Download as PDF, PPTX





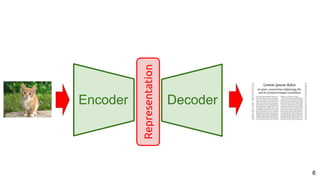


![11
Cornia, Marcella, Matteo Stefanini, Lorenzo Baraldi, and Rita Cucchiara. "Meshed-Memory Transformer for Image
Captioning." CVPR 2020. [tweet]
Image Captioning with Transformers](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-11-320.jpg)




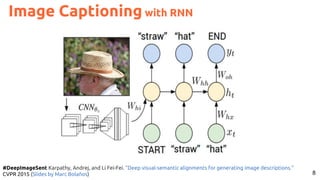
![21
Multimodal Machine Translation
Sulubacak, Umut, Ozan Caglayan, Stig-Arne Grönroos, Aku Rouhe, Desmond Elliott, Lucia Specia, and Jörg Tiedemann.
"Multimodal machine translation through visuals and speech." Machine Translation (2020): 1-51. [tweet]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-21-320.jpg)
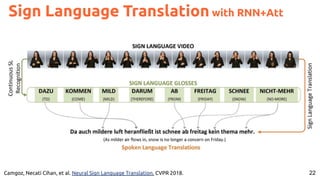
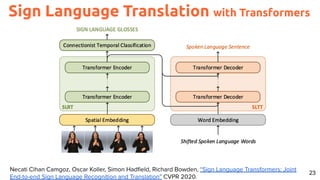

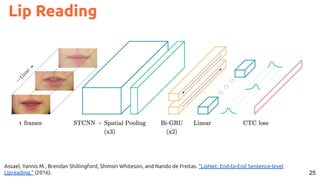

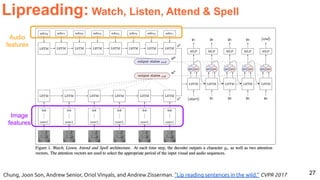
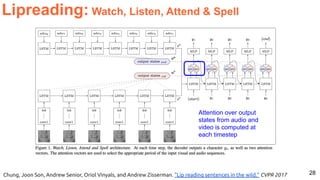
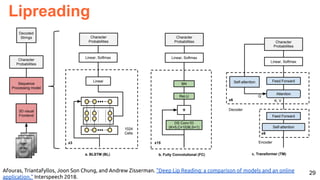
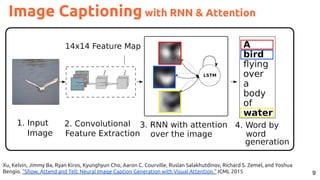
![30
Image Captioning Grounded on Detected Objects
Lu, Jiasen and Yang, Jianwei and Batra, Dhruv and Parikh, Devi “Neural Baby Talk” CVPR 2018 [code]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-30-320.jpg)
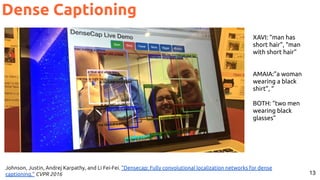
![31Lu, Jiasen and Yang, Jianwei and Batra, Dhruv and Parikh, Devi “Neural Baby Talk” CVPR 2018 [code]
Image Captioning Grounded on Detected Objects](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-31-320.jpg)
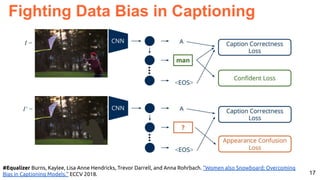
![32Akbari, Hassan, Svebor Karaman, Surabhi Bhargava, Brian Chen, Carl Vondrick, and Shih-Fu Chang. "Multi-level Multimodal
Common Semantic Space for Image-Phrase Grounding." CVPR 2019. [code]
Image Captioning Grounded on Heatmaps](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-32-320.jpg)


![36
Reed, Scott, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. "Generative adversarial
text to image synthesis." ICML 2016. [code]
Image Generation](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-36-320.jpg)
![37
Image Synthesis
#StackGAN Zhang, Han, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaolei Huang, Xiaogang Wang, and Dimitris Metaxas.
"Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks." ICCV 2017. [code]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-37-320.jpg)
![38
Image Synthesis with Cycle Consistency
#MirroGAN Qiao, Tingting, Jing Zhang, Duanqing Xu, and Dacheng Tao. "Mirrorgan: Learning text-to-image generation by
redescription." CVPR 2019. [code]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-38-320.jpg)
![39
Image Synthesis with Cycle Consistency
#MirroGAN Qiao, Tingting, Jing Zhang, Duanqing Xu, and Dacheng Tao. "Mirrorgan: Learning text-to-image generation by
redescription." CVPR 2019. [code]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-39-320.jpg)
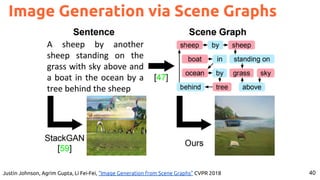
![41
#Text2Scene Tan, Fuwen, Song Feng, and Vicente Ordonez. "Text2Scene: Generating Compositional Scenes From Textual
Descriptions." CVPR 2019 [blog].](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-41-320.jpg)

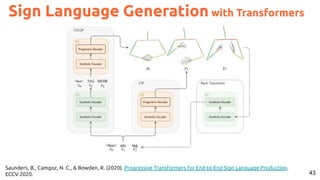


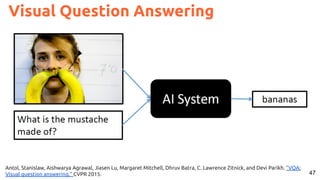
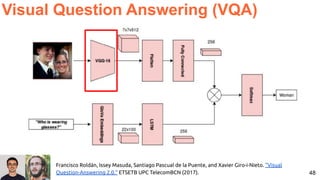
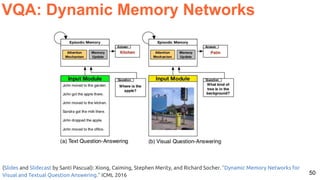


![54
Visual Dialog
Das, Abhishek, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra. "Visual
Dialog." CVPR 2017 [Project]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-54-320.jpg)
![55
Visual Dialog
Caros, Mariona, Maite Garolera, Petia Radeva, and Xavier Giro-i-Nieto. "Automatic Reminiscence Therapy for
Dementia." ICMR 2020. [talk]
Demo @ ICMR 2020 (Wednesday 11:00am)](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-55-320.jpg)
![56
Visual Dialog
Caros, Mariona, Maite Garolera, Petia Radeva, and Xavier Giro-i-Nieto. "Automatic Reminiscence Therapy for
Dementia." ICMR 2020. [talk]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-56-320.jpg)
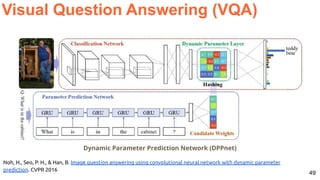
![57
Hate Speech Detection in Memes
Benet Oriol, Cristian Canton, Xavier Giro-i-Nieto, “Hate Speech in Pixels: Detection of Offensive Memes
towards Automatic Moderation”. NeurIPS 2019 AI for Good Workshop. [code]
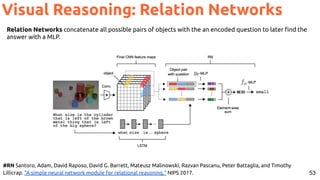
Hate Speech Detection](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-57-320.jpg)

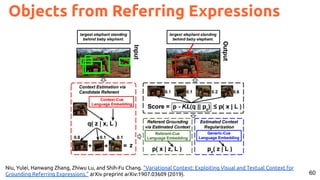
![61
Video Objects from Referring Expressions
Li, Zhenyang, Ran Tao, Efstratios Gavves, Cees GM Snoek, and Arnold WM Smeulders. "Tracking by natural language
specification." CVPR 2017. [code]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-61-320.jpg)
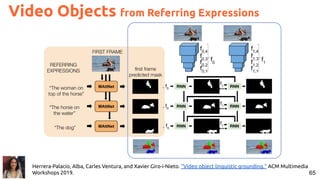
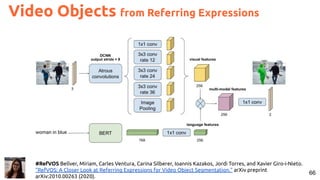
![63
#Mattnet Yu, Licheng, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L. Berg. "Mattnet: Modular
attention network for referring expression comprehension." CVPR 2018. [code]
Segments from Referring Expressions](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-63-320.jpg)




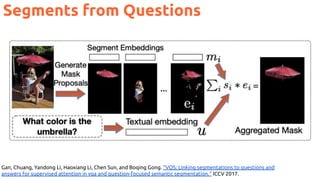

![74
Zero-shot learning
Socher, R., Ganjoo, M., Manning, C. D., & Ng, A., Zero-shot learning through cross-modal transfer. NIPS 2013 [slides] [code]
No images from “cat” in
the training set...
...but they can still be
recognised as “cats”
thanks to the
representations learned
from text .](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-74-320.jpg)
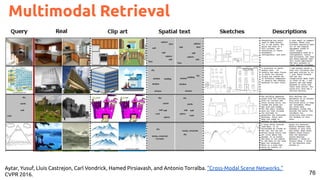
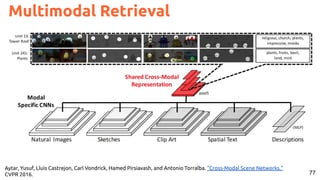
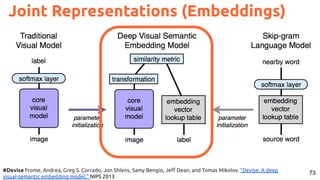
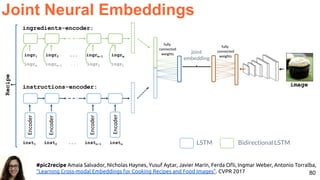
![78
Image and text retrieval with joint embeddings.
Joint Neural Embeddings
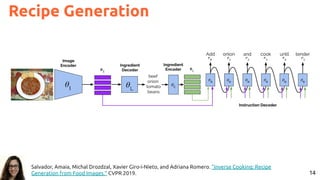
#pic2recipe Amaia Salvador, Nicholas Haynes, Yusuf Aytar, Javier Marín, Ferda Ofli, Ingmar Weber, Antonio
Torralba, “Learning Cross-modal Embeddings for Cooking Recipes and Food Images”. CVPR 2017 [video]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-78-320.jpg)
![79
#pic2recipe Amaia Salvador, Nicholas Haynes, Yusuf Aytar, Javier Marín, Ferda Ofli, Ingmar Weber, Antonio Torralba,
“Learning Cross-modal Embeddings for Cooking Recipes and Food Images”. CVPR 2017 [video]
Joint Neural Embeddings](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-79-320.jpg)
![81
Representations
Sariyildiz, Mert Bulent, Julien Perez, and Diane Larlus. "Learning Visual Representations with Caption Annotations." ECCV
2020. [tweet]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-81-320.jpg)
![82
Representations
#ViLBERT Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. "Vilbert: Pretraining task-agnostic visiolinguistic
representations for vision-and-language tasks." NeurIPS 2019. [MIT talk by Devih Parikh] [demo]
Visual Task:
Predict the visual categories for the
masked video frame
Language Task:
Predict the masked word (same as in
language-only BERT).](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-82-320.jpg)
![83
Representations
#ViLBERT Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. "Vilbert: Pretraining task-agnostic visiolinguistic
representations for vision-and-language tasks." NeurIPS 2019. [MIT talk by Devih Parikh] [demo]
Multimodal Task:
Predict whether the video frames correspond to the caption.](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-83-320.jpg)


![86
Representations
#VirTEX Karan Desai, Justin Johnson, “VirTex: Learning Visual Representations from Textual Annotations” arXiv 2020
[tweet]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-86-320.jpg)



![90
Platforms for Embodied AI
#Habitat Savva, Manolis, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub et
al. "Habitat: A platform for embodied ai research." ICCV 2019. [site]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-90-320.jpg)

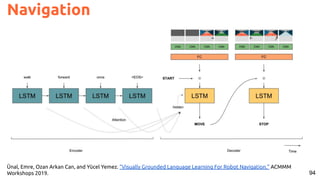
![92
Navigation
#R2R Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sünderhauf, N., ... & van den Hengel, A. Vision-and-language
navigation: Interpreting visually-grounded navigation instructions in real environments. CVPR 2018. [tweet]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-92-320.jpg)

![95
Object manipulation
Hill, F., Lampinen, A. K., Schneider, R., Clark, S., Botvinick, M., McClelland, J. L., & Santoro, A. Environmental drivers of
systematicity and generalization in a situated agent. ICLR 2020. [talk]](https://image.slidesharecdn.com/icmr202003languagevision-201106092555/85/Language-and-Vision-with-Deep-Learning-Xavier-Giro-ACM-ICMR-2020-Tutorial-95-320.jpg)



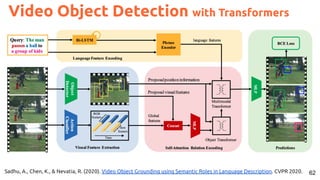
The document outlines various models and techniques related to generative and discriminative tasks in language and vision, focusing on image and video captioning, visual question answering, and sign language translation. It references numerous studies and methods, including encoder-decoder representations, attention mechanisms, and multimodal machine translation. Key topics include combating data bias, dynamic memory networks, and advancements in visual reasoning and object grounding through language.














































































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)





