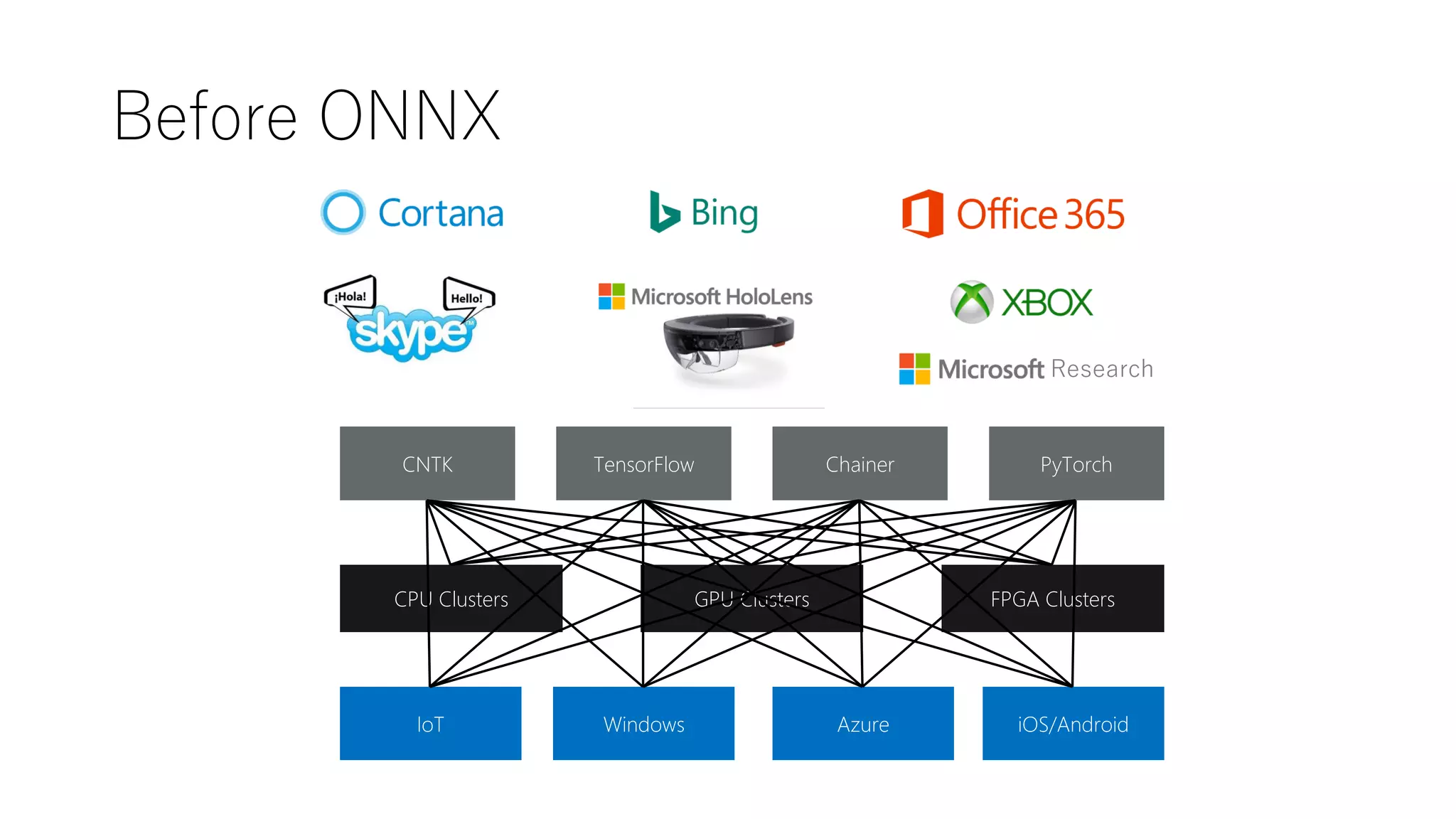
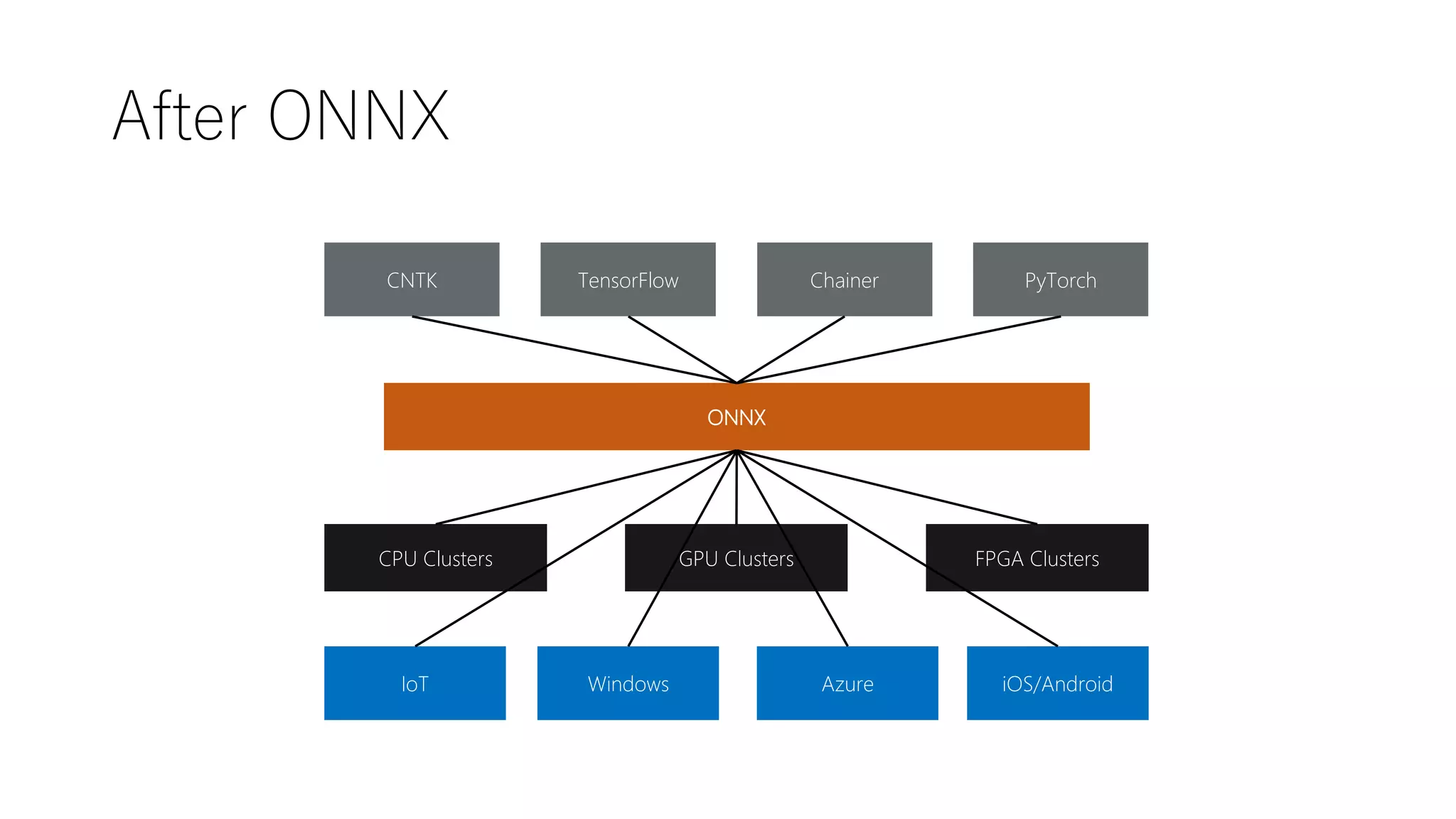
ONNX Runtime &Menoh
• High performance runtime for ONNX models
• Supports full ONNX-ML spec (v1.2 and higher,
currently up to 1.4)
• Works on Mac, Windows, Linux (ARM too)
• Extensible architecture to plug-in optimizers
and hardware accelerators
• CPU and GPU support
• Python, C#, and C APIs
0 1 2 3
BERT-based
Transformer w/
attention
Bing QnA
Original framework
ONNX Runtime
0 1 2 3
zfnet512
tiny_yolov2
squeezenet
shufflenet
resnet 50
inception_v2
inception_v1
emotion_ferplus
densenet121
bvlc_googlenet
ONNX Model Zoo
CUDA TensorRT
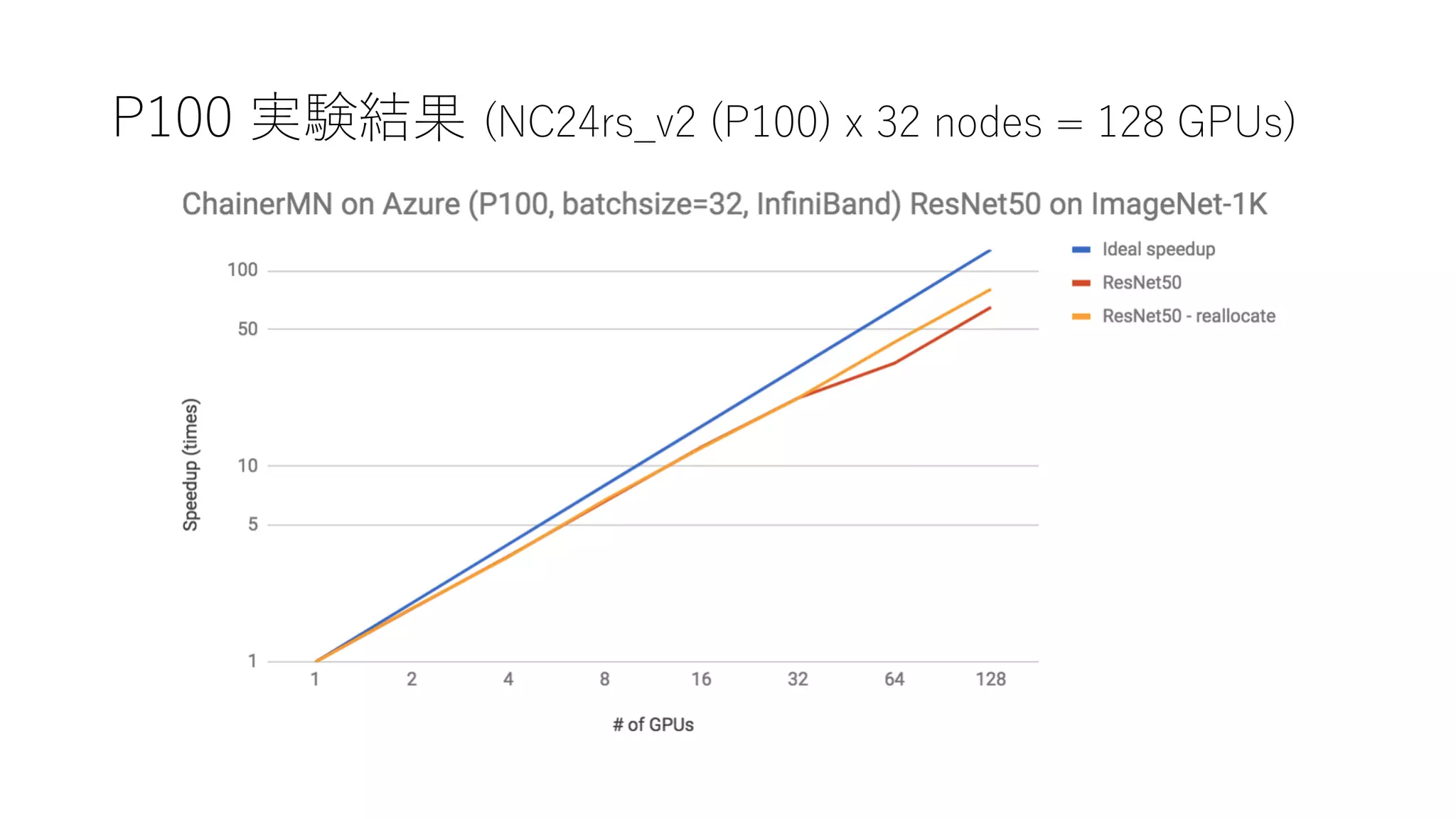
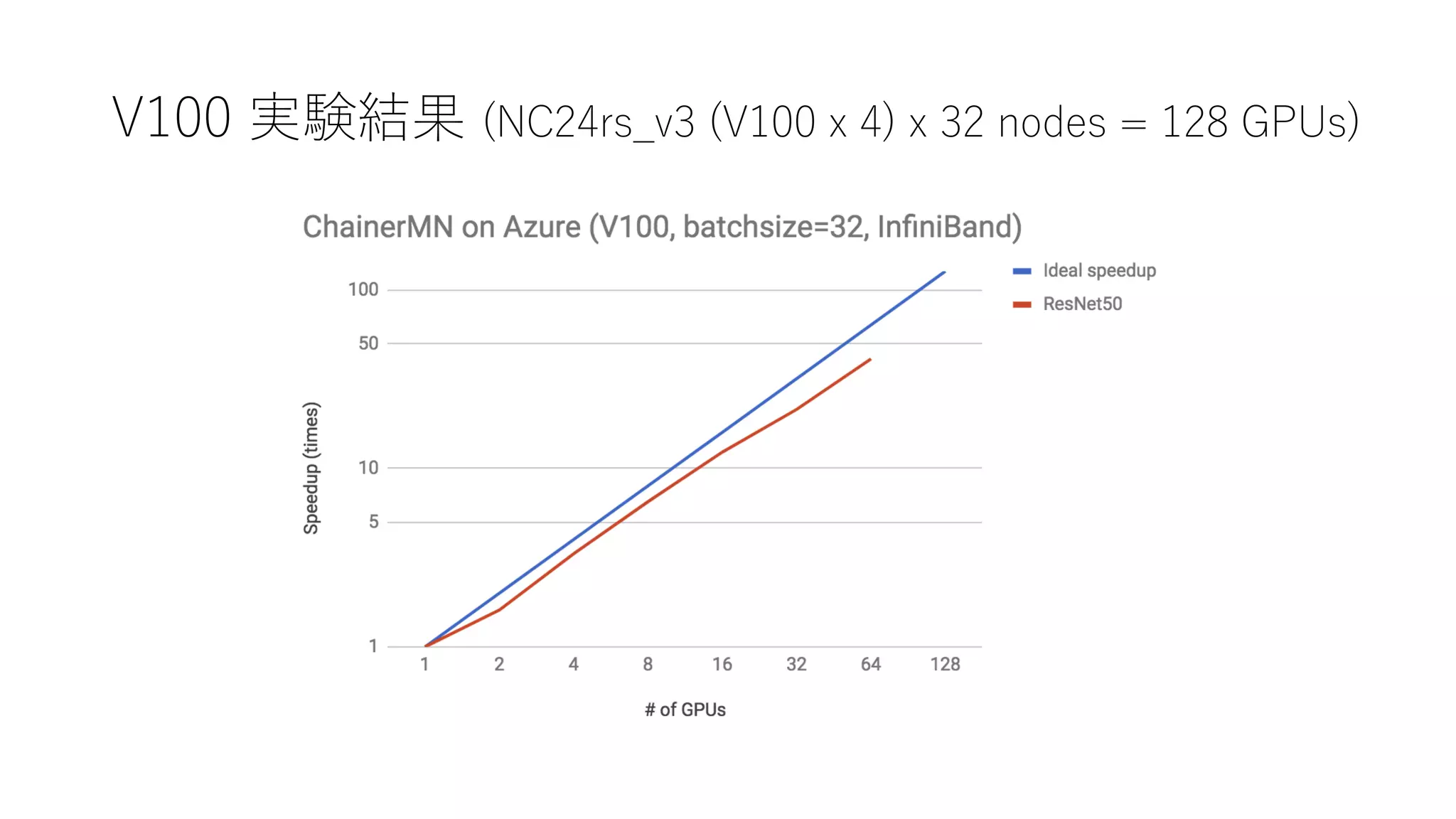
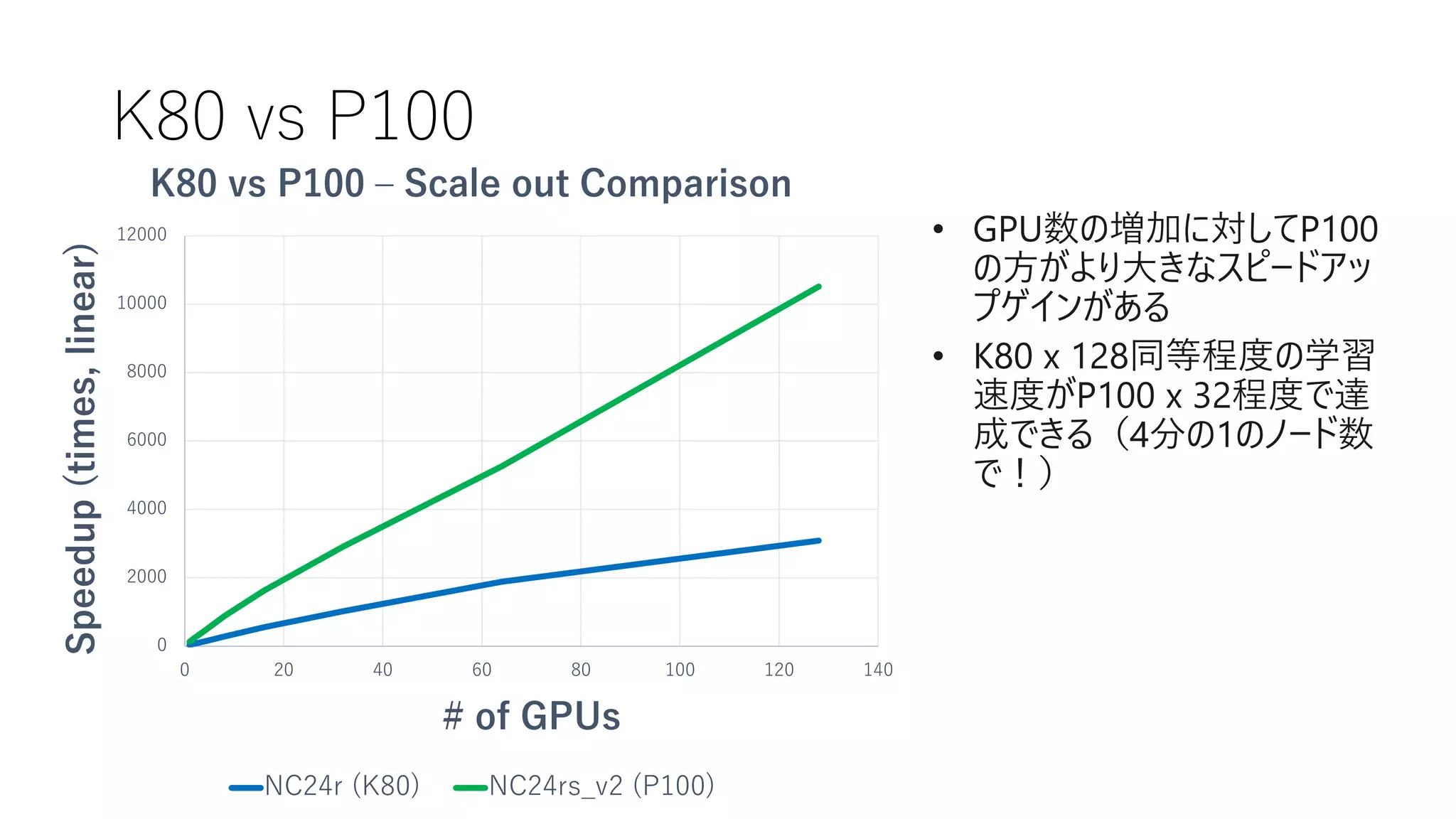
23.
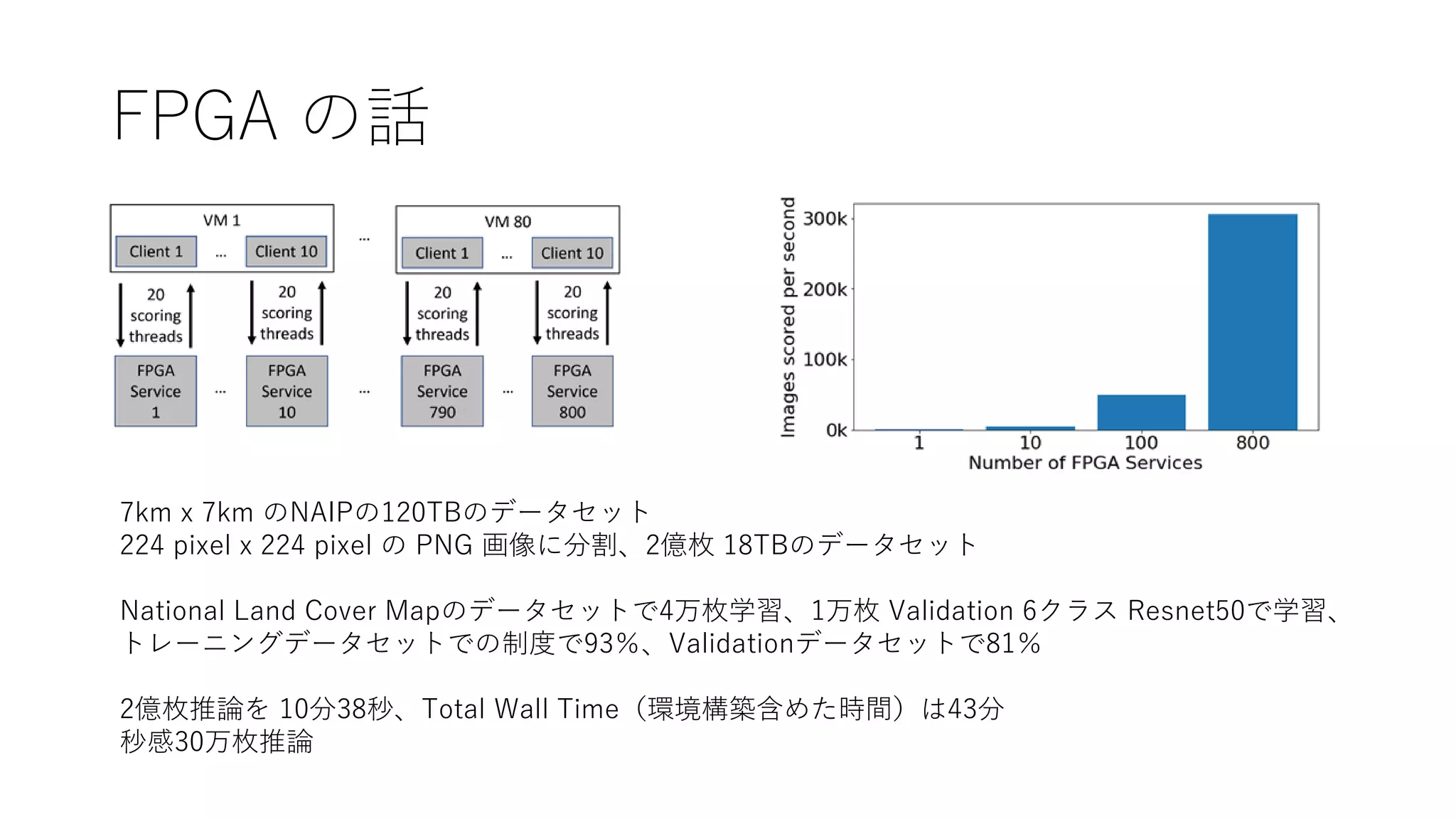
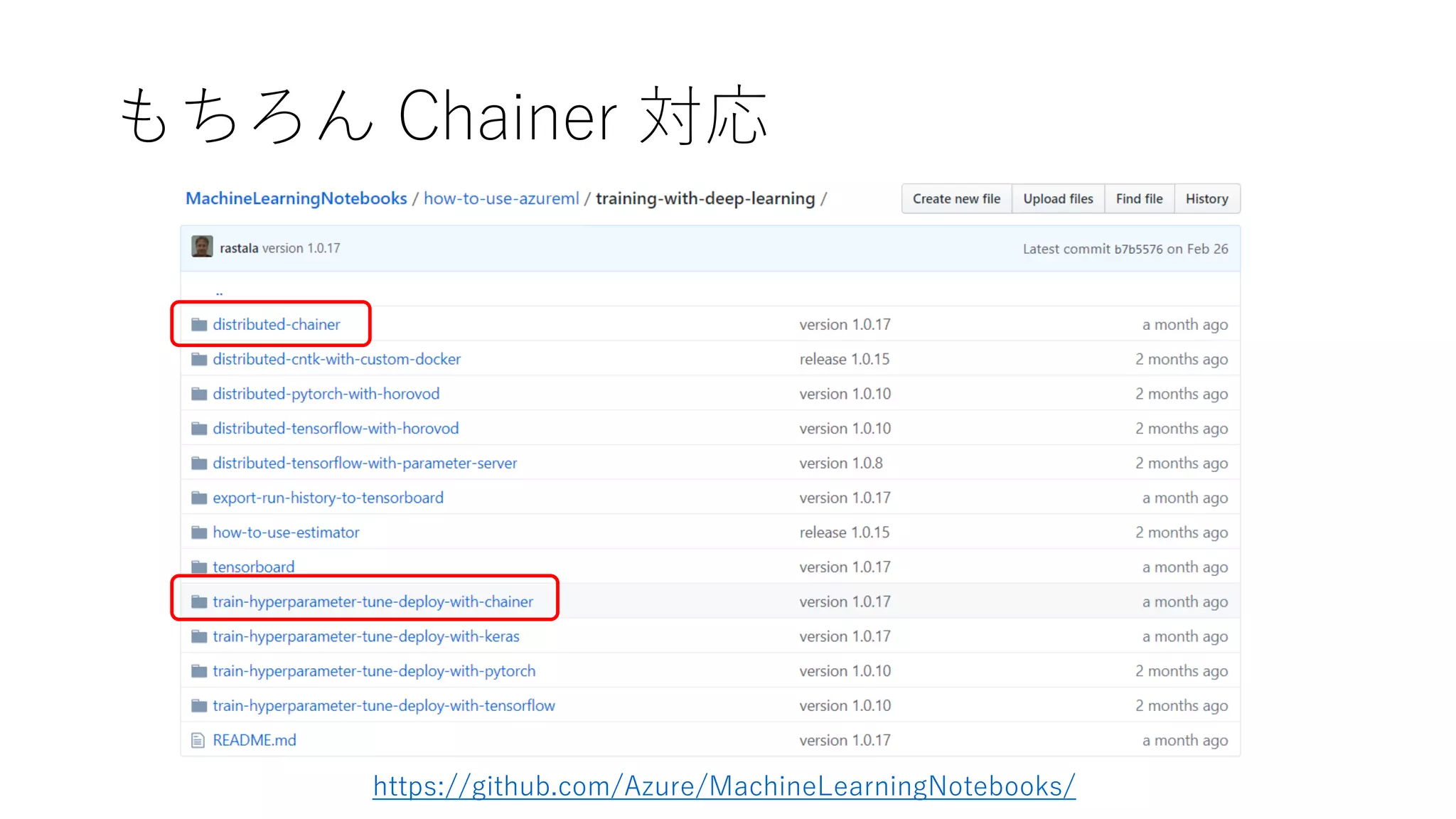
FPGA の話
7km x7km のNAIPの120TBのデータセット
224 pixel x 224 pixel の PNG 画像に分割、2億枚 18TBのデータセット
National Land Cover Mapのデータセットで4万枚学習、1万枚 Validation 6クラス Resnet50で学習、
トレーニングデータセットでの制度で93%、Validationデータセットで81%
2億枚推論を 10分38秒、Total Wall Time(環境構築含めた時間)は43分
秒感30万枚推論
24.
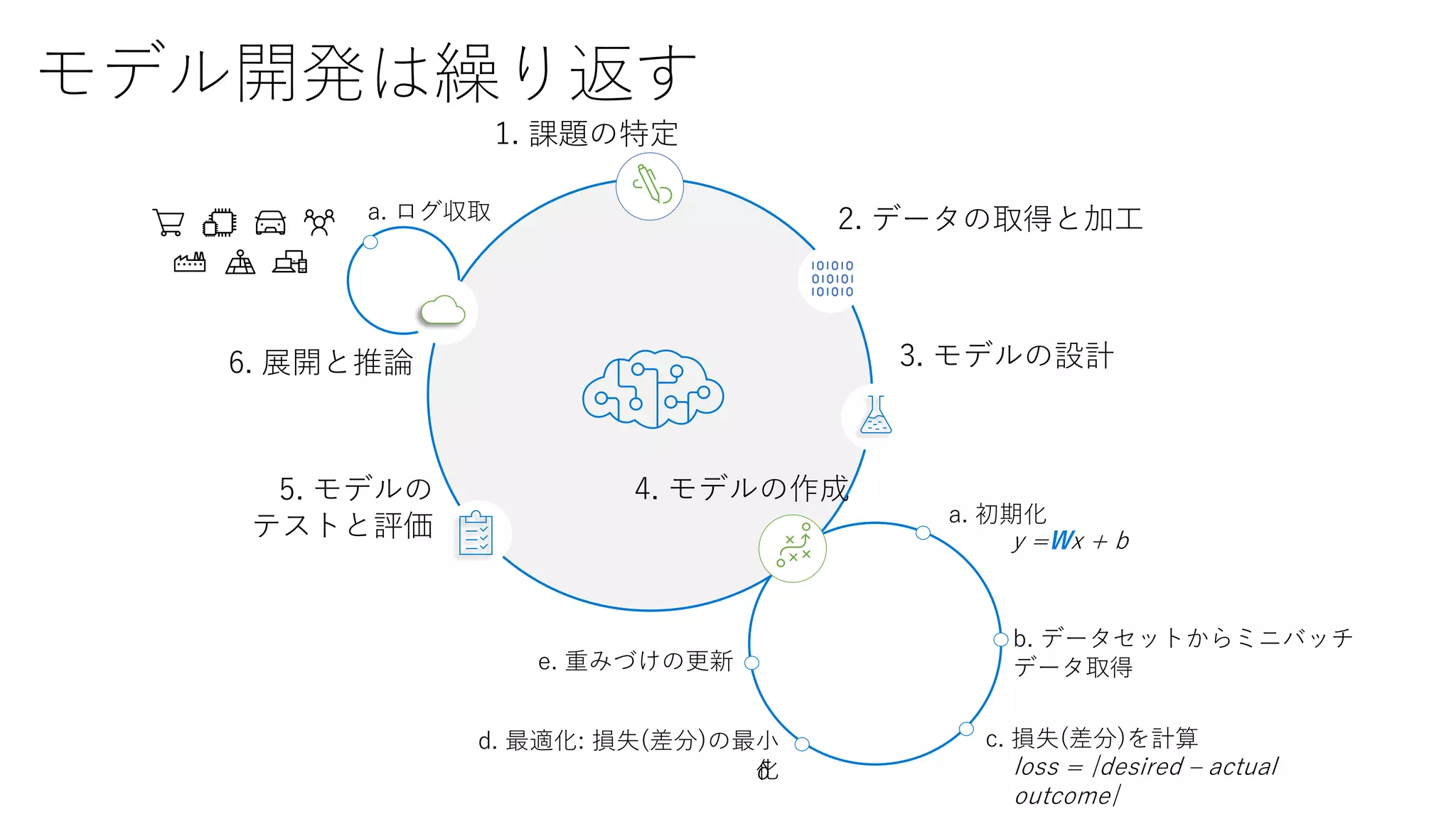
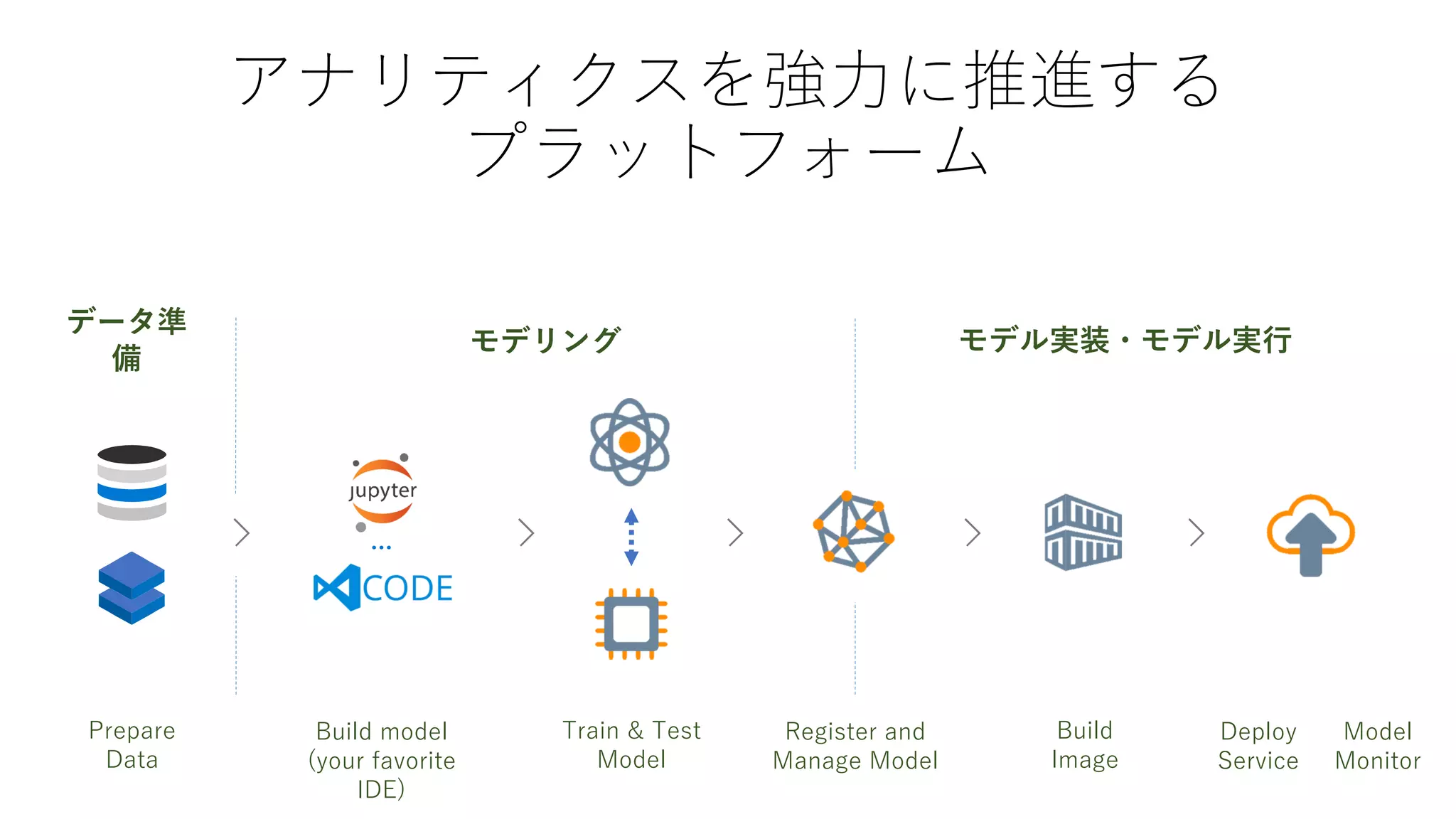
モデル開発は繰り返す
1. 課題の特定
2. データの取得と加工
3.モデルの設計
4. モデルの作成5. モデルの
テストと評価 a. 初期化
b. データセットからミニバッチ
データ取得
c. 損失(差分)を計算d. 最適化: 損失(差分)の最小
化
e. 重みづけの更新
y =Wx + b
loss = |desired – actual
outcome|
δ
6. 展開と推論
a. ログ収取










































![[基調講演] DLL_RealtimeAI](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotesakakibara-180710072423-thumbnail.jpg?width=640&height=640&fit=bounds)




![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)










![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)








































