Deep Learningを用いた画像から説明文の自動生成の最新研究を調査したものを公開いたします。 数式の説明などかなり簡略したものですが、全体が俯瞰できるように工夫しましたので、何かのご参考になればと幸いです。 また、何か間違いがございましたら、ご指摘のほどよろしくお願いします。





















![© 2015 Metaps Inc. All Rights Reserved.
Deep Captioning With Multimodal Recurrent
Neural Networks (M-RNN)
Junhua Mao,etc 2015
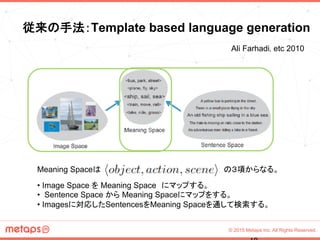
[図]単純なRNNを用いたモデル:
縦の紫の矢印は時間経過
上式は、左図のRecurrent部(赤い四角)
に対応し、t時間による入力単語w(t)と
1ステップ前の回帰部r(t-1)をUrで変換
したものを以下の関数f_2の引数とする。
f_2はRectified Linear Unit (ReLU)
で、出力は次の回帰部 r(t)となる。
上の式は、Multimodal部(紫の四角)に相当し、 単語
w(t), Recurrent部r(t) , CNNで処理されたイメージI
から計算される。g_2は右式のように定義される。](https://image.slidesharecdn.com/deeplearning-150710101928-lva1-app6892/85/Deep-learning-24-320.jpg)




























![© 2015 Metaps Inc. All Rights Reserved.
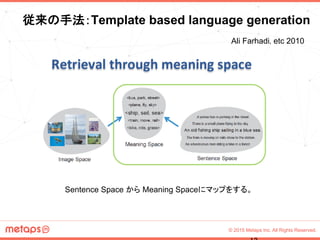
注意可能な全てのロケーションに対する期待値は、場所変数s_tをランダムに選択し
、予測contextベクトルE[^zt]を用いて、単純なフィードフォワード伝搬によって計算さ
れる。
つまり、Deterministic “Soft” Attentionは、注意ロケーション上の周辺尤度の近似で
計算される。
上の2式からNWGMは、以下の式のように近似することができる。
Deterministic “Soft” Attention
Kelvin Xu, etc 2015](https://image.slidesharecdn.com/deeplearning-150710101928-lva1-app6892/85/Deep-learning-54-320.jpg)







![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)

![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)













![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
























