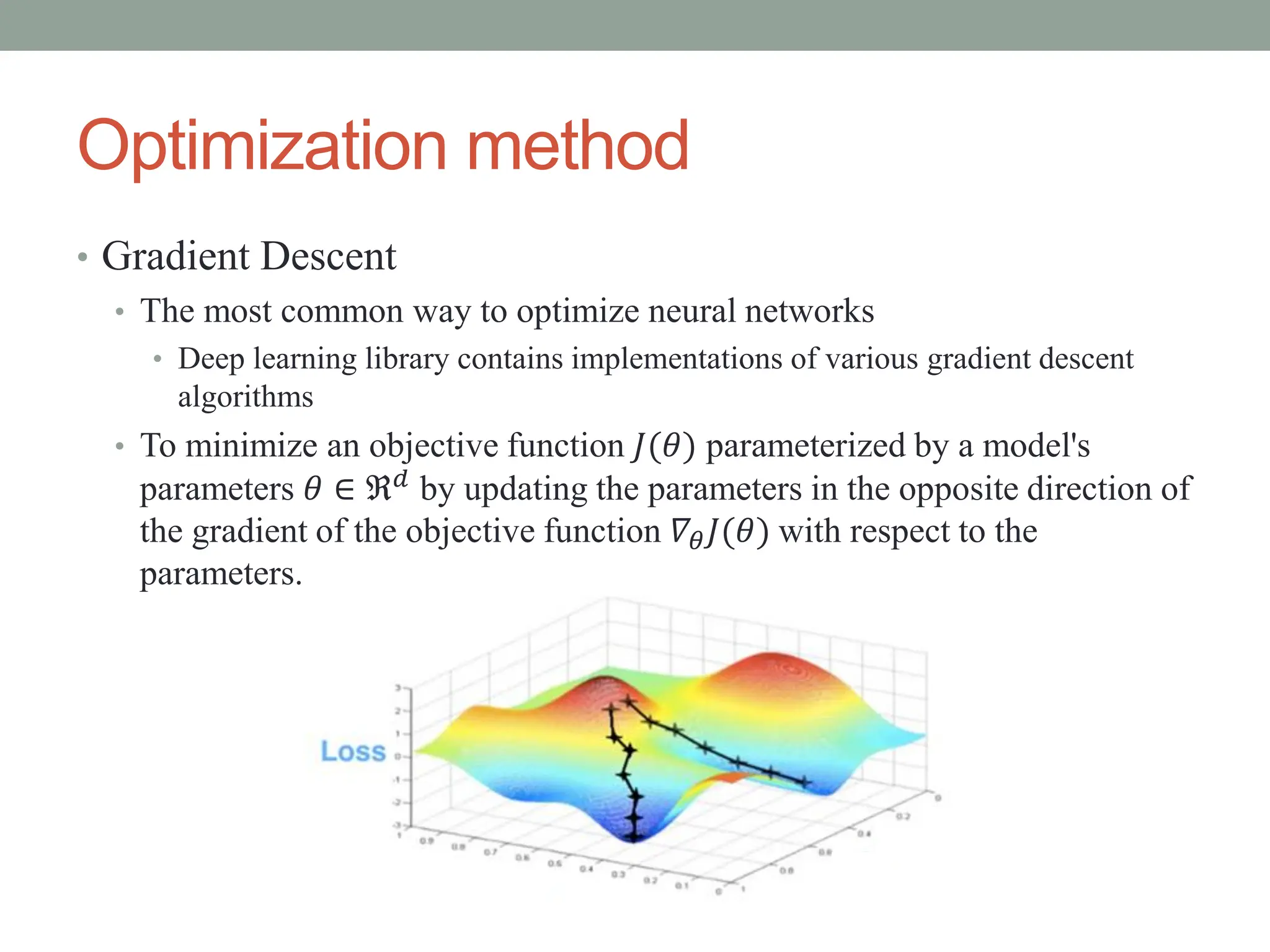
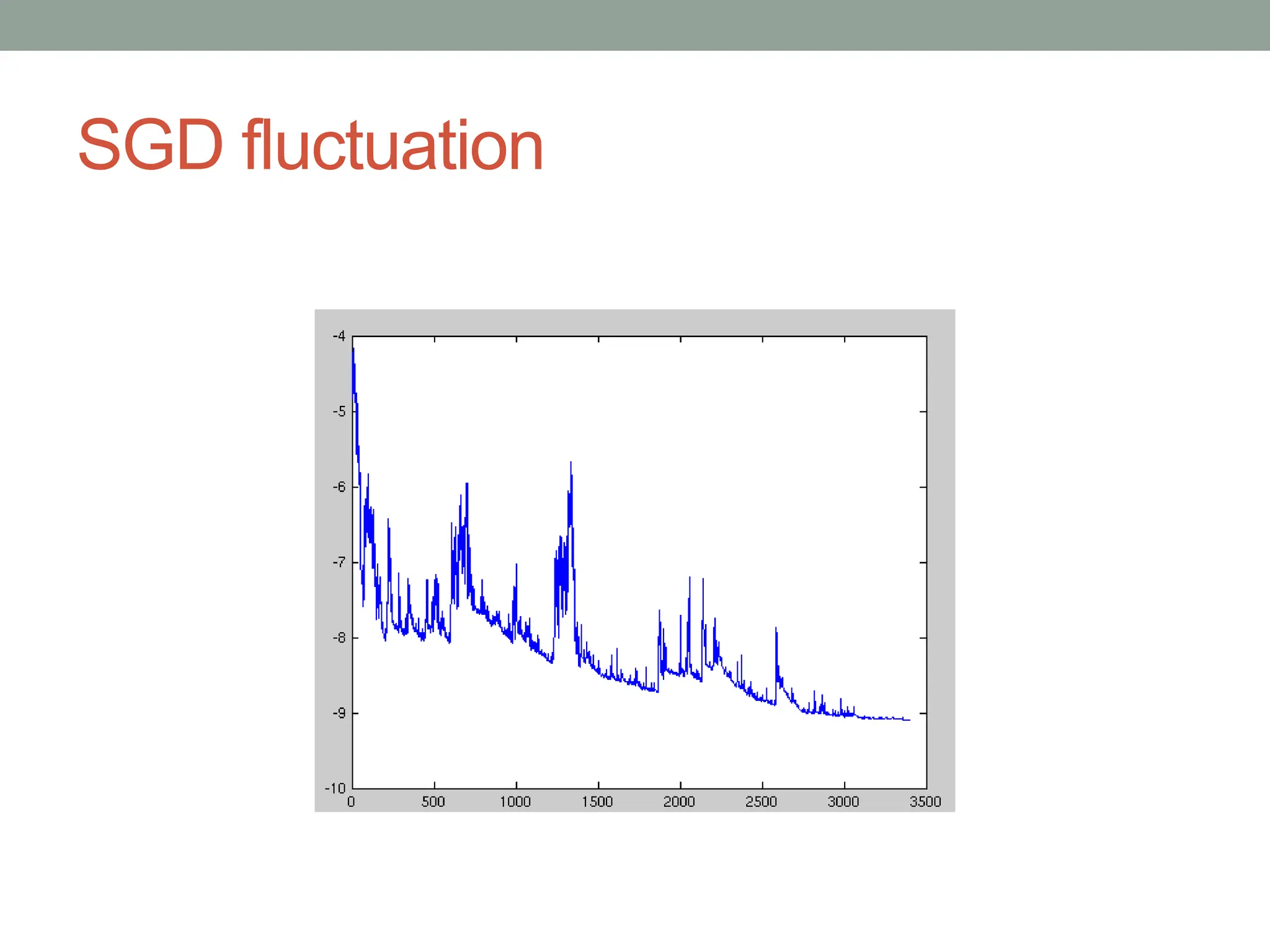
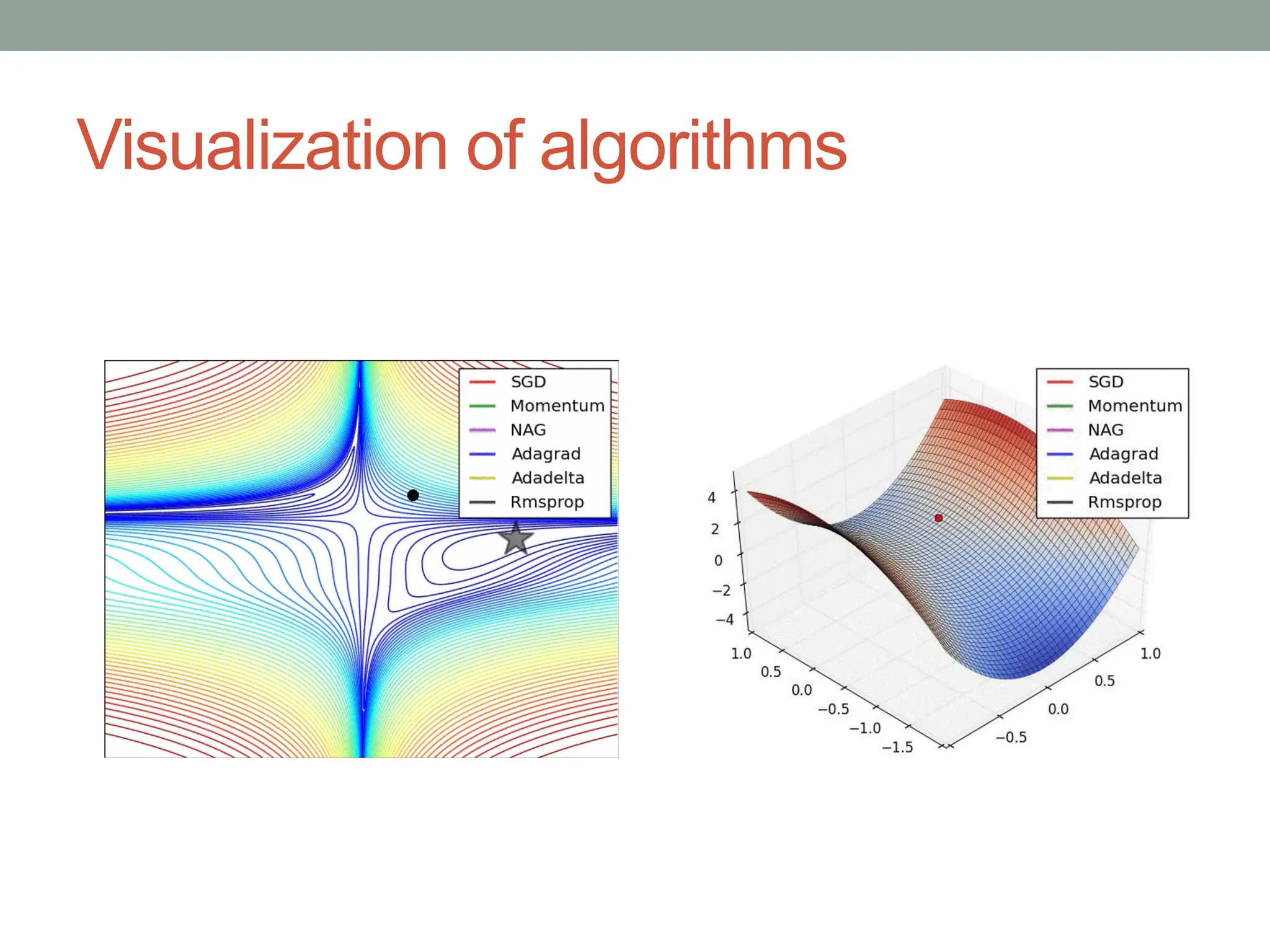
The document provides an overview of gradient descent optimization algorithms used in machine learning for training neural networks, detailing the methods such as batch, stochastic, and mini-batch gradient descent. It discusses challenges in choosing learning rates, the impact of momentum on convergence, and various adaptive gradient methods like Adagrad and Adam. Ultimately, it concludes that mini-batch gradient descent is the most commonly used optimization method due to its efficiency and effectiveness.