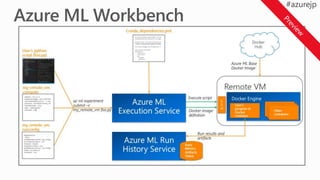
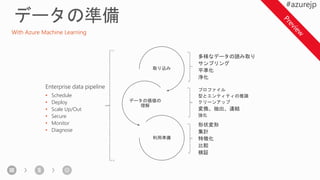
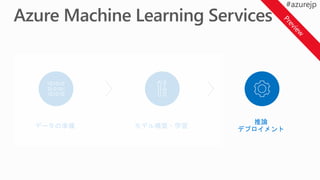
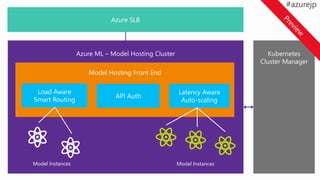
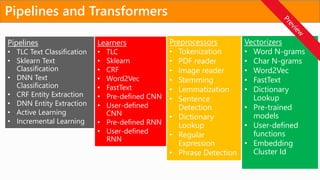
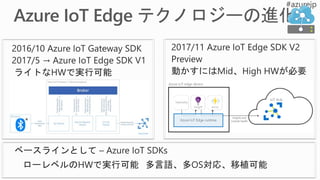
Training options inAzure Machine Learning
AMLWB
1
2 Train model
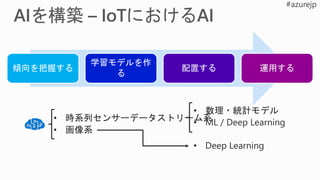
Training and testing (model management):
• Vienna Python (3.5.2) environment on local machine
• A conda Python environment inside of a Docker container
on local/remote VM
• A Spark cluster such as Spark for HDInsight Spark on Azure
ML model
pickle.dump(myModel,
open('./model.pkl', 'wb'))
Local or remote VM
Apache
Spark for
Azure HDI
BAIT
Azure Batch AI Training
Azure Batch AI training (BAIT)
- managed Azure Batch
- parallel and distributed computing
- clusters of GPU compute nodes
Data From
AOI Machines
Deployment
3
18.
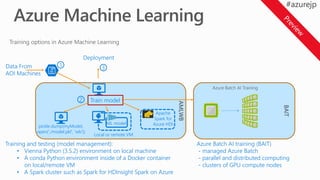
Training options inAzure Machine Learning
AMLWB
1
2 Train model
1. Pipeline development (CPU VM)
ML model
pickle.dump(myModel,
open('./model.pkl', 'wb'))
Local or remote VM
Apache
Spark for
Azure HDI
BAIT
Azure Batch AI Training
Data From
AOI Machines
Deployment
3
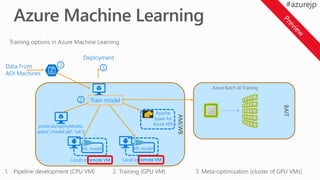
ML model
Local or remote VM
2. Training (GPU VM) 3. Meta-optimization (cluster of GPU VMs)
Azure Blob
Storage
Azure Machine
LearningModel
Management Service
GPU Data Science
Virtual Machine
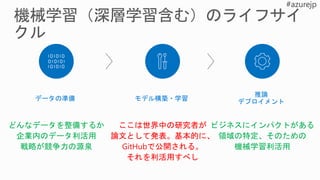
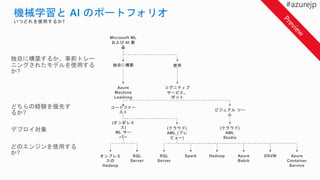
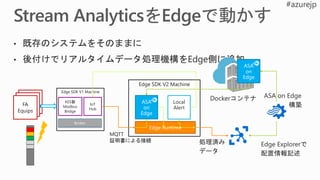
機械学習モデル
Java ETL
Azure Container
Registry
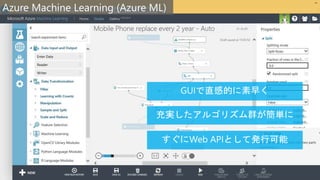
予測的 Web アプリケーション
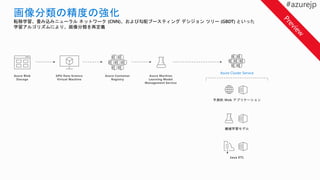
転移学習、畳み込みニューラル ネットワーク (CNN)、および勾配ブースティング デシジョン ツリー (GBDT) といった
学習アルゴリズムにより、画像分類を再定義
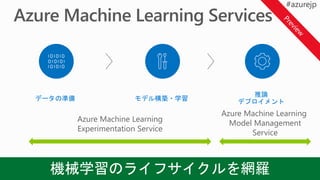
Azure Cluster Service
21.
Azure Container
Service
Azure Machine
Learning
AzureGPU Data Science Virtual Machine
Web アプリ
(Jupyter Notebook)
Workbench Experimentation
Service
Microsoft
SQL Server
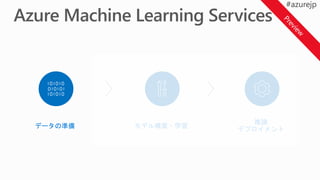
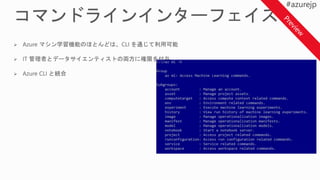
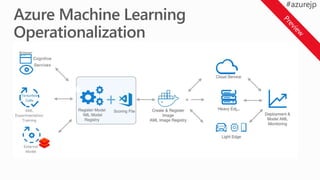
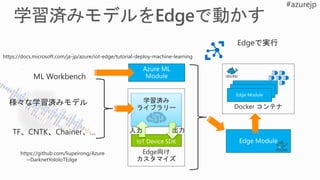
Azure Machine Learning
Operationalization
クラスター
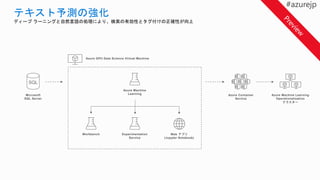
ディープ ラーニングと自然言語の処理により、検索の有効性とタグ付けの正確性が向上
SQL
HDInsight
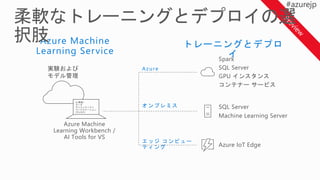
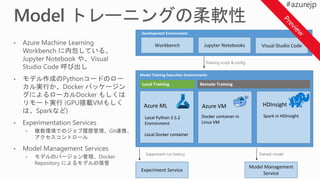
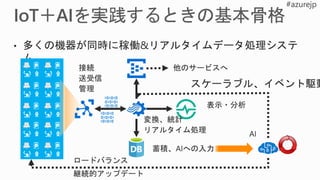
Model Training ExecutionEnvironments
Spark in HDInsight
Azure VM
Remote Training
Docker container in
Linux VM
Local Training
Azure ML
Local Python 3.5.2
Environment
Local Docker container
Experiment Service
Model Management
Service
Workbench Jupyter Notebooks Visual Studio Code
Development Environment
#
# Pattern toinvoke Azure ML Logger to record metrics.
#
# Import Azure ML Logger library
from azureml.logging import get_azureml_logger
# Create a new instance of the logger
run_logger = get_azureml_logger()
# log a value (associated to a given experiment and project)
run_logger.log("key", value)
# log an array of values (associated to a given run)
run_logger.log("Actual",
[testlabel[i] for i in range(len(testlabel))[0::100]])
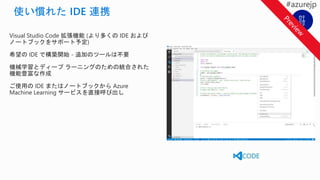
38.
Visual Studio Code拡張機能 (より多くの IDE および
ノートブックをサポート予定)
希望の IDE で構築開始 - 追加のツールは不要
機械学習とディープ ラーニングのための統合された
機能豊富な作成
ご使用の IDE またはノートブックから Azure
Machine Learning サービスを直接呼び出し
44.
Training pipeline steps:
1.Provision VMs
use portal or CLI
(https://github.com/Azure/DataScienceVM/tree/master/Scripts/CreateDSVM/Ubuntu)
45.
Training pipeline steps:
1.Provision VMs
2. Provision and attach data disk
attach disk to DSVM
https://docs.microsoft.com/en-us/azure/virtual-machines/linux/add-disk?toc=%2fazure%2fvirtual-machines%2flinux%2ftoc.json
az vm disk attach -g someRSG --vm-name someVM --disk aDisk --new --size-gb 200
Or, if you do not need the data after you destroy the VM (preferred scenario when working with external
clients data), simply resize DSVM disks on portal (turned off DSVM).
46.
Training pipeline steps:
1.Provision VMs
2. Provision and attach data disk
3. Get Data
azcopy --source {dataBlob}
--destination {DataBaseInputDir}
--source-key {sourceKey} –recursive
47.
Training pipeline steps:
1.Provision VMs
2. Provision and attach data disk
3. Get Data
Data is accessible within docker container and on the host
import os
try:
amlWBSharedDir = os.environ['AZUREML_NATIVE_SHARE_DIRECTORY']
except:
amlWBSharedDir = '/datadrive01/somesharedDir/expAccnt/amlws/projectName'
48.
Training pipeline steps:
1.Provision VMs
2. Provision and attach data disk
3. Get Data
4. Futurize images using a pretrained Deep Learning model
model = ResNet50()
img = image.load_img(fname, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
features = model.predict_on_batch(np.concatenate(load_img)).squeeze()
features.shape
(1, 2048)
49.
Training pipeline steps:
1.Provision VMs
2. Provision and attach data disk
3. Get Data
4. Featurize images using a pretrained Deep Learning model
5. Train lightGBM model
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_test = lgb.Dataset(X_test, y_test, reference=lgb_train, free_raw_data=False)
clf = lgb.train(params, lgb_train, num_boost_round=500)
y_pred_proba = clf.predict(X_test)
y_pred = binarize_prediction(y_pred_proba)
clf.save_model(path.join(JABIL_ROOT, MODEL_NAME))
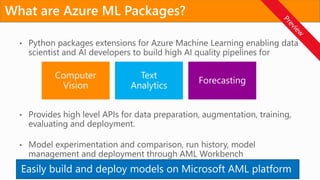
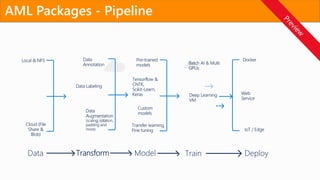
Easily build anddeploy models on Microsoft AML platform
What are Azure ML Packages?
60.
Accurate
Packages support Stateof the Art algorithms and include
optimized parameters to provide out of the box highly
accurate models.
Flexible
Powerful and composable Python API. Optimize the best
algorithm for your application. Provides control over all
the aspects that are available to the power user.
Scalable
Train models at petabyte scale with multi GPU
Time to Solution
Automates many tedious tasks (data alignment, cleaning
and preparation), easily model experimentations and
deploy in production.
Value
Proposition
Best in class package in Quality, Flexibility, Scale and Time to solution.
66
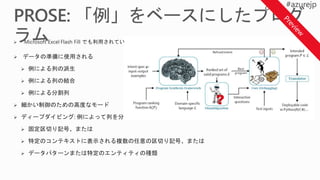
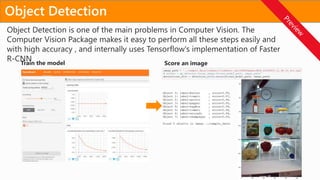
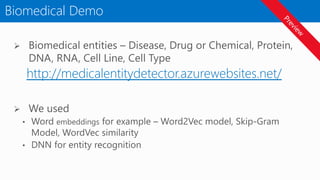
The evaluation moduleprovides functionality to evaluate the
performance of the trained model. Some of the evaluation
metrics : accuracy, precision and recall, confusion matrix
Prepare Dataset
Evaluate the model
Score the model
Image Classification
Model Definition & Training
Deploy the model
Deploy the model as an Azure web service,
Dockers Container or IoT Edge
High Accuracy outof the box
Include optimized parameters and pre trained weights to
provide out of the box highly accurate models.
Computer Vision Simplified in Python
Time To Solution
Get from a data set to a highly accurate deployed model
quickly
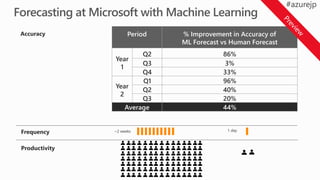
Period % Improvementin Accuracy of
ML Forecast vs Human Forecast
Year
1
Q2 86%
Q3 3%
Q4 33%
Year
2
Q1 96%
Q2 40%
Q3 20%
Average 44%
78.
Easily build anddeploy highly accurate forecasting models
on the Microsoft AI Platform
Azure Machine Learning Package For
Forecasting
79.
Modeling
- Seasonal Naive
-ARIMA
- ETS
- RecursiveForecaster
- RegressionForecaster
- SklearnEstimator
Time Series AutoML
- RollingOriginValidator
- TSGridSearch (models,
params)
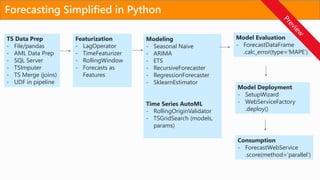
TS Data Prep
- File/pandas
- AML Data Prep
- SQL Server
- TSImputer
- TS Merge (joins)
- UDF in pipeline
Featurization
- LagOperator
- TimeFeaturizer
- RollingWindow
- Forecasts as
Features
Model Deployment
- SetupWizard
- WebServiceFactory
.deploy()
Consumption
- ForecastWebService
.score(method=‘parallel’)
Model Evaluation
- ForecastDataFrame
.calc_error(type=‘MAPE’)
Forecasting Simplified in Python
80.
RAPID TIME TOSOLUTION
~3-10X fewer lines of code than scikit
FLEXIBLE
Time series specific transforms compatible
with scikit
Forecasting Simplified in Python
Simple forecaster in 5 lines of code
Deployment in 1 line of code
Incorporate transforms and models from
scikit
Build your own transforms and run your
own models
ENTERPRISE SCALE
Forecast experimentation and model
deployment at scale
Scale complex time series cross-
validation and hyperparameter sweeps
Run forecasters as web services
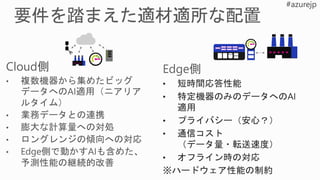
Cloud: Azure 高機能Edge 軽量 Edge
概要
An Azure host that
spans from CPU to GPU
and FPGA VMs
A server with slots to insert CPUs, GPUs, and FPGAs or a x64 or
ARM system that needs to be plugged in to work
A Sensor with a SoC
(ARM CPU, DSPs)
and memory that can
operate on batteries
CPU
CPU,GPU or Arria 10
FPGA
Arria 10
FPGA
NVIDIA GPU x64 CPU ARM CPU
HW accelerated
DSP,CPU,GPU
モデルパッケー
ジ
Native to Windows
and container elsewhere
Windows
Native
- Linux
container
- Windows ML
- Linux
container
- Windows ML
- Linux
container
- (Ideally) container
- Android Native
- iOS Native
- RT OS










![月曜日-金曜日: 7:00 午前-6:00pm、土曜日: 9:00 am-5:00午後、日曜日: 定休日
Timings_1 Timings_2 Timings_3 Timings_4 Timings_5 Timings_6 Timings_7 Timings_8 Timings_9
月曜日 金曜日 7:00 am 6:00 pm 土曜日 9:00 am 5:00 pm 日曜日 閉じ
192.128.138.20-[2016 年10月16日 16:22:33-0200] "GET/images/picture.gif HTTP/1.1" 234 343 www.yahoo.com
"Http://www.example.com/"" Mozilla/4.0 (互換性;MSIE 4) ""-"
logtext_1 logtext_2 logtext_3 logtext_4 logtext_5 logtext_6 logtext_7 logtext_8
192.128.138.20 2016年10月16日 16:22:33 -0200 取得 画像/画像. gif http 1.1](https://image.slidesharecdn.com/xqwbcduhs0g0y0fuvtnj-signature-7fe520ac26b911a73ed61213935d47e0327a8766a09e9a590a82e08d2363409b-poli-180918214308/85/Deep-Learning-5-Tool-29-320.jpg)


![#
# Pattern to invoke Azure ML Logger to record metrics.
#
# Import Azure ML Logger library
from azureml.logging import get_azureml_logger
# Create a new instance of the logger
run_logger = get_azureml_logger()
# log a value (associated to a given experiment and project)
run_logger.log("key", value)
# log an array of values (associated to a given run)
run_logger.log("Actual",
[testlabel[i] for i in range(len(testlabel))[0::100]])](https://image.slidesharecdn.com/xqwbcduhs0g0y0fuvtnj-signature-7fe520ac26b911a73ed61213935d47e0327a8766a09e9a590a82e08d2363409b-poli-180918214308/85/Deep-Learning-5-Tool-37-320.jpg)







![Training pipeline steps:
1. Provision VMs
2. Provision and attach data disk
3. Get Data
Data is accessible within docker container and on the host
import os
try:
amlWBSharedDir = os.environ['AZUREML_NATIVE_SHARE_DIRECTORY']
except:
amlWBSharedDir = '/datadrive01/somesharedDir/expAccnt/amlws/projectName'](https://image.slidesharecdn.com/xqwbcduhs0g0y0fuvtnj-signature-7fe520ac26b911a73ed61213935d47e0327a8766a09e9a590a82e08d2363409b-poli-180918214308/85/Deep-Learning-5-Tool-47-320.jpg)






































![[基調講演] DLL_RealtimeAI](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotesakakibara-180710072423-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AI05] 目指せ、最先端 AI 技術の実活用!Deep Learning フレームワーク 「Microsoft Cognitive Toolkit 」...](https://cdn.slidesharecdn.com/ss_thumbnails/ai05-170602095345-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~](https://cdn.slidesharecdn.com/ss_thumbnails/20181117devfestasapporoazureaipublic-181119035506-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Japan Tech summit 2017] MAI 003](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai003-171116035458-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Microsoft Tech Summit 2018] Azure Machine Learning サービスと Azure Databricks で実...](https://cdn.slidesharecdn.com/ss_thumbnails/20181107techsummitazuremldatabricks-181108015121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第50回 Machine Learning 15minutes! Broadcast] Azure Machine Learning - Ignite ...](https://cdn.slidesharecdn.com/ss_thumbnails/20201205ml15minazuremlignite-201205101214-thumbnail.jpg?width=640&height=640&fit=bounds)





















