Download as PDF, PPTX





![Image generation
5
#StyleGAN3 (NVIDIA) Karras, Tero, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and
Timo Aila. "Alias-free generative adversarial networks." NeurIPS 2021. [code]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-5-320.jpg)


![8
#DALL-E-2 (OpenAI) Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen "Hierarchical Text-Conditional Image Generation with CLIP
Latents." 2022. [blog]
#DALL·E-3 (OpenAI) James Betker, Gabriel Goh, et al, “Improving Image Generation with Better Captions” 2023 [blog]
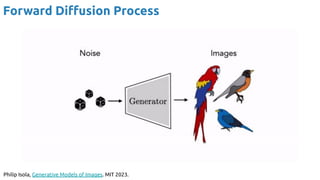
Text-to-Image (T2I) generation
““An expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula.](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-8-320.jpg)


![12
Image Edition & Text-to-Video (T2V) generation
#EMU (Meta) Girdhar, Rohit, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and
Ishan Misra. "Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning." arXiv 2023. [blog]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-12-320.jpg)




![18
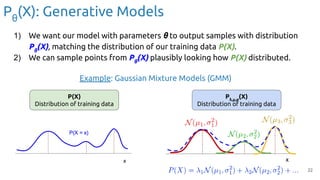
0.01
0.09
0.9
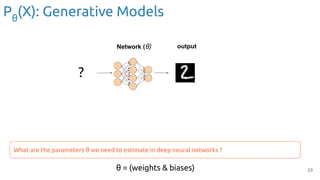
input
Network (θ) output
class
Figure credit: Javier Ruiz (UPC TelecomBCN)
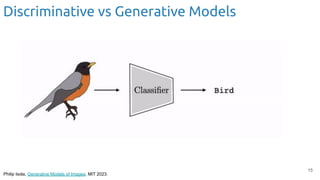
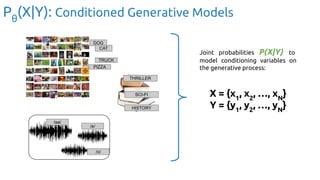
Discriminative model: Tell me the probability of some ‘Y’ responses given ‘X’
inputs.
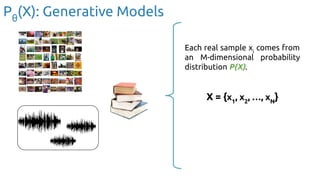
Pθ
(Y | X = [pixel1
, pixel2
, …, pixel784
])
Pθ
(Y|X): Discriminative Models](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-18-320.jpg)






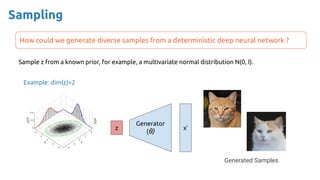
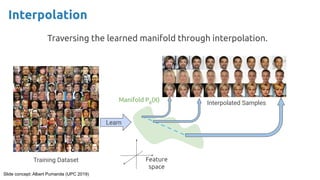
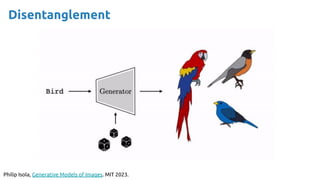
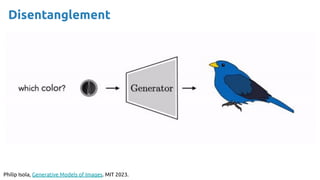

![36
Credit: Santiago Pascual [slides] [video]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-36-320.jpg)

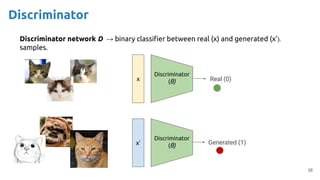
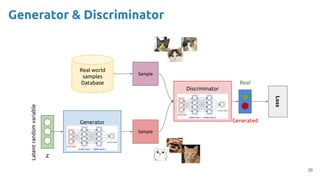

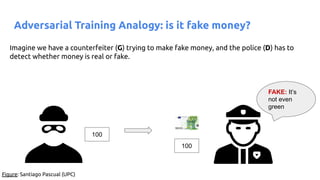



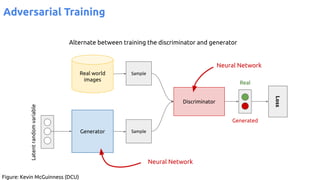
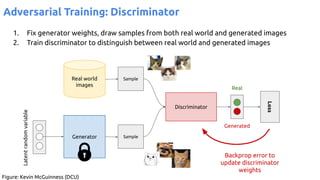
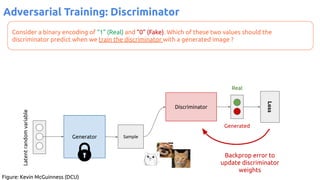
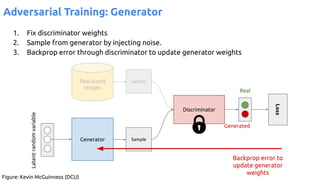
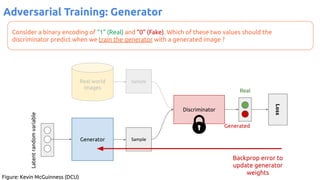





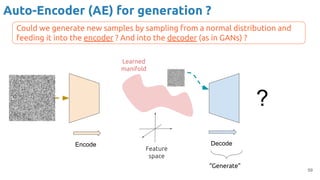
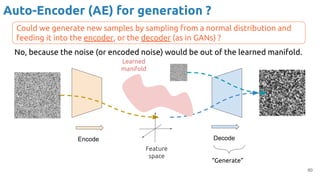

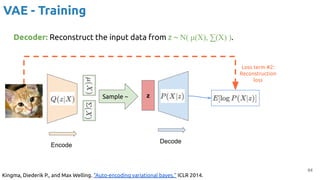
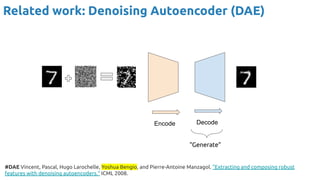
![63
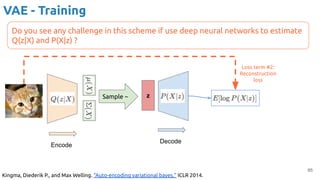
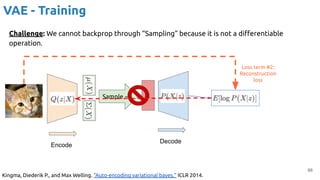
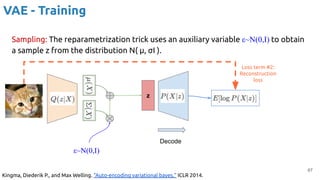
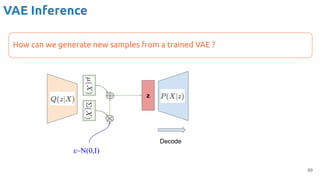
VAE - Training
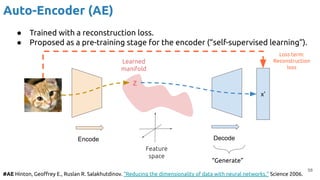
Encoder (training only): Instead of mapping the input x to a fixed vector, we map
it into a multivariate normal distribution z ~ N( μ(X), ∑(X) ).
Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." ICLR 2014.
DKL
[ N( μ(X), ∑(X) ) || N( μ, σ I ) ]
z
Encode
Loss term #1:
KL divergence
Sample ~](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-63-320.jpg)

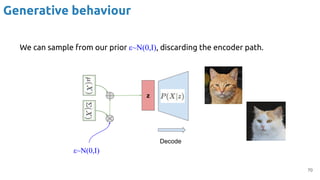
![71
Generative behaviour
#NVAE Vahdat, Arash, and Jan Kautz. "NVAE: A deep hierarchical variational autoencoder." NeurIPS 2020. [code]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-71-320.jpg)









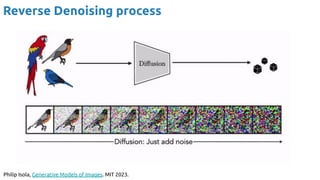
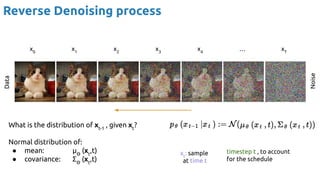

![Latent Diffusion
#LDM (Munich, Heidelberg) Rombach, Robin, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. "High-resolution image
synthesis with latent diffusion models." CVPR 2022. [talk]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-91-320.jpg)
![Latent Diffusion
#LDM (Munich, Heidelberg) Rombach, Robin, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. "High-resolution image
synthesis with latent diffusion models." CVPR 2022. [talk]
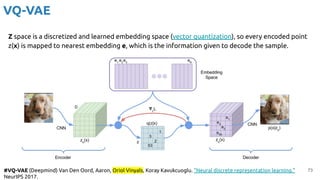
VQ-VAE
Decoder
Sampler
4
4
Denoised
latent
Denoising UNet
Text CLIP
Encoder
768
“The girl with
pearl earring by
Johannes
Vermeer.”](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-92-320.jpg)




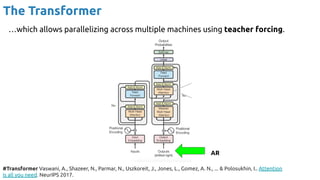
![99
Auto-Regressive (AR)
An auto-regressive approach, where the previous outputs become inputs in
future steps, also allows modelling .
x[t-L+2], …, x
̂ [t+2]
x[t-L+1], …, x
̂ [t+1],
x
̂ [t+1]
x[t-L], …, x
̂ [t]
x
̂ [t+2] x
̂ [t+3]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-99-320.jpg)
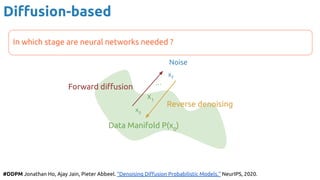
![Wavenet
100
Wavenet used dilated convolutions to produce synthetic audio, sample by
sample, conditioned over by receptive field of size T:
#Wavenet Oord, Aaron van den, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal
Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. "Wavenet: A generative model for raw audio." arXiv 2016. [blog]](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-100-320.jpg)
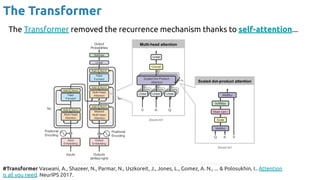
![101
Training AR with Teacher Forcing
#TeacherForcing Williams, Ronald J., and David Zipser. "A learning algorithm for continually running fully recurrent
neural networks." Neural computation 1, no. 2 (1989): 270-280.
AR
(eg. CNN, MLP…)
RNN
x[t-L+1], …, x[t+1],
x
̂ [t+1]
x[t-L], …, x
̂ [t]
x
̂ [t+2]
X
Known label](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-101-320.jpg)


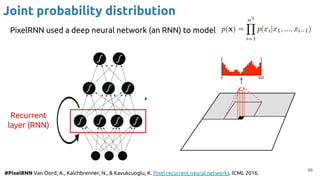
![#iGPT Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., & Sutskever, I. Generative Pretraining from Pixels. ICML
2020. [blog]
iGPT - 1.5B params (similar to GPT-2)
Training: Next-pixel prediction or masked pixel prediction.
Inference: Autoregressive generation of zq
’s with a transformer (global attention).
Input resolutions =
{322
,482
,962
,1922
} x 3
Model resolutions=
{322
,482
}](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-107-320.jpg)
![#iGPT Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., & Sutskever, I. Generative Pretraining from Pixels. ICML
2020. [blog]
iGPT - 1.5B params (similar to GPT-2)](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-108-320.jpg)

![110
#Parti (Google) Yu, Jiahui, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan et al. "Scaling autoregressive models
for content-rich text-to-image generation." TMLR 2023. [blog]
Scaling up to 20B params
Two-Stage Approaches: Parti (20B params)](https://image.slidesharecdn.com/iritraildoctoralnetworkdeepgenerativelearningforall-240422132538-2d3126f1/85/Deep-Generative-Learning-for-All-The-Gen-AI-Hype-Spring-2024-110-320.jpg)






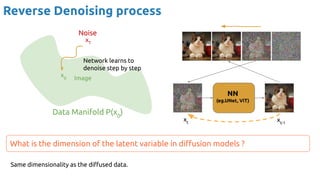
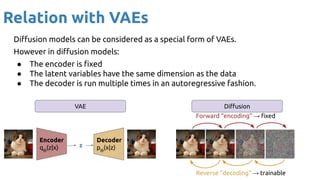
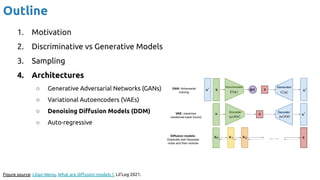
The document discusses deep generative learning, contrasting discriminative and generative models, and explores various architectures including GANs, VAEs, and diffusion models for tasks such as image and music generation. It outlines the technical elements involved in training these models and acknowledges contributions from various researchers. The content emphasizes the advancements and applications of generative models across different domains, providing references to recent noteworthy works.

















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




