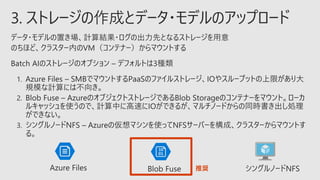
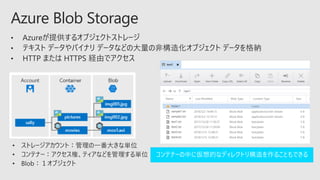
2018年6月27日のDeep Learning Lab MeetUp 学習編 のセッション資料です。Deep Learningに役立つAzureの高度なインフラストラクチャーとトレーニングジョブを簡単かつ大規模に実行できる環境をすぐに提供するBatch AIのご紹介をいたします。














![0
100
200
300
400
500
600
700
800
900
1000
1 10 100 1000 10000
Latency[μsec]
Size [bytes]
SR-IOV
non SR-IOV
0
500
1000
1500
2000
2500
1 100 10000 1000000 100000000 1E+10
Bandwidth[Mbytes/sec]
Size [bytes]
SR-IOV
non SR-IOV](https://image.slidesharecdn.com/dlltraining180627-180627010321/85/Deep-Learning-Lab-MeetUp-Azure-Batch-AI-15-320.jpg)
![1
10
100
1000
1 10 100 1000 10000
Latency[μsec]
Size [bytes]
SR-IOV (DS5_v2)
non SR-IOV (DS5_v2)
InfiniBand FDR (H16r)
0
1000
2000
3000
4000
5000
6000
7000
1 100 10000 1000000 100000000 1E+10
Bandwidth[Mbytes/sec]
Size [bytes]
SR-IOV (DS5_v2)
non SR-IOV (DS5_v2)
InfiniBand FDR (H16r)
InfiniBand
RDMA](https://image.slidesharecdn.com/dlltraining180627-180627010321/85/Deep-Learning-Lab-MeetUp-Azure-Batch-AI-16-320.jpg)












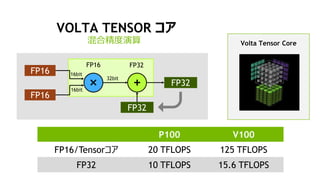


![Resnet50, Imagenet, Batch:128
P100 FP32, V100 FP32 vs. V100 Tensorコア
0 100 200 300 400 500 600
Conv BN Relu Cupy_* Misc.
570 ms
360 ms
197 ms
Time per iteration [ms]
約3倍
P100 FP32
V100 FP32
V100
Tensorコア
(*) Chainer 3.0.0rc1+ と CuPy 2.0.0rc1+ を使用](https://image.slidesharecdn.com/dlltraining180627-180627010321/85/Deep-Learning-Lab-MeetUp-Azure-Batch-AI-32-320.jpg)












![0
50
100
150
200
250
Azure Files Blob Fuse
実行時間[min]](https://image.slidesharecdn.com/dlltraining180627-180627010321/85/Deep-Learning-Lab-MeetUp-Azure-Batch-AI-50-320.jpg)


















![[基調講演] DLL_RealtimeAI](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotesakakibara-180710072423-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)





![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Azure Antenna] クラウドで HPC ~ HPC on Azure ~](https://cdn.slidesharecdn.com/ss_thumbnails/hpconazure111282017-171206080933-thumbnail.jpg?width=640&height=640&fit=bounds)

