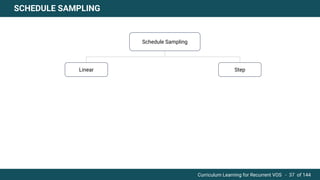






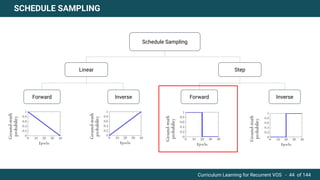


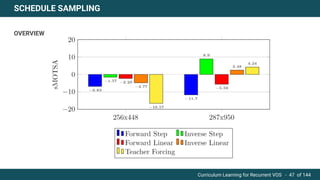
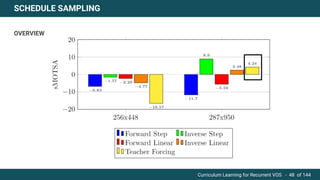
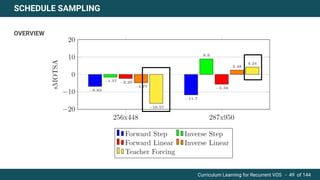
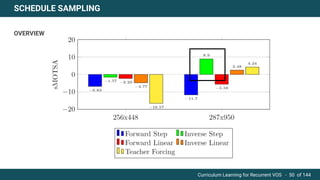












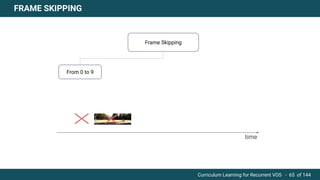
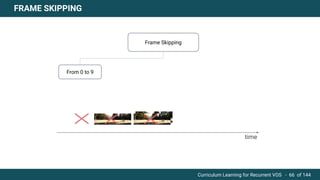
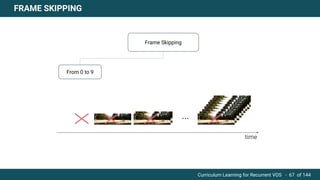
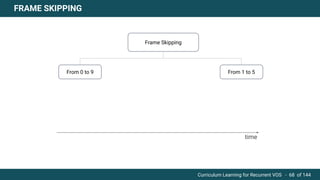
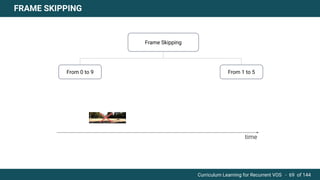

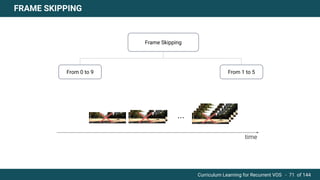
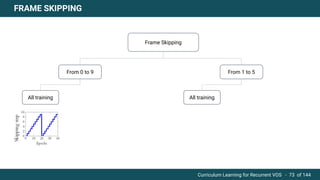
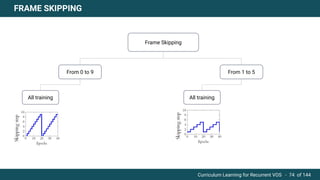
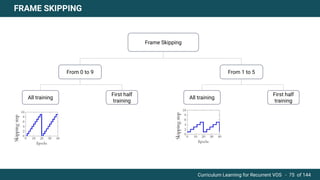
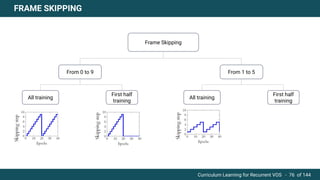
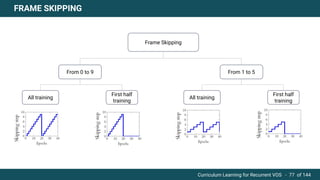









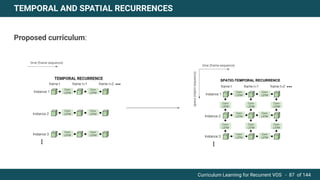
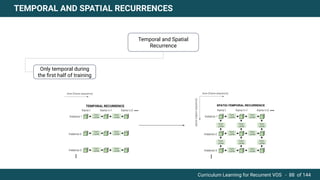
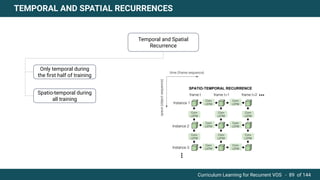
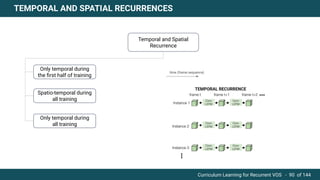
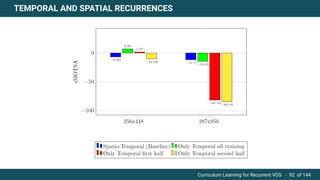
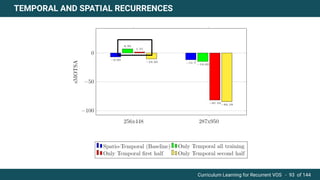





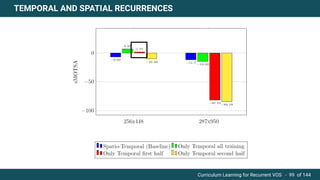










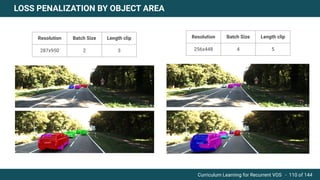

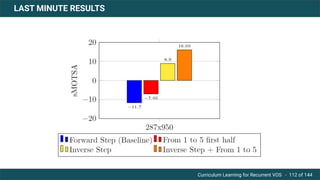







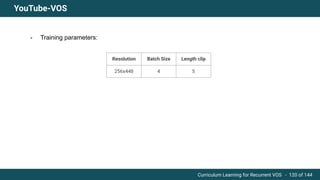

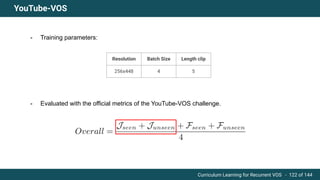
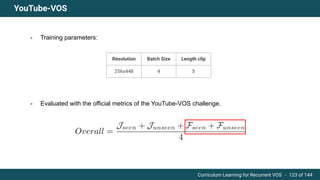

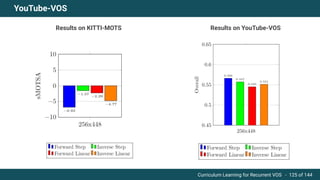
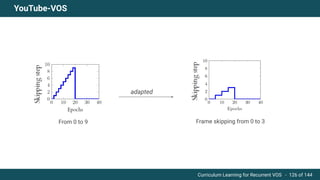
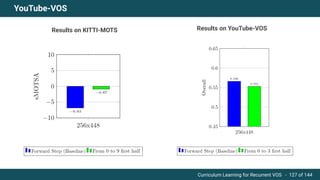




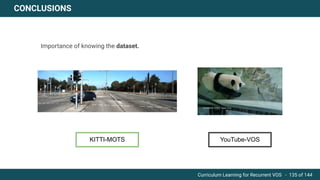
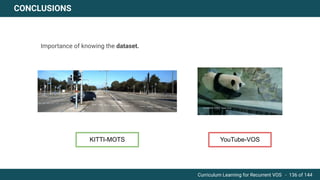

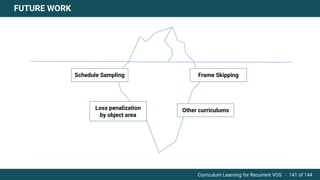
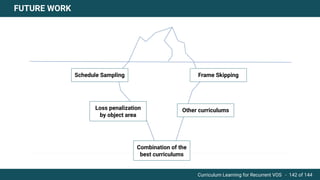



The document discusses curriculum learning applied to recurrent video object segmentation, presenting a methodology where training data is introduced progressively from simple to complex concepts. It explores the Kitti-MOTS dataset, describing an end-to-end recurrent network model for video object segmentation, along with various experimental setups and evaluation metrics. The conclusions highlight the importance of dataset understanding and suggest directions for future work, including further adjustments to training techniques.

























![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)







































