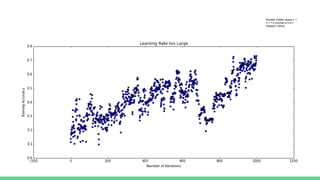
This document discusses various optimization techniques for training neural networks, including gradient descent, stochastic gradient descent, momentum, Nesterov momentum, RMSProp, and Adam. The key challenges in neural network optimization are long training times, hyperparameter tuning such as learning rate, and getting stuck in local minima. Momentum helps accelerate learning by amplifying consistent gradients while canceling noise. Adaptive learning rate algorithms like RMSProp, Adagrad, and Adam automatically tune the learning rate over time to improve performance and reduce sensitivity to hyperparameters.






![Momentum
Dramatically Accelerates Learning
1. Initialize learning rates & momentum matrix the size of the weights
2. At each SGD iteration, collect the gradient.
3. Update momentum matrix to be momentum rate times a momentum
hyperparameter plus the learning rate times the collected gradient.
s = .9 = momentum hyperparameter t.layers[i].moment1 = layer i’s momentum matrix lr = .01 gradient = sgd’s collected gradient](https://image.slidesharecdn.com/optimizationindeeplearning-170315042317/85/Optimization-in-deep-learning-8-320.jpg)
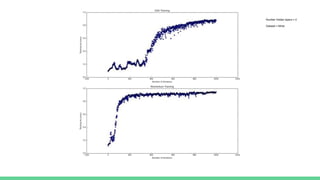
![Intuition for Momentum
Automatically cancels out noise in the gradient
Amplifies small but consistent gradients
“Momentum” derives from the physical analogy [momentum = mass * velocity]
Assumes unit mass
Velocity vector is the ‘particle's’ momentum
Deals well with heavy curvature](https://image.slidesharecdn.com/optimizationindeeplearning-170315042317/85/Optimization-in-deep-learning-10-320.jpg)


















































![[AI07] Revolutionizing Image Processing with Cognitive Toolkit](https://cdn.slidesharecdn.com/ss_thumbnails/ai07-170602095346-thumbnail.jpg?width=640&height=640&fit=bounds)
















































