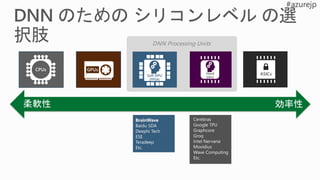
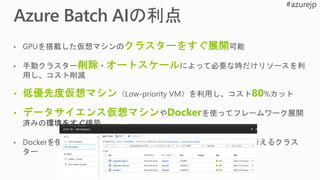
DNN Processing Units
効率性柔軟性
SoftDPU
(FPGA)
Contro
l Unit
(CU)
Registers
Arithmeti
c Logic
Unit
(ALU)
CPUs GPUs
ASICsHard
DPU
Cerebras
Google TPU
Graphcore
Groq
Intel Nervana
Movidius
Wave Computing
Etc.
BrainWave
Baidu SDA
Deephi Tech
ESE
Teradeep
Etc.
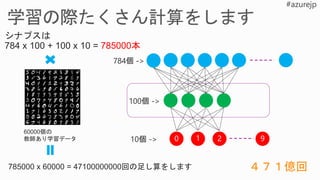
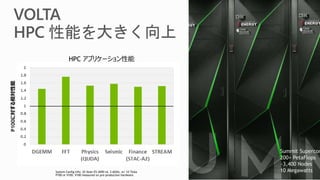
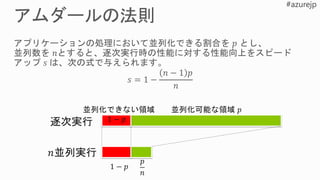
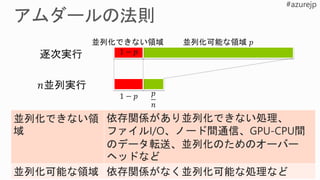
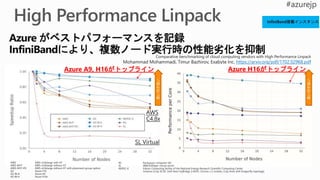
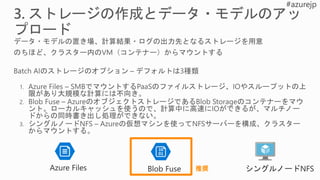
5.
0 1 2
784x 100 + 100 x 10 = 785000本
9
60000個の
教師あり学習データ
785000 x 60000 = 47100000000回の足し算をします 471億回
8.
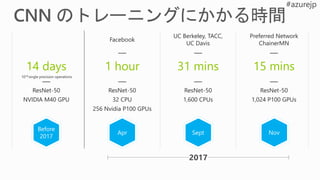
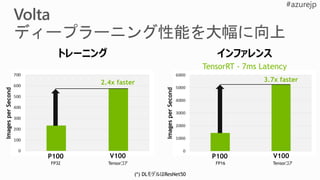
14 days 1hour 31 mins 15 mins
Before
2017
Apr Sept Nov
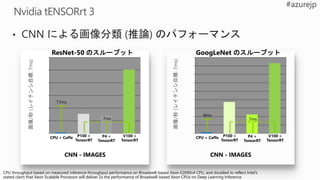
ResNet-50
NVIDIA M40 GPU
ResNet-50
32 CPU
256 Nvidia P100 GPUs
ResNet-50
1,600 CPUs
ResNet-50
1,024 P100 GPUs
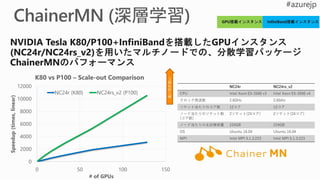
Facebook
UC Berkeley, TACC,
UC Davis
Preferred Network
ChainerMN
1018 single precision operations
2017
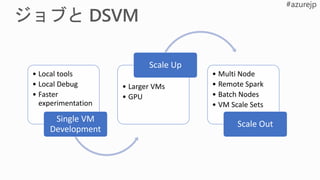
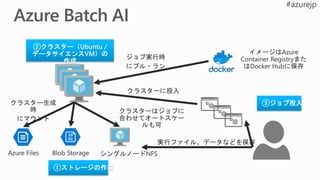
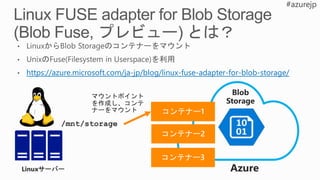
• Local tools
•Local Debug
• Faster
experimentation
Single VM
Development
• Larger VMs
• GPU
Scale Up
• Multi Node
• Remote Spark
• Batch Nodes
• VM Scale Sets
Scale Out
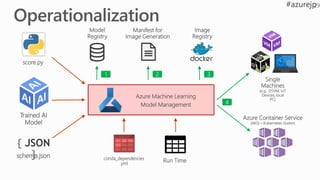
Trained AI
Model
score.py
{ JSON
}schema.jsonconda_dependencies
.yml
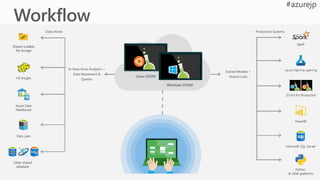
Azure Machine Learning
Model Management
Run Time
Model
Registry
Image
Registry
Manifest for
Image Generation
Single
Machines
(e.g.. DSVM, IoT
Devices, local
PC)
Azure Container Service
(AKS) – Kubernetes clusters
4
1 2 3






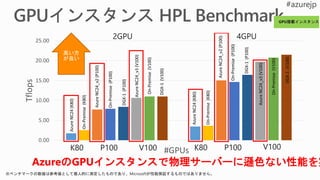
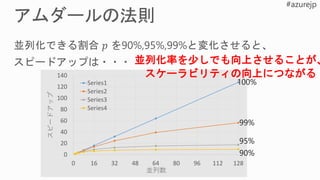
![0 100 200 300 400 500 600
Series1 Series2 Series3 Series4 Series5
570 ms
360 ms
197 ms
Time per iteration [ms]
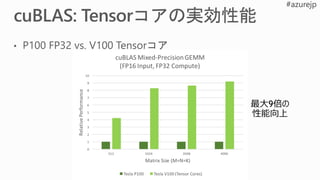
約3倍
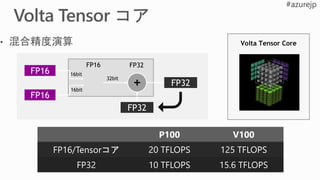
P100 FP32
V100 FP32
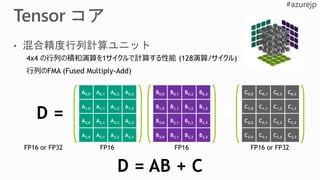
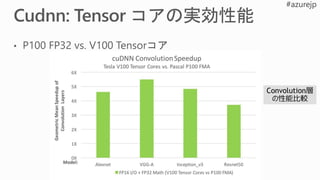
V100
Tensorコア
(*) Chainer 3.0.0rc1+ と CuPy 2.0.0rc1+ を使用](https://image.slidesharecdn.com/tyricknjstmncke4yqgj-signature-7860a24a0e75dae417bb966214437644b6bc2bca798c24222d2caabbfa00f526-poli-180918214047/85/Deep-Learning-4-GPU-20-320.jpg)





![0
100
200
300
400
500
600
700
800
900
1000
1 10 100 1000 10000
Latency[μsec]
Size [bytes]
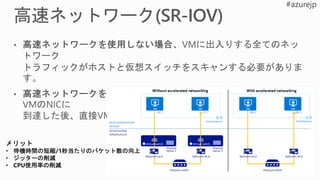
SR-IOV
non SR-IOV
0
500
1000
1500
2000
2500
1 100 10000 1000000 100000000 1E+10
Bandwidth[Mbytes/sec]
Size [bytes]
SR-IOV
non SR-IOV](https://image.slidesharecdn.com/tyricknjstmncke4yqgj-signature-7860a24a0e75dae417bb966214437644b6bc2bca798c24222d2caabbfa00f526-poli-180918214047/85/Deep-Learning-4-GPU-36-320.jpg)
![1
10
100
1000
1 10 100 1000 10000
Latency[μsec]
Size [bytes]
SR-IOV (DS5_v2)
non SR-IOV (DS5_v2)
InfiniBand FDR (H16r)
0
1000
2000
3000
4000
5000
6000
7000
1 100 10000 1000000 100000000 1E+10
Bandwidth[Mbytes/sec]
Size [bytes]
SR-IOV (DS5_v2)
non SR-IOV (DS5_v2)
InfiniBand FDR (H16r)
InfiniBand
RDMA](https://image.slidesharecdn.com/tyricknjstmncke4yqgj-signature-7860a24a0e75dae417bb966214437644b6bc2bca798c24222d2caabbfa00f526-poli-180918214047/85/Deep-Learning-4-GPU-37-320.jpg)








![0
50
100
150
200
250
1 2
実行時間[min]](https://image.slidesharecdn.com/tyricknjstmncke4yqgj-signature-7860a24a0e75dae417bb966214437644b6bc2bca798c24222d2caabbfa00f526-poli-180918214047/85/Deep-Learning-4-GPU-56-320.jpg)









![[Cloud OnAir] Bigtable に迫る!基本機能も含めユースケースまで丸ごと紹介 2018年8月30日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1111111-180830075720-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)


































