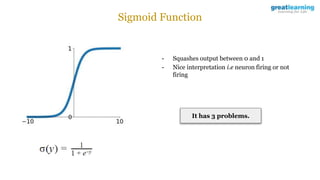
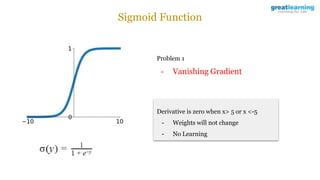
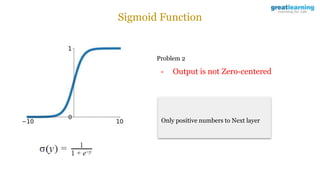
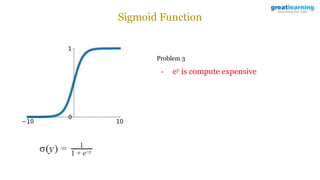
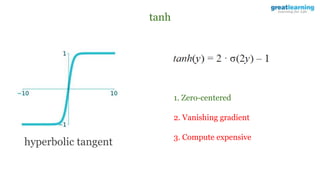
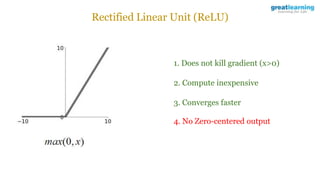
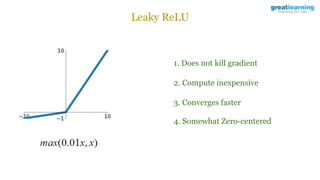
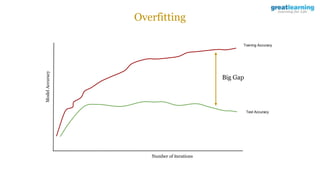
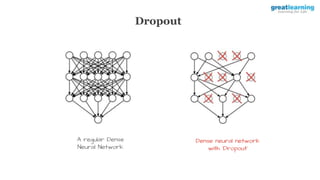
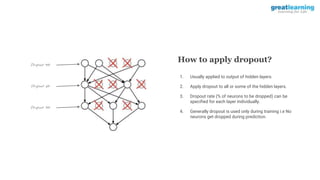
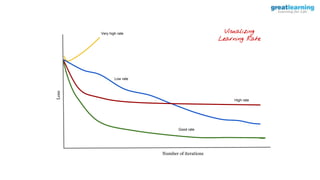
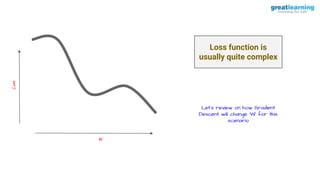
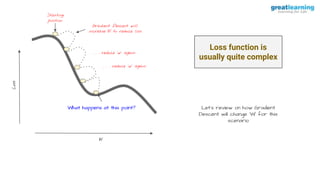
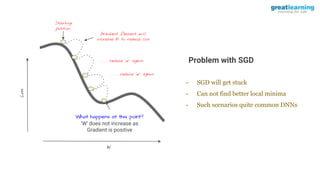
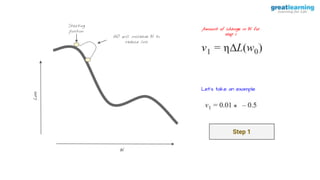
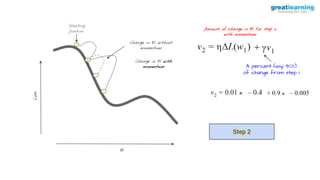
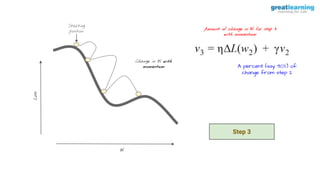
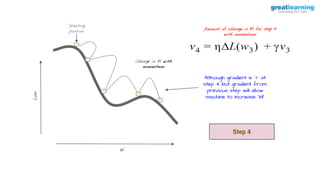
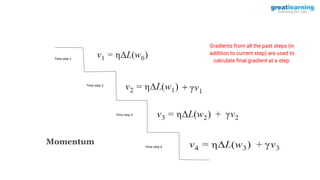
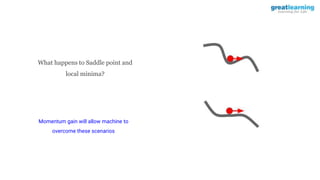
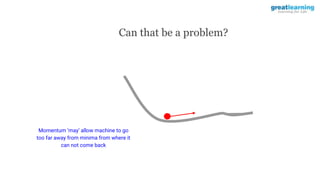
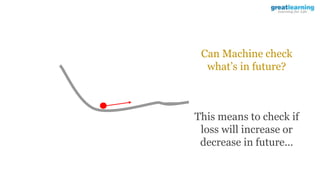
The document discusses different activation functions and their properties for neural networks. It recommends using ReLU or Leaky ReLU activation functions to avoid problems with vanishing gradients in sigmoid and tanh functions. Batch normalization is described as a technique to normalize layer inputs in deep learning models. Dropout is explained as a way to reduce overfitting by randomly dropping neurons during training. Learning rate schedules and optimization algorithms like momentum, Nesterov momentum, Adagrad, and AdaDelta are covered as techniques for improving convergence during training.





























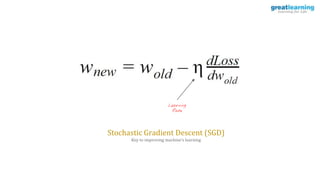













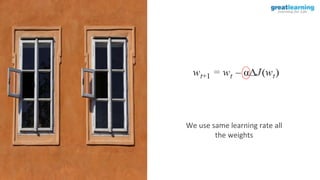
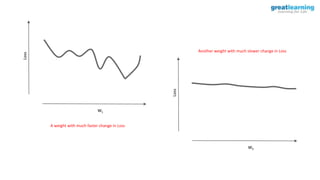
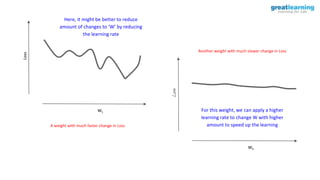



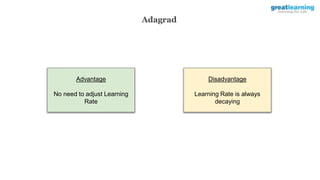
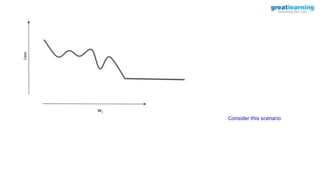
![model.compile(optimizer=’adagrad’, loss=. . ., metrics=[‘accuracy’])
Implementing Adagrad](https://image.slidesharecdn.com/3-240328044624-135fa151/85/3-Training-Artificial-Neural-Networks-pptx-71-320.jpg)




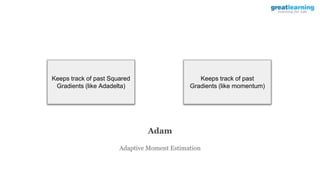




![model.compile(optimizer=’adam’, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
Implementing Adam](https://image.slidesharecdn.com/3-240328044624-135fa151/85/3-Training-Artificial-Neural-Networks-pptx-83-320.jpg)


















































