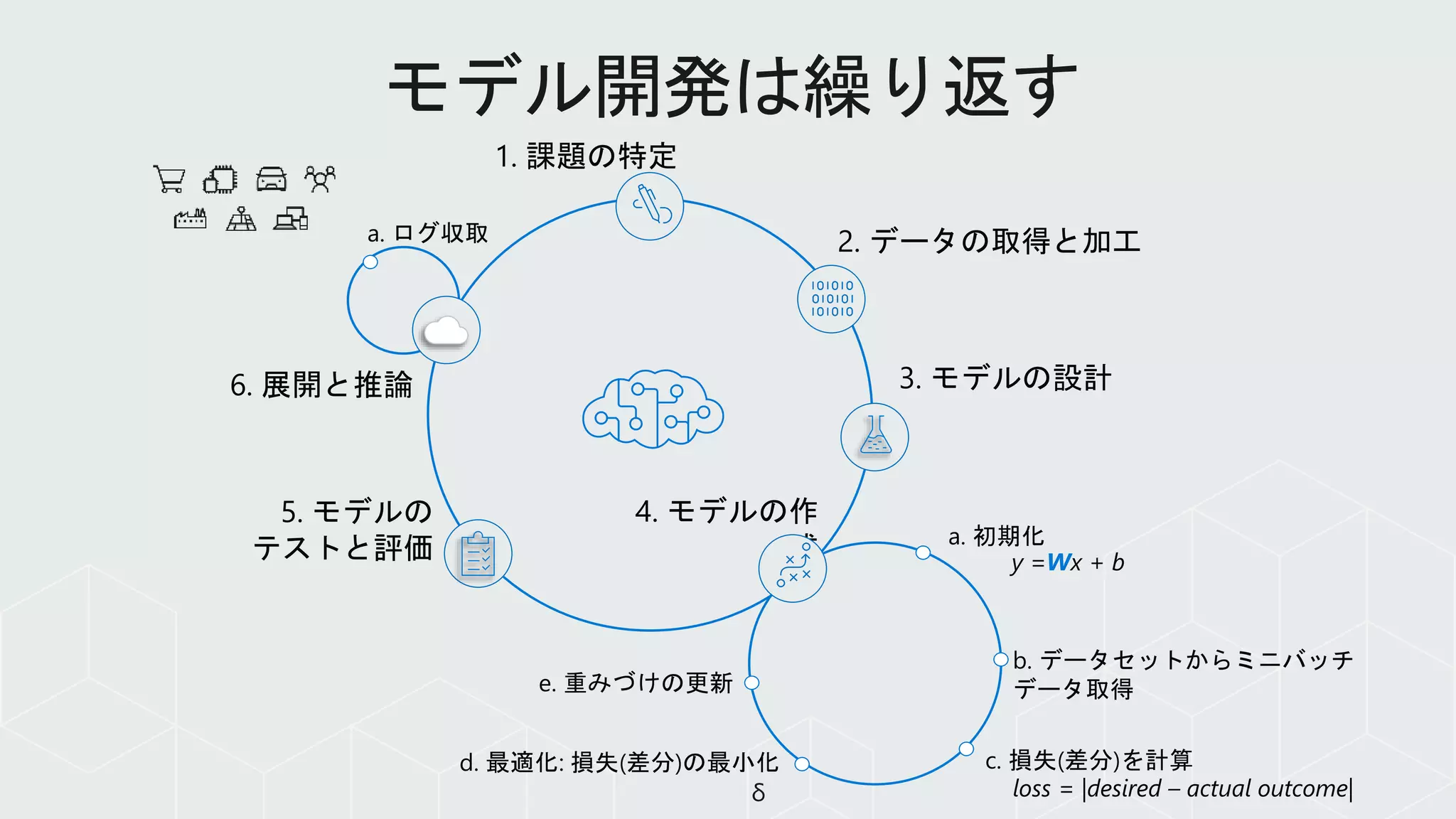
1. 課題の特定
2. データの取得と加工
3.モデルの設計
4. モデルの作
成
5. モデルの
テストと評価 a. 初期化
b. データセットからミニバッチ
データ取得
c. 損失(差分)を計算d. 最適化: 損失(差分)の最小化
e. 重みづけの更新
y =Wx + b
loss = |desired – actual outcome|δ
6. 展開と推論
a. ログ収取
9.
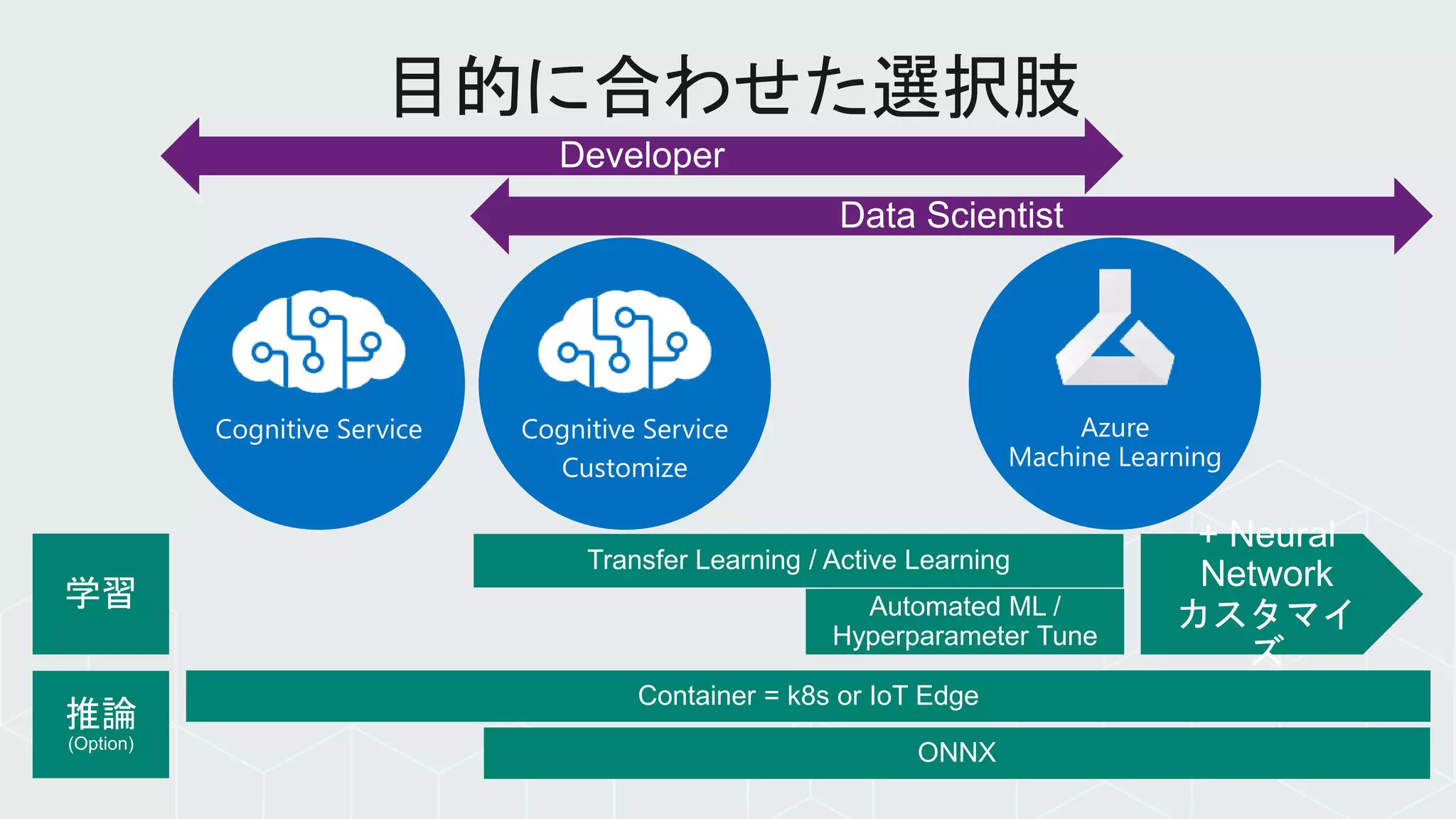
精度
プログラミ
ング
機械学習
アプローチ 演繹的 帰納的。つまりブラックボックスは
残る
機能保証(≒ 精度):
Function Test
可能 訓練データ次第。ただ、統計の域を
出ない
性能保証:
Performance Test
可能 可能
妥当性確認試験:
Validation Test
可能 やってみないと、わからない
https://www.slideshare.net/hironojumpei/ai-129527593
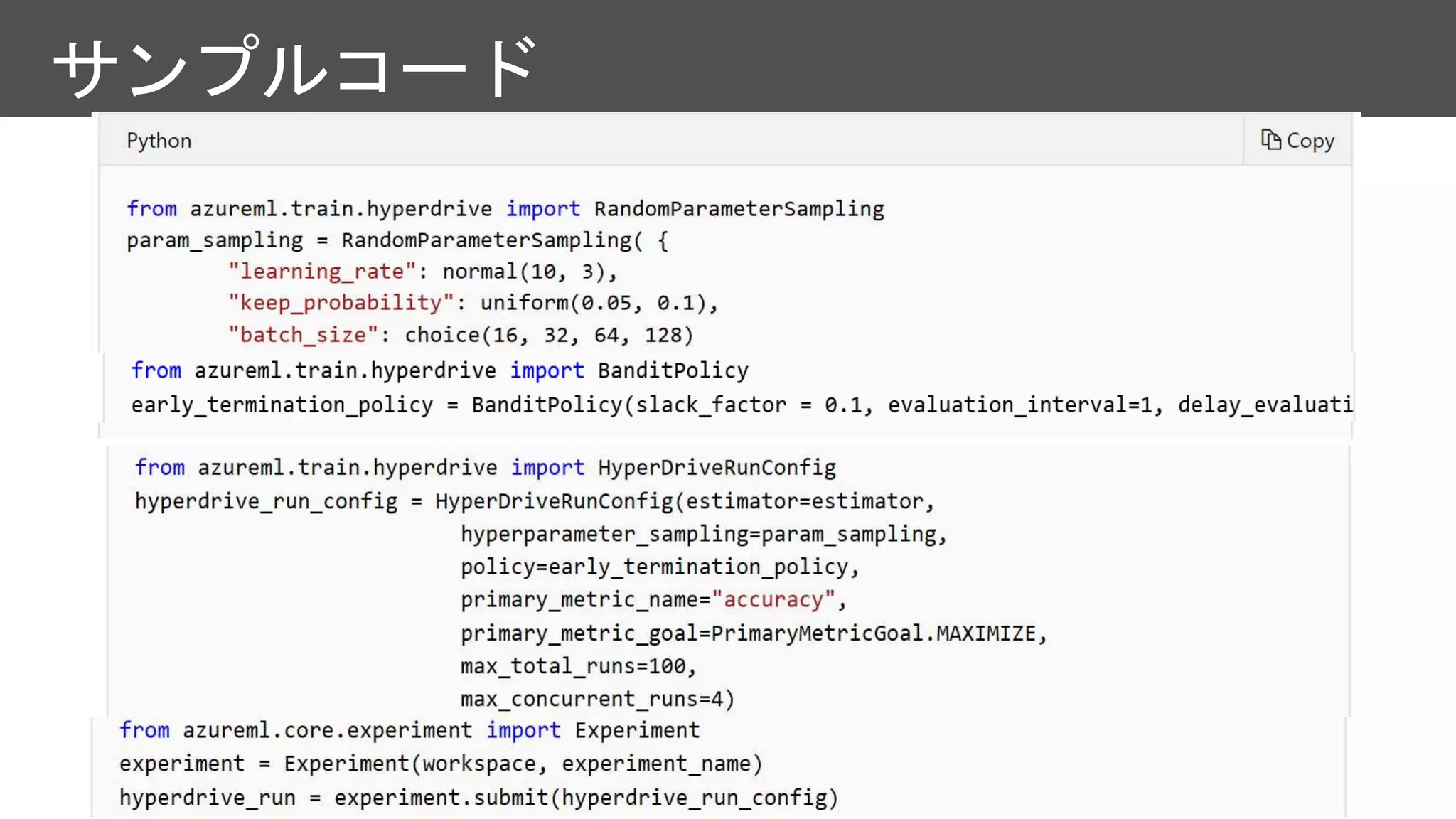
import
'--batch-size' type int
'batch_size''mini
batch size for training'
'--epoch' type int
'epoch' 'epoch size
for training’
from import
'--data-folder' 'mnist'
'--batch-size' 50
'--epoch' 20
'--first-layer-neurons' 300
'--second-layer-neurons' 100
'--learning-rate' 0.001
'--activation'
'--optimizer'
'--loss'
'--dropout' 0.2
'--gpu'
'keras' 'matplotlib'
‘train.py'
True
1800
#2. Script Folder
'./keras-mnist'
True
import
‘./train.py'
'./utils.py'
Docker Image
Data Store
25.
from import
# startan Azure ML run
class LogRunMetrics
# callback at the end of every epoch
def on_epoch_end
# log a value repeated which creates a list
'Loss' 'loss'
'Accuracy' 'acc'
2
Experiment
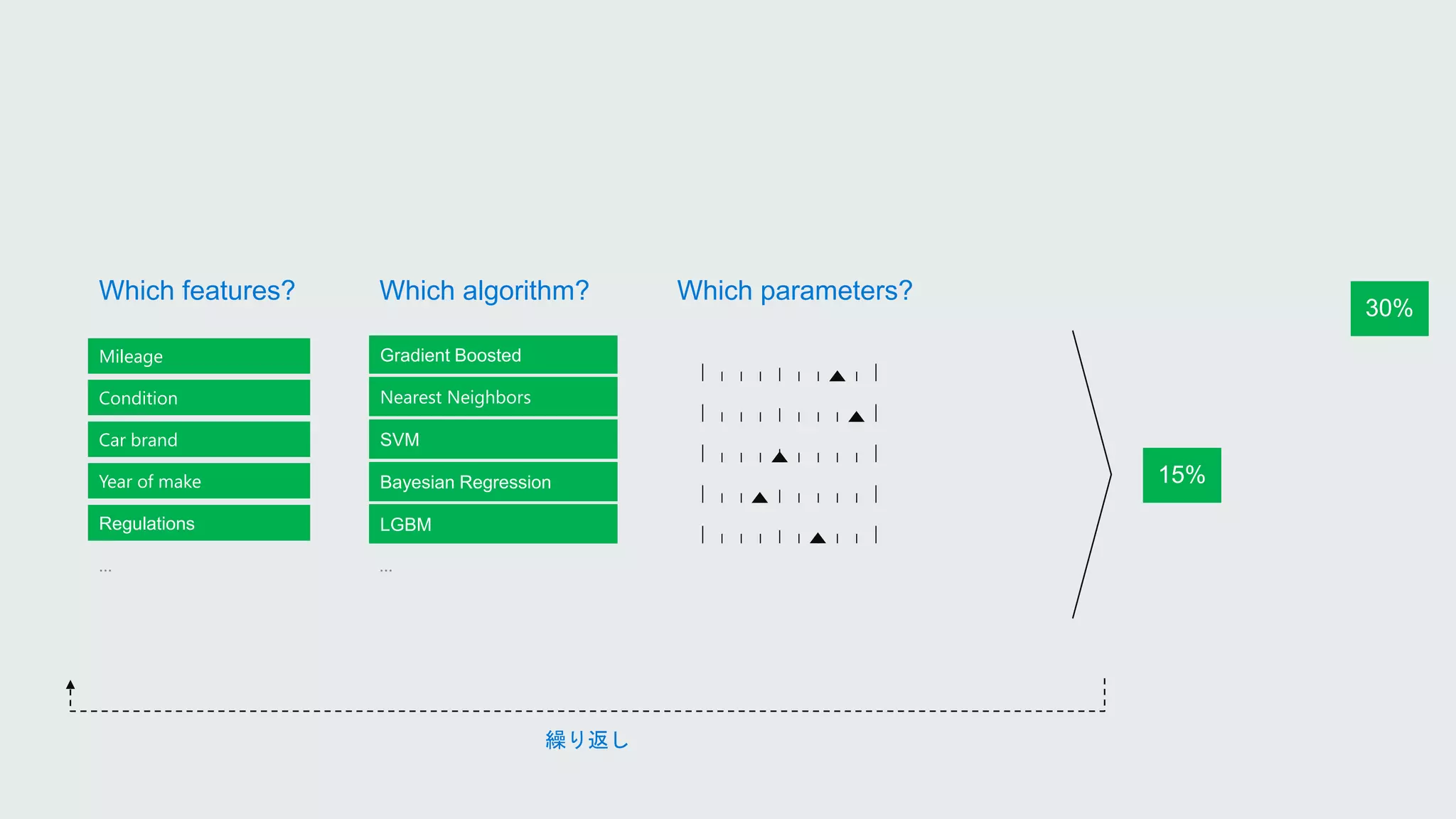
Mileage
Condition
Car brand
Year ofmake
Regulations
…
Parameter 1
Parameter 2
Parameter 3
Parameter 4
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Mileage Gradient Boosted Criterion
Loss
Min Samples Split
Min Samples Leaf
Others Model
Which algorithm? Which parameters?Which features?
Car brand
Year of make
試行錯誤
29.
Criterion
Loss
Min Samples Split
MinSamples Leaf
Others
N Neighbors
Weights
Metric
P
Others
Which algorithm? Which parameters?Which features?
Mileage
Condition
Car brand
Year of make
Regulations
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Nearest Neighbors
Model
繰り返し
Gradient BoostedMileage
Car brand
Year of make
Car brand
Year of make
Condition
30.
Mileage
Condition
Car brand
Year ofmake
Regulations
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Gradient Boosted
SVM
Bayesian Regression
LGBM
Nearest Neighbors
Which algorithm? Which parameters?Which features?
繰り返し
Regulations
Condition
Mileage
Car brand
Year of make
Model
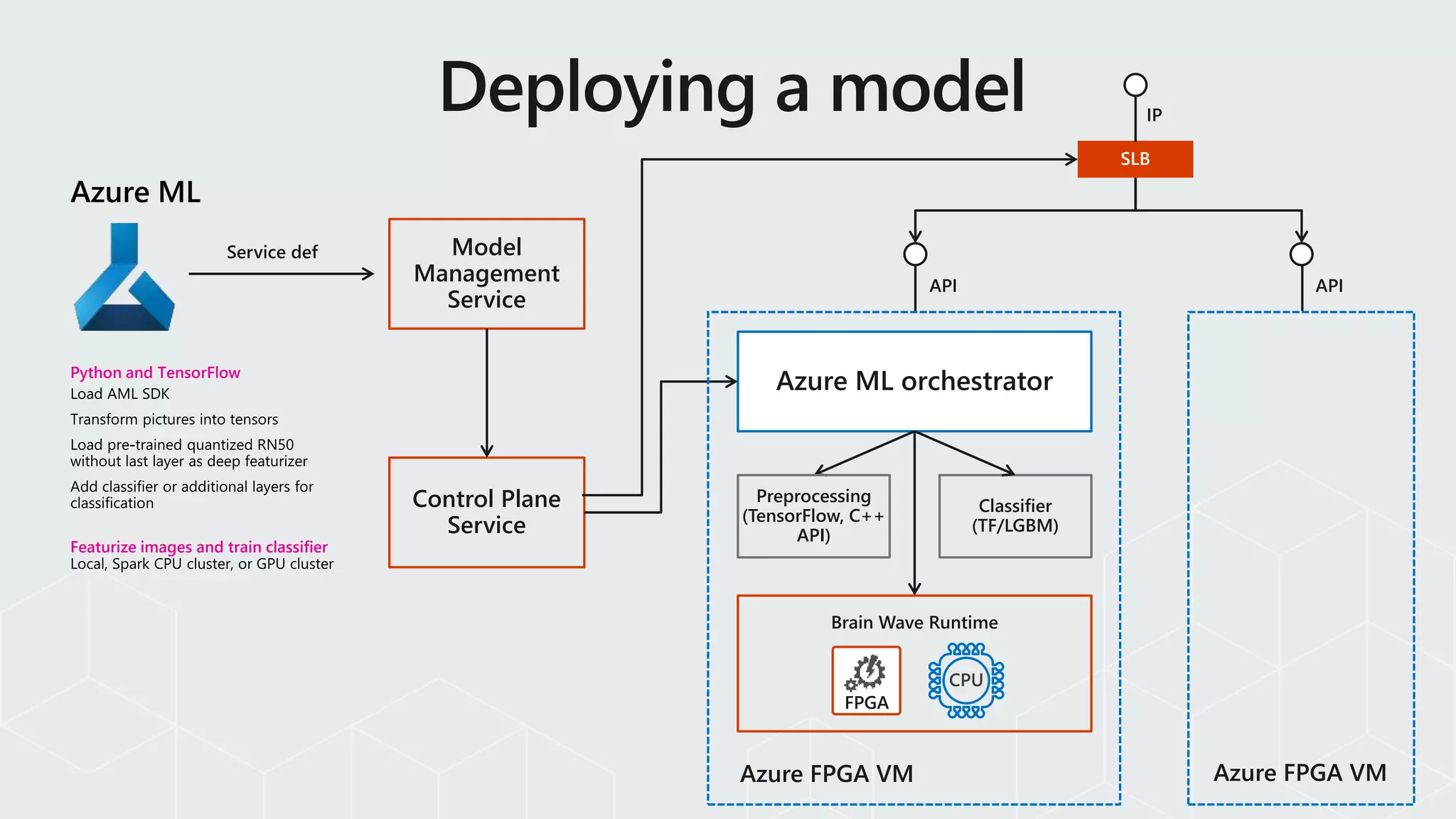
Management
Service
Azure ML orchestratorPythonand TensorFlow
Featurize images and train classifier
Classifier
(TF/LGBM)
Preprocessing
(TensorFlow, C++
API)
Control Plane
Service
Brain Wave Runtime
FPGA
CPU
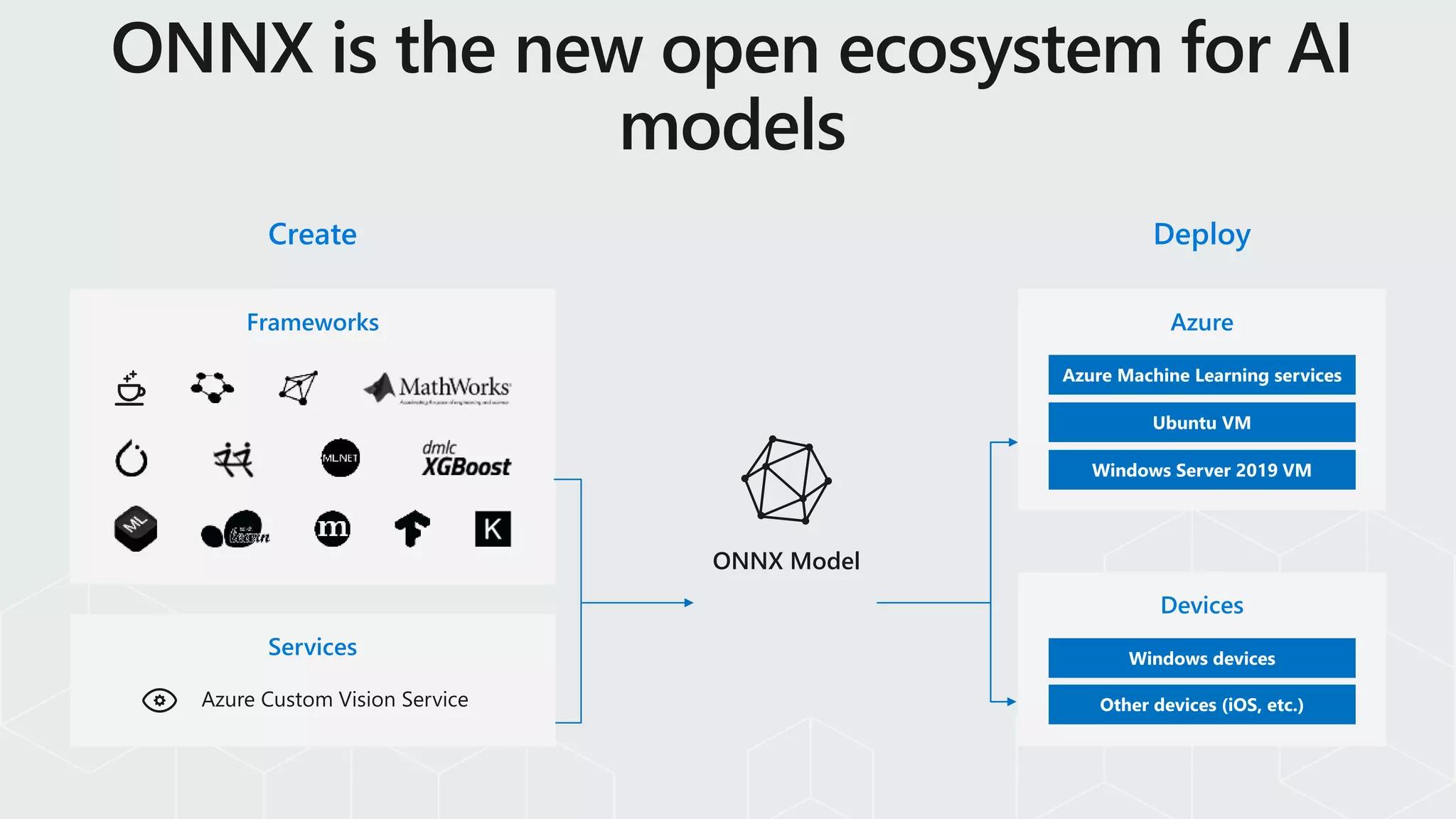
Extensible
Extensible architecture to
plug-inoptimizers and
hardware accelerators
Flexible
Supports full ONNX-ML
spec (v1.2-1.5)
C#, C, and Python APIs
Cross Platform
Works on
-Mac, Windows, Linux
-x86, x64, ARM
Also built-in to Windows
10 natively (WinML)
github.com/microsoft/onnxruntime
53.
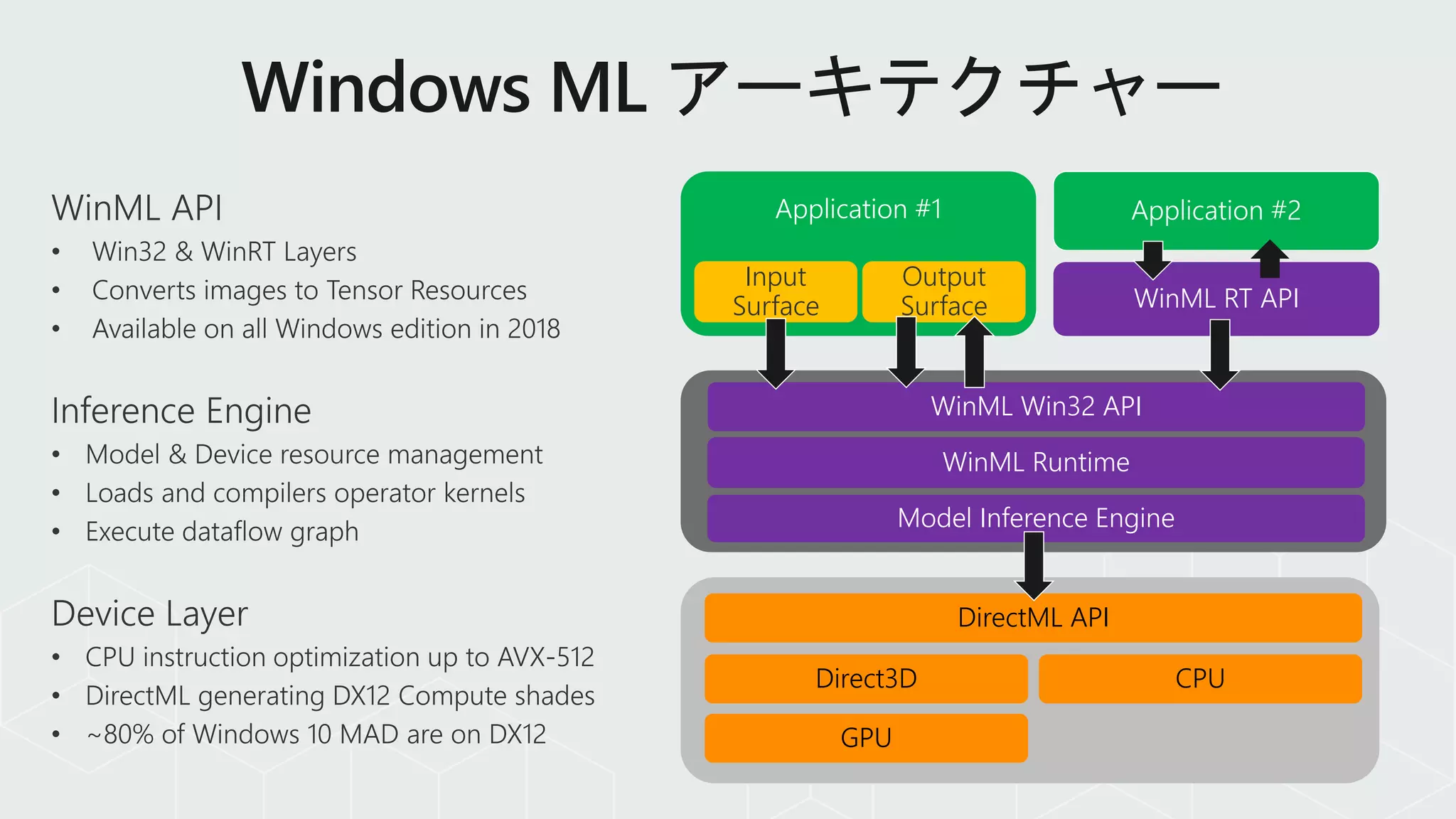
Application #1 Application#2
WinML RT API
WinML Win32 API
WinML Runtime
Model Inference Engine
DirectML API
CPUDirect3D
GPU
Input
Surface
Output
Surface
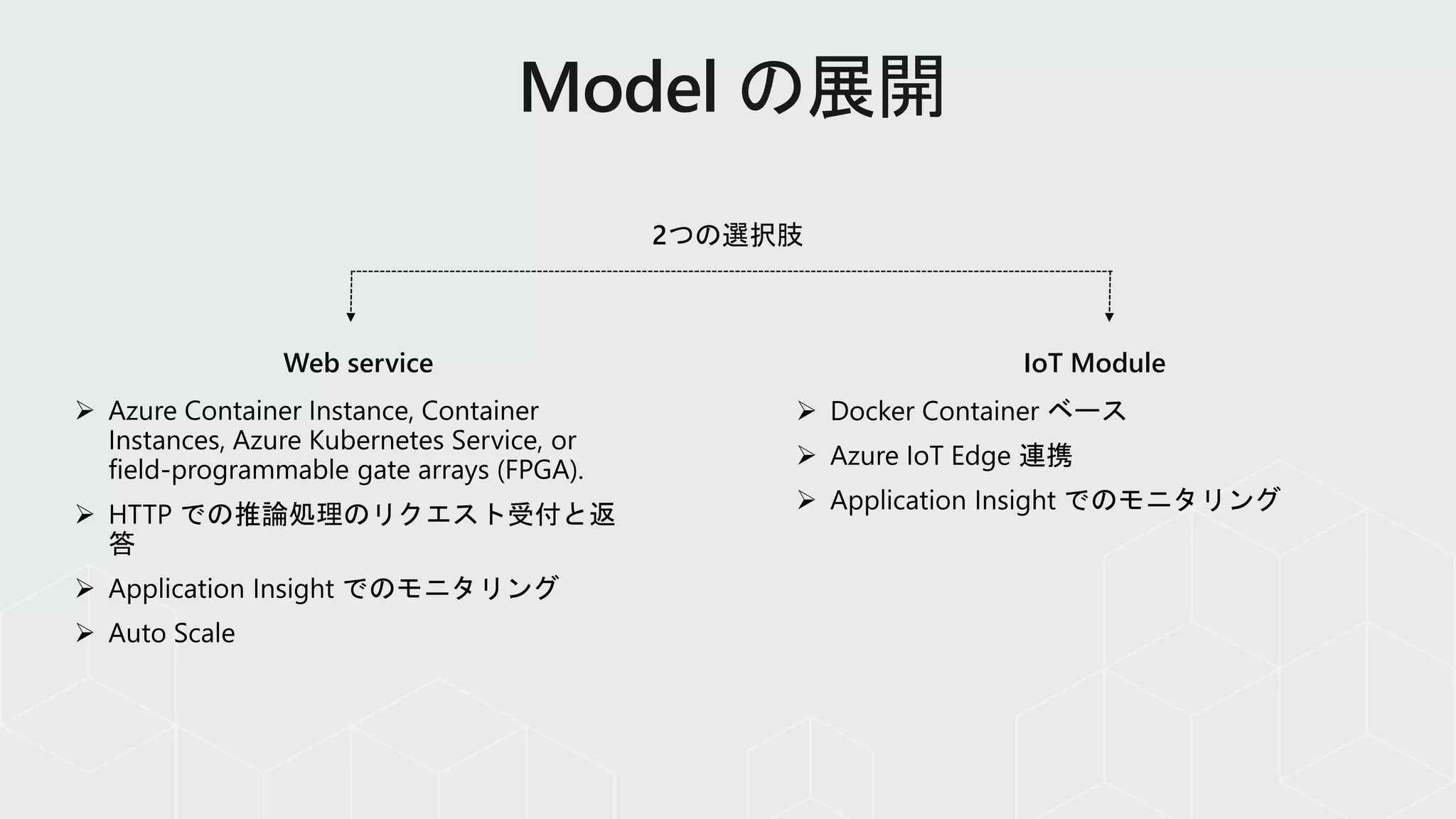
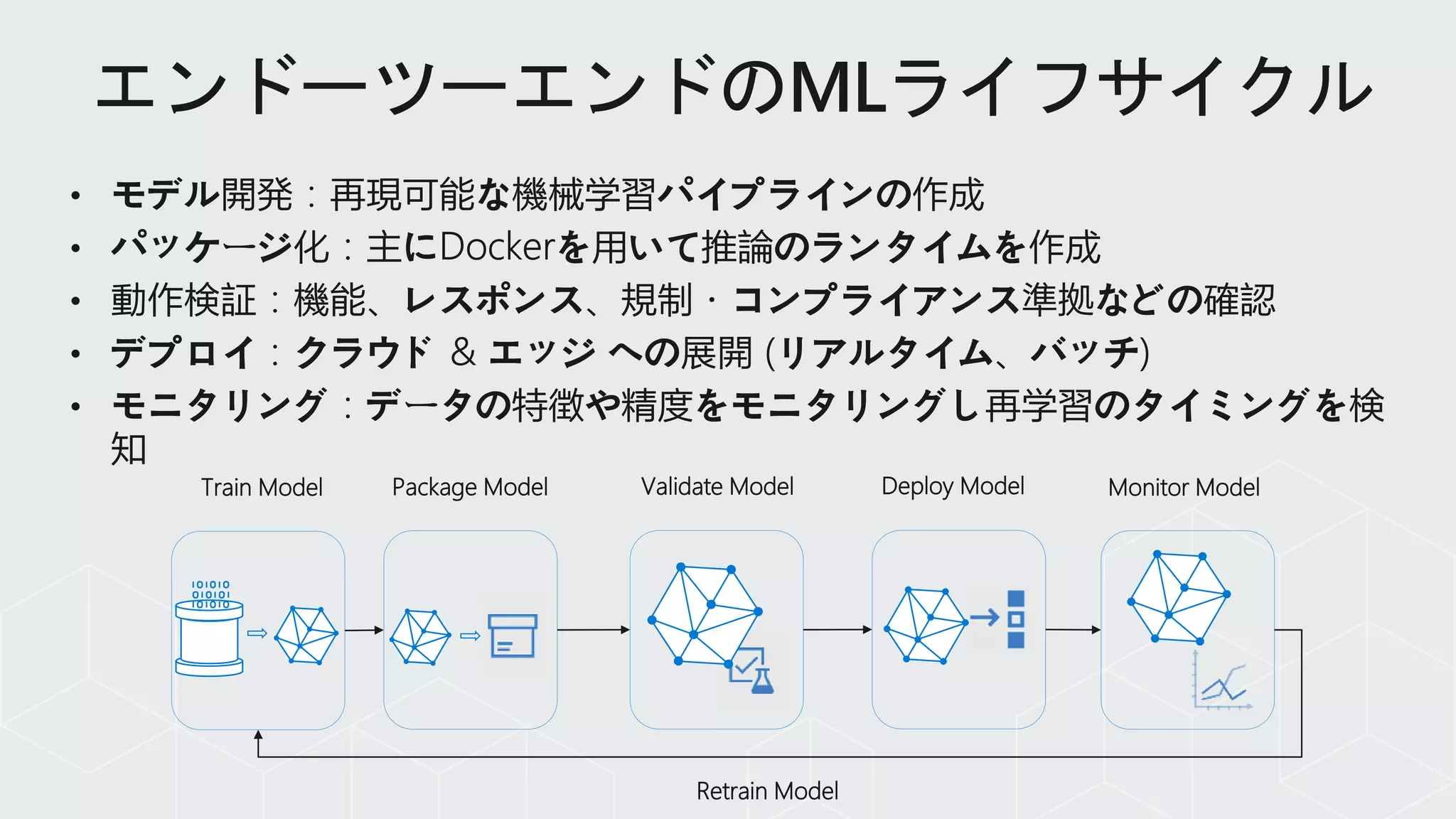
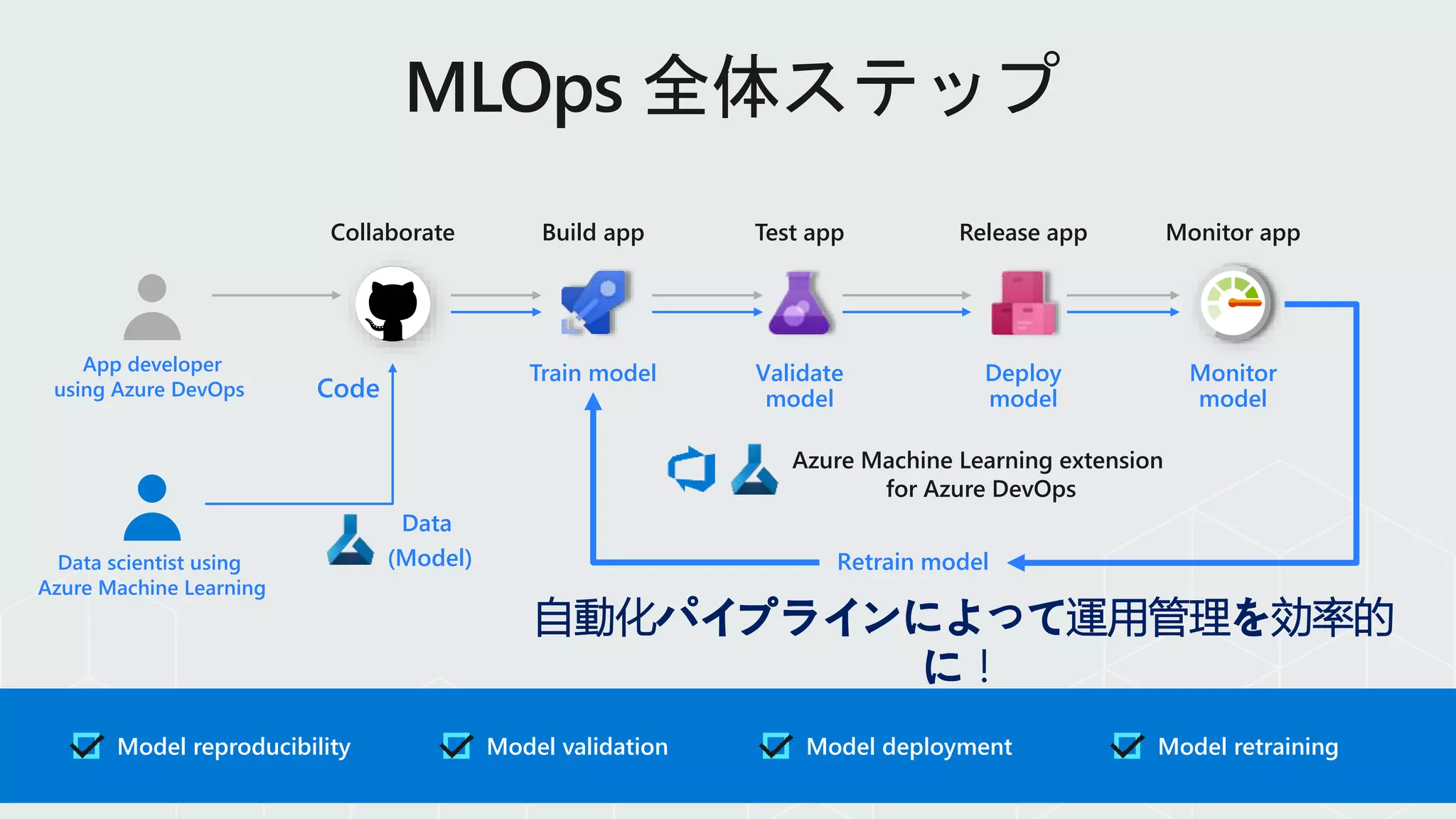
Model reproducibility ModelretrainingModel deploymentModel validation
Train model Validate
model
Deploy
model
Monitor
model
Build appCollaborate Test app Release app Monitor app
App developer
using Azure DevOps
Data scientist using
Azure Machine Learning
Retrain model
Azure Machine Learning extension
for Azure DevOps
Data
(Model)
Code
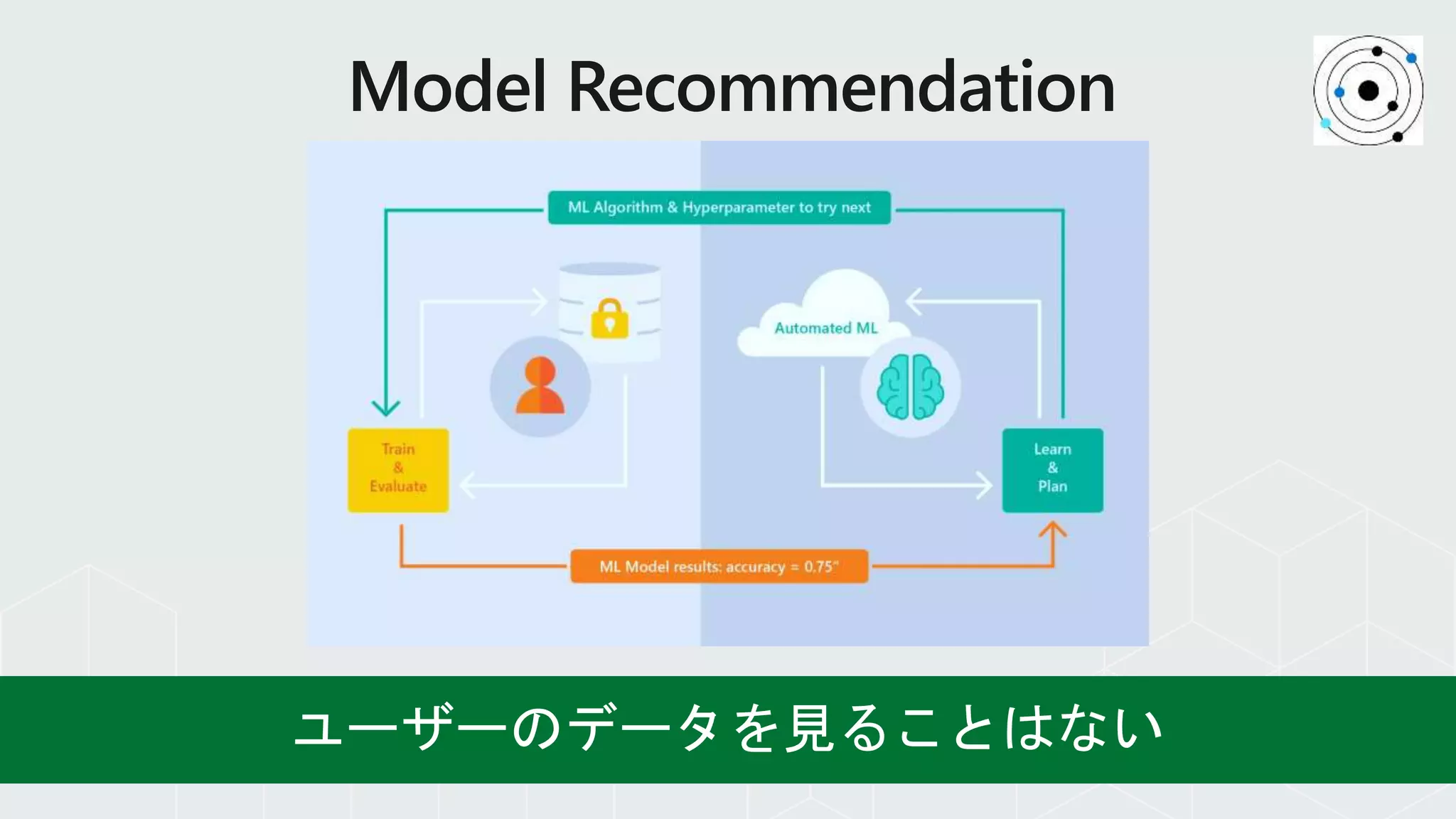
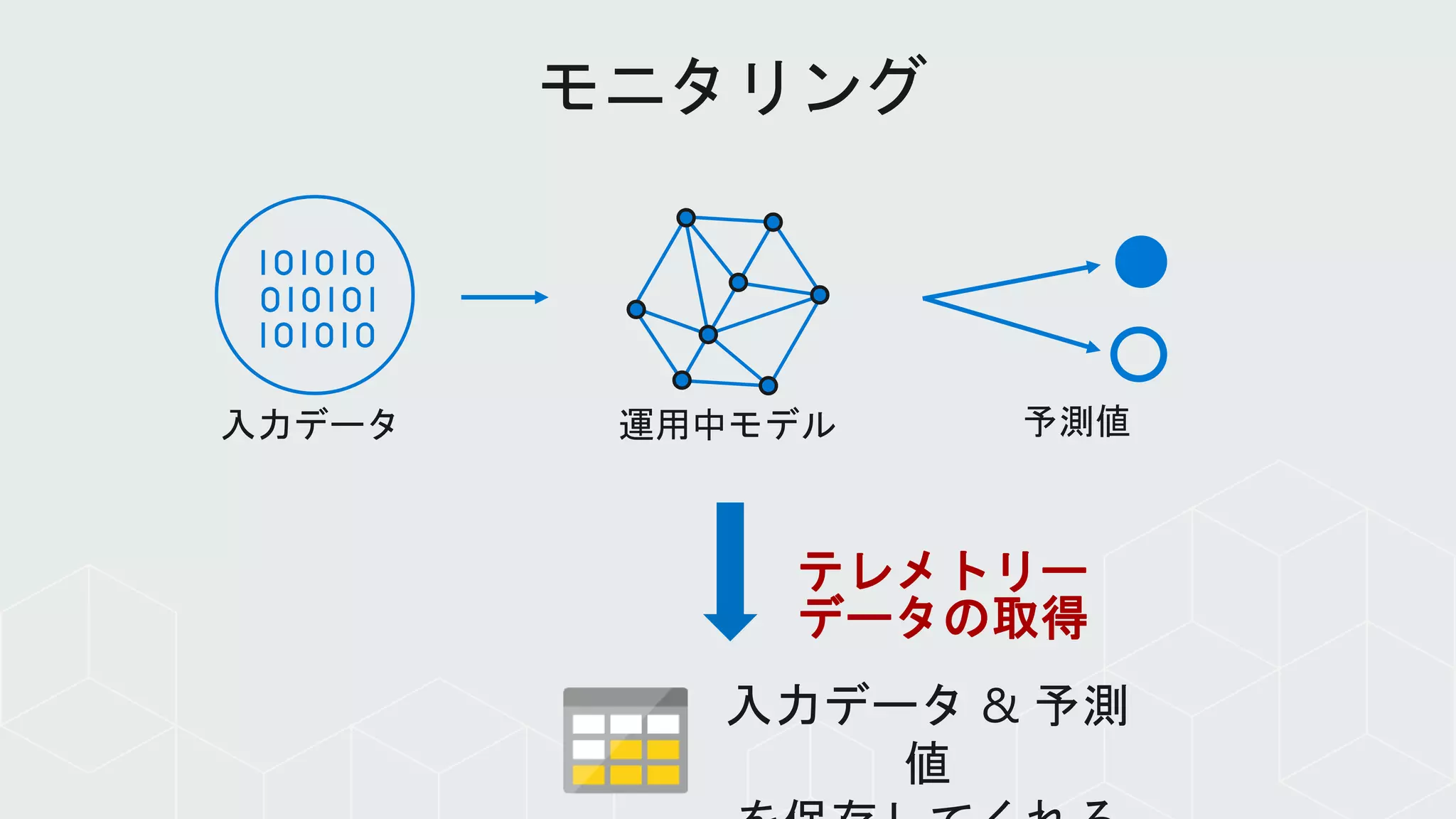
自動化パイプラインによって運用管理を効率的
に!
59.
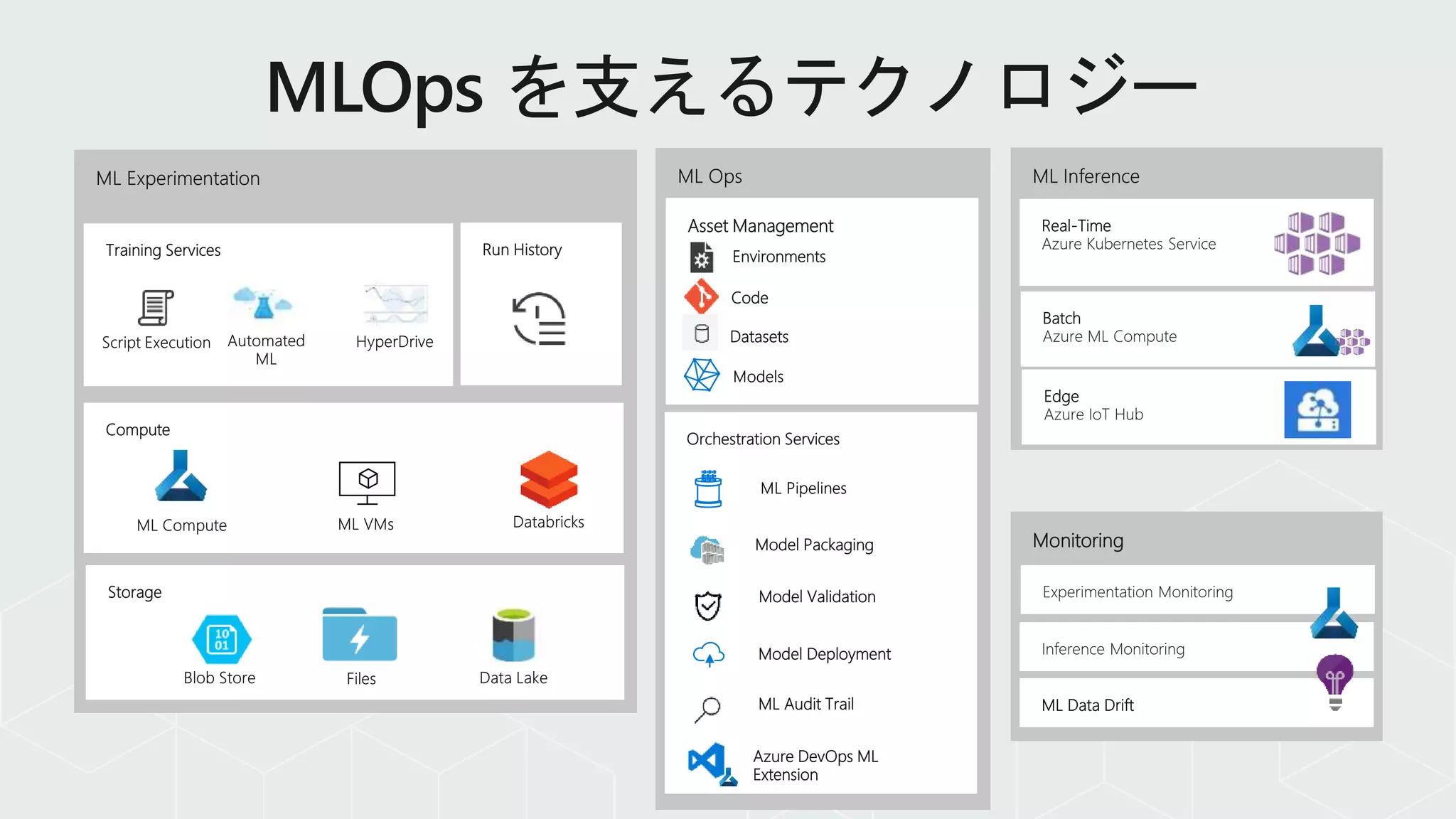
Orchestration Services
Monitoring
Real-Time
Azure KubernetesService
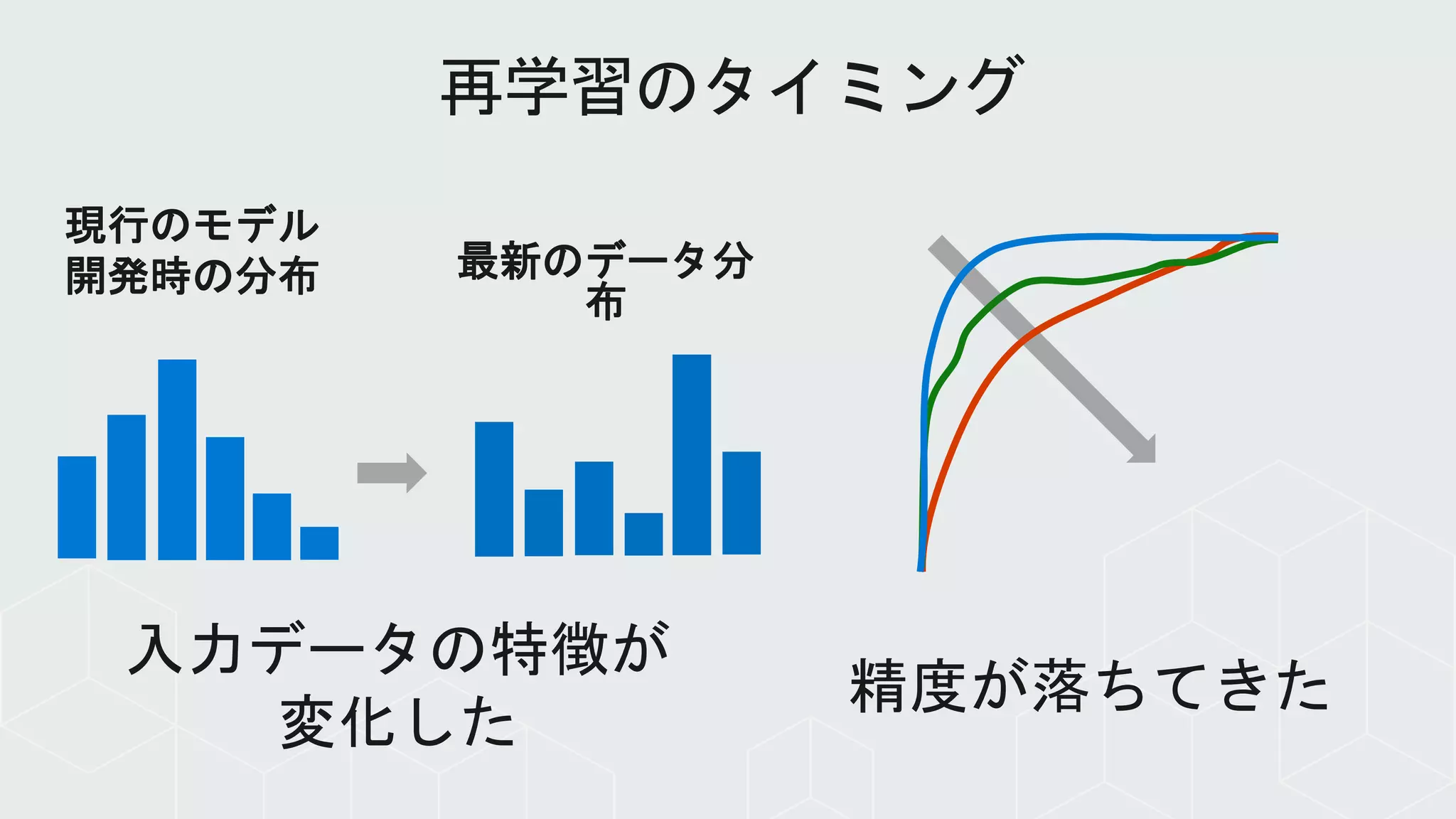
ML Data Drift
Experimentation Monitoring
Batch
Azure ML Compute
Inference Monitoring
Compute
Azure DevOps ML
Extension
Storage
Model Packaging
Model Validation
Run History
Model Deployment
Asset Management
Environments
Code
Datasets
ML Audit Trail
Training Services
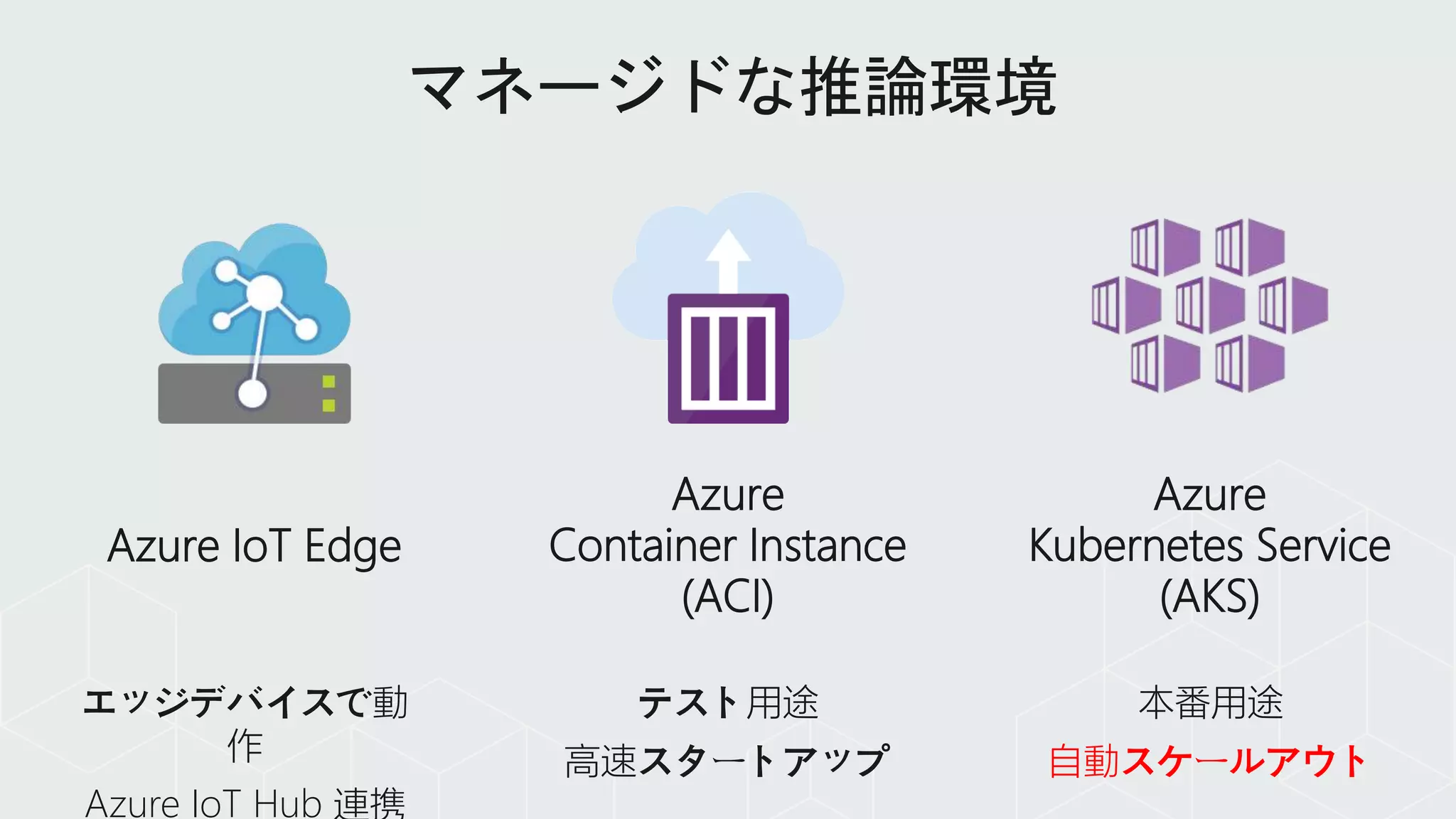
Edge
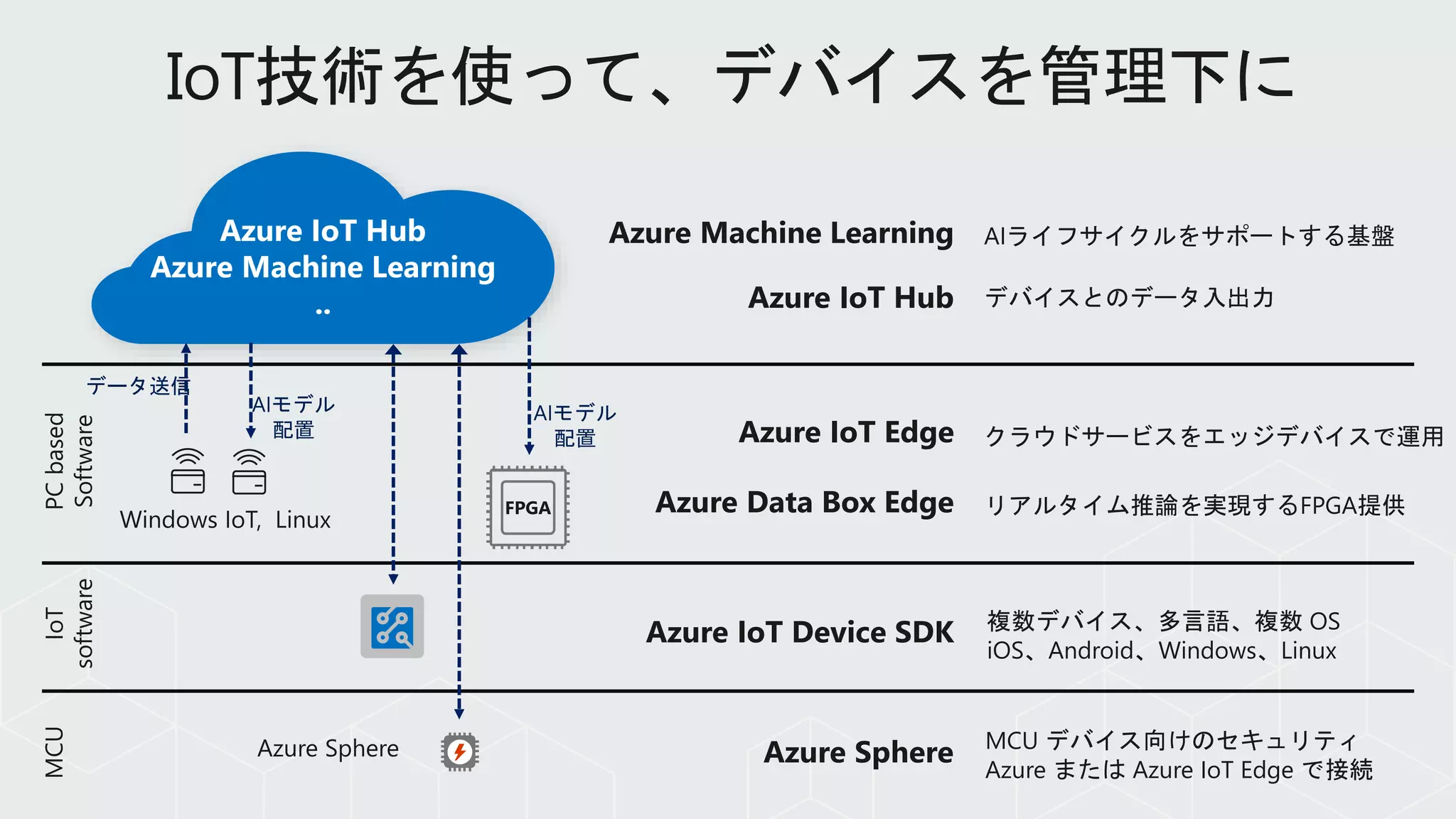
Azure IoT Hub







































































![[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~](https://cdn.slidesharecdn.com/ss_thumbnails/20181117devfestasapporoazureaipublic-181119035506-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第50回 Machine Learning 15minutes! Broadcast] Azure Machine Learning - Ignite ...](https://cdn.slidesharecdn.com/ss_thumbnails/20201205ml15minazuremlignite-201205101214-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Microsoft Tech Summit 2018] Azure Machine Learning サービスと Azure Databricks で実...](https://cdn.slidesharecdn.com/ss_thumbnails/20181107techsummitazuremldatabricks-181108015121-thumbnail.jpg?width=640&height=640&fit=bounds)




















