Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Akisato Kimura
PDF, PPTX
3,910 views
CVPR2016 reading - 特徴量学習とクロスモーダル転移について
CVPR2016で発表された,特徴量学習とクロスモーダル転移に関する研究についてまとめてみました.
Technology
◦
Related topics:
Transfer Learning Uses
•
Deep Learning
•
Computer Vision Insights
•
Pattern Recognition
•
Read more
12
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
19
/ 41
20
/ 41
21
/ 41
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PPTX
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
by
Deep Learning JP
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PDF
Deep Learning Lab 異常検知入門
by
Shohei Hido
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
バンディットアルゴリズム入門と実践
by
智之 村上
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
by
Deep Learning JP
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
Deep Learning Lab 異常検知入門
by
Shohei Hido
マルチモーダル深層学習の研究動向
by
Koichiro Mori
What's hot
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
機械学習 / Deep Learning 大全 (1) 機械学習基礎編
by
Daiyu Hatakeyama
PDF
Kaggleのテクニック
by
Yasunori Ozaki
PDF
【論文紹介】ProtoMF: Prototype-based Matrix Factorization for Effective and Explain...
by
Kosetsu Tsukuda
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PDF
HiPPO/S4解説
by
Morpho, Inc.
PDF
12. Diffusion Model の数学的基礎.pdf
by
幸太朗 岩澤
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
距離とクラスタリング
by
大貴 末廣
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PPTX
Generative Adversarial Imitation Learningの紹介(RLアーキテクチャ勉強会)
by
Yusuke Nakata
PPTX
強化学習における好奇心
by
Shota Imai
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
情報検索とゼロショット学習
by
kt.mako
PPTX
レコメンド研究のあれこれ
by
Masahiro Sato
PPTX
深層学習の非常に簡単な説明
by
Seiichi Uchida
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
機械学習 / Deep Learning 大全 (1) 機械学習基礎編
by
Daiyu Hatakeyama
Kaggleのテクニック
by
Yasunori Ozaki
【論文紹介】ProtoMF: Prototype-based Matrix Factorization for Effective and Explain...
by
Kosetsu Tsukuda
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
変分ベイズ法の説明
by
Haruka Ozaki
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
HiPPO/S4解説
by
Morpho, Inc.
12. Diffusion Model の数学的基礎.pdf
by
幸太朗 岩澤
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
距離とクラスタリング
by
大貴 末廣
不均衡データのクラス分類
by
Shintaro Fukushima
Generative Adversarial Imitation Learningの紹介(RLアーキテクチャ勉強会)
by
Yusuke Nakata
強化学習における好奇心
by
Shota Imai
深層学習の数理
by
Taiji Suzuki
情報検索とゼロショット学習
by
kt.mako
レコメンド研究のあれこれ
by
Masahiro Sato
深層学習の非常に簡単な説明
by
Seiichi Uchida
Similar to CVPR2016 reading - 特徴量学習とクロスモーダル転移について
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
RUTILEA社内勉強会第1回 「転移学習」
by
TRUE_RUTILEA
PDF
転移学習やってみた!
by
Yutaka Terasawa
PDF
深層学習 - 画像認識のための深層学習 ①
by
Shohei Miyashita
PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PPTX
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
PDF
【2015.07】(1/2)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PPTX
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
PDF
点群深層学習 Meta-study
by
Naoya Chiba
PDF
深層学習 - 画像認識のための深層学習 ②
by
Shohei Miyashita
PDF
点群SegmentationのためのTransformerサーベイ
by
Takuya Minagawa
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
PDF
大規模画像認識とその周辺
by
n_hidekey
PPTX
Personalized Fashion Recommendation from Personal Social Media Data An Item t...
by
harmonylab
PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
by
KokiTakamiya
PPTX
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
PDF
Transfer forest(PRMU Jun 2014)
by
Masamitsu Tsuchiya
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
RUTILEA社内勉強会第1回 「転移学習」
by
TRUE_RUTILEA
転移学習やってみた!
by
Yutaka Terasawa
深層学習 - 画像認識のための深層学習 ①
by
Shohei Miyashita
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
by
Takahiro Kubo
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
by
Kento Doi
【2015.07】(1/2)cvpaper.challenge@CVPR2015
by
cvpaper. challenge
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
by
Deep Learning JP
点群深層学習 Meta-study
by
Naoya Chiba
深層学習 - 画像認識のための深層学習 ②
by
Shohei Miyashita
点群SegmentationのためのTransformerサーベイ
by
Takuya Minagawa
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
大規模画像認識とその周辺
by
n_hidekey
Personalized Fashion Recommendation from Personal Social Media Data An Item t...
by
harmonylab
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
by
KokiTakamiya
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
Transfer forest(PRMU Jun 2014)
by
Masamitsu Tsuchiya
More from Akisato Kimura
PPTX
Paper reading - Dropout as a Bayesian Approximation: Representing Model Uncer...
by
Akisato Kimura
PPTX
Paper reading - Dropout as a Bayesian Approximation: Representing Model Uncer...
by
Akisato Kimura
PDF
多変量解析の一般化
by
Akisato Kimura
PDF
NIPS2015 reading - Learning visual biases from human imagination
by
Akisato Kimura
PDF
CVPR2015 reading "Global refinement of random forest"
by
Akisato Kimura
PDF
CVPR2015 reading "Understainding image virality" (in Japanese)
by
Akisato Kimura
PDF
Computational models of human visual attention driven by auditory cues
by
Akisato Kimura
PDF
NIPS2014 reading - Top rank optimization in linear time
by
Akisato Kimura
PDF
CVPR2014 reading "Reconstructing storyline graphs for image recommendation fr...
by
Akisato Kimura
PDF
ICCV2013 reading: Learning to rank using privileged information
by
Akisato Kimura
PDF
ACMMM 2013 reading: Large-scale visual sentiment ontology and detectors using...
by
Akisato Kimura
PDF
IJCAI13 Paper review: Large-scale spectral clustering on graphs
by
Akisato Kimura
PDF
関西CVPR勉強会 2012.10.28
by
Akisato Kimura
PDF
関西CVPR勉強会 2012.7.29
by
Akisato Kimura
PDF
ICWSM12 Brief Review
by
Akisato Kimura
PDF
関西CVPRML勉強会 2012.2.18 (一般物体認識 - データセット)
by
Akisato Kimura
PDF
関西CVPRML勉強会(特定物体認識) 2012.1.14
by
Akisato Kimura
PDF
人間の視覚的注意を予測するモデル - 動的ベイジアンネットワークに基づく 最新のアプローチ -
by
Akisato Kimura
PDF
IBIS2011 企画セッション「CV/PRで独自の進化を遂げる学習・最適化技術」 趣旨説明
by
Akisato Kimura
PDF
立命館大学 AMLコロキウム 2011.10.20
by
Akisato Kimura
Paper reading - Dropout as a Bayesian Approximation: Representing Model Uncer...
by
Akisato Kimura
Paper reading - Dropout as a Bayesian Approximation: Representing Model Uncer...
by
Akisato Kimura
多変量解析の一般化
by
Akisato Kimura
NIPS2015 reading - Learning visual biases from human imagination
by
Akisato Kimura
CVPR2015 reading "Global refinement of random forest"
by
Akisato Kimura
CVPR2015 reading "Understainding image virality" (in Japanese)
by
Akisato Kimura
Computational models of human visual attention driven by auditory cues
by
Akisato Kimura
NIPS2014 reading - Top rank optimization in linear time
by
Akisato Kimura
CVPR2014 reading "Reconstructing storyline graphs for image recommendation fr...
by
Akisato Kimura
ICCV2013 reading: Learning to rank using privileged information
by
Akisato Kimura
ACMMM 2013 reading: Large-scale visual sentiment ontology and detectors using...
by
Akisato Kimura
IJCAI13 Paper review: Large-scale spectral clustering on graphs
by
Akisato Kimura
関西CVPR勉強会 2012.10.28
by
Akisato Kimura
関西CVPR勉強会 2012.7.29
by
Akisato Kimura
ICWSM12 Brief Review
by
Akisato Kimura
関西CVPRML勉強会 2012.2.18 (一般物体認識 - データセット)
by
Akisato Kimura
関西CVPRML勉強会(特定物体認識) 2012.1.14
by
Akisato Kimura
人間の視覚的注意を予測するモデル - 動的ベイジアンネットワークに基づく 最新のアプローチ -
by
Akisato Kimura
IBIS2011 企画セッション「CV/PRで独自の進化を遂げる学習・最適化技術」 趣旨説明
by
Akisato Kimura
立命館大学 AMLコロキウム 2011.10.20
by
Akisato Kimura
CVPR2016 reading - 特徴量学習とクロスモーダル転移について
1.
Copyright©2014 NTT corp.
All Rights Reserved. CVPR2016 reading 特徴量学習とクロスモーダル転移について Akisato Kimura <akisato@ieee.org> _akisato http://www.kecl.ntt.co.jp/people/kimura.akisato/
2.
1 フルーツジュースはいかがですか?
3.
2 フルーツジュースはいかがですか?
4.
3 ジュースで大事なこと 材料 作り方 飲み方
5.
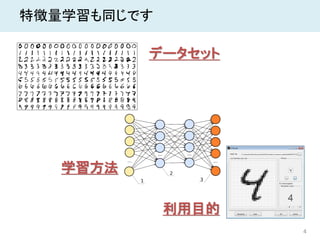
4 特徴量学習も同じです データセット 学習方法 利用目的
6.
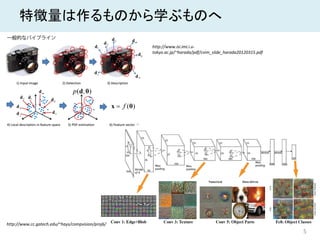
5 特徴量は作るものから学ぶものへ http://www.isi.imi.i.u- tokyo.ac.jp/~harada/pdf/cvim_slide_harada20120315.pdf http://www.cc.gatech.edu/~hays/compvision/proj6/
7.
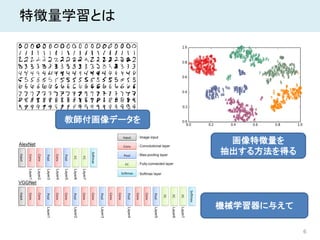
6 特徴量学習とは 教師付画像データを 機械学習器に与えて 画像特徴量を 抽出する方法を得る
8.
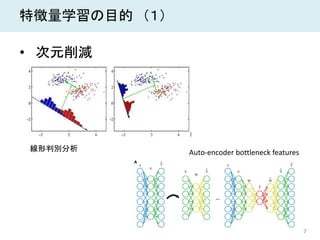
7 特徴量学習の目的 (1) • 次元削減 線形判別分析
Auto-encoder bottleneck features
9.
8 特徴量学習の目的 (1) • 最終タスク込みの特徴量学習
(end-to-end) [LeCun Proc. IEEE98]
10.
9 特徴量学習の目的 (2) • タスク実現のための中間特徴量 [Yu+
CVPR13] http://www.cc.gatech.edu/~hays/compvision/proj6/
11.
10 特徴量学習の問題点 教師付画像データ (畳み込み) ニューラネネットワーク 画像特徴量 深い学習で高い性能を出すほどの 大量の教師付データを作るには, お金か時間が大量に必要です.
12.
11 どうすれば良いか? • 教師なし特徴量学習 ‒ 教師付きデータを作らないで済ます •
クロスモーダル転移 ‒ 別のモーダルから得られる知識を転用する
13.
Copyright©2014 NTT corp.
All Rights Reserved. 教師なし特徴量学習 • Mukuta+ “Kernel approximation via empirical orthogonal decomposition for unsupervised feature learning” • Pathak+ “Context encoders: Feature learning byinpainting” • Zhang+ “Online collaborative learning for open vocabulary visual classifiers” • Yang+ “Joint unsupervised learning of deep representation and image clusters”
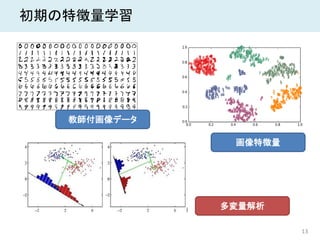
14.
13 初期の特徴量学習 教師付画像データ 画像特徴量 多変量解析
15.
14 Kernel PCA 特徴ベクトル 𝒙𝒙
を変換する方法 𝒈𝒈 = 𝚲𝚲−1/2 𝑨𝑨⊤ 𝒌𝒌 𝒌𝒌 = (𝐾𝐾 𝒙𝒙1, 𝒙𝒙 , 𝐾𝐾 𝒙𝒙2, 𝒙𝒙 , … , 𝑘𝑘(𝒙𝒙𝑛𝑛, 𝒙𝒙)), 𝑲𝑲 = 𝐾𝐾 𝒙𝒙1, 𝒙𝒙 𝑖𝑖,𝑗𝑗=1 𝑛𝑛 𝜆𝜆𝑖𝑖, 𝜶𝜶𝑖𝑖 𝑖𝑖=1 𝑛𝑛 : Sorted eigenvalues and normalized eigenvectors of 𝑲𝑲𝑲𝑲 = 𝜆𝜆𝜶𝜶 𝜆𝜆1 ≥ 𝜆𝜆2 ≥ ⋯ ≥ 𝜆𝜆 𝑚𝑚, 𝜶𝜶𝑖𝑖, 𝛼𝛼𝑗𝑗 = 𝛿𝛿𝑖𝑖,𝑗𝑗 𝚲𝚲 = diag(𝜆𝜆1, 𝜆𝜆2, … , 𝜆𝜆 𝑚𝑚), 𝑨𝑨 = (𝜶𝜶1, 𝜶𝜶2, … , 𝜶𝜶 𝑚𝑚) グラム行列が 大きい → 計算量大 小さい → 表現力不足 http://www.kecl.ntt.co.jp/people/kimura.akisato/titech/class.html
16.
15 グラム行列を近似する方法 • Nystrom method ‒
学習サンプルの乱択 + 部分グラム行列の直交展開 ‒ 直交展開に大きな計算量が必要 • Random feature method [Rahini+ NIPS07] ‒ カーネル関数を以下の形で表現 ‒ パラメータ 𝑤𝑤 のサンプリングによる関数近似 ‒ 近似に学習サンプルを用いない → 近似誤差が不十分
17.
16 学習サンプルを用いてカーネル関数を近似 Merserの定理 � 𝑋𝑋 𝑘𝑘 𝑥𝑥, 𝑦𝑦
𝜓𝜓𝑖𝑖 𝑥𝑥 𝑝𝑝 𝑥𝑥 𝑑𝑑𝑑𝑑 = 𝜆𝜆𝑖𝑖 𝜓𝜓𝑖𝑖(𝑥𝑥) 1. 分布 𝑝𝑝(𝑥𝑥) を学習サンプルから予測 2. 固有関数 𝜓𝜓𝑖𝑖(𝑥𝑥) を求める 3. 固有値 𝜆𝜆𝑖𝑖 が大きい固有関数だけ使う (Mukuta and Harada)
18.
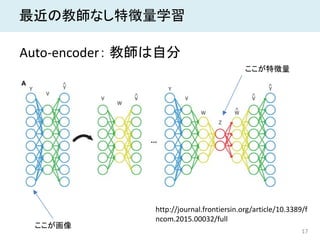
17 最近の教師なし特徴量学習 Auto-encoder: 教師は自分 http://journal.frontiersin.org/article/10.3389/f ncom.2015.00032/full ここが特徴量 ここが画像
19.
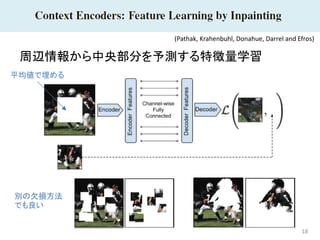
18 周辺情報から中央部分を予測する特徴量学習 (Pathak, Krahenbuhl, Donahue,
Darrel and Efros) 平均値で埋める 別の欠損方法 でも良い
20.
19 教師なし特徴量学習の別アプローチ 教師のようなものを求められさえすれば良い [Fang+ CVPR15] 「ユーザ 𝑗𝑗
が 画像 𝑖𝑖 を見た」行列 協調フィルタリング
21.
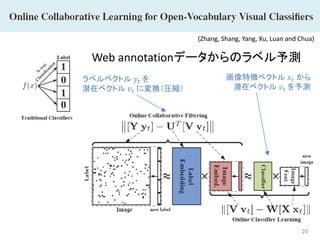
20 Web annotationデータからのラベル予測 (Zhang, Shang,
Yang, Xu, Luan and Chua) ラベルベクトル 𝑦𝑦𝑡𝑡 を 潜在ベクトル 𝑣𝑣𝑡𝑡 に変換(圧縮) 画像特徴ベクトル 𝑥𝑥𝑡𝑡 から 潜在ベクトル 𝑣𝑣𝑡𝑡 を予測
22.
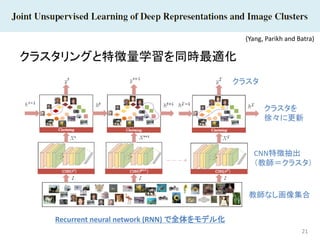
21 クラスタリングと特徴量学習を同時最適化 (Yang, Parikh and
Batra) 教師なし画像集合 CNN特徴抽出 (教師=クラスタ) Recurrent neural network (RNN) で全体をモデル化 クラスタを 徐々に更新 クラスタ
23.
Copyright©2014 NTT corp.
All Rights Reserved. クロスモーダル転移 • “Cross modal distillation for supervision transfer” • “Learning with side information through modality hallucination” • “Image style transfer using convolutional neural networks” • “Large scale semi-supervised object detection using visual and semantic knowledge transfer” • “Synthesized classifiers for zero-shot learning” • “Semi-supervised vocabulary-informed learning”
24.
23 クロスモーダル転移 典型例 - Zero-shot
learning • 画像のラベルを予測する分類問題で, 予測したいラベルの学習データが1つもない. [Frome+ NIPS13] word2vec CNN CNN特徴から単語ベクトルを予測 単語ベクトルが類似する単語を 予測結果として出力
25.
24 クロスモーダル転移が流行る周辺環境 • どのモーダルでもNN特徴表現が利用可能に • マルチモーダルNNの発達 [Silberer+
ACL14] [Srivastava+ JMLR14]
26.
Copyright©2014 NTT corp.
All Rights Reserved. マルチモーダル特徴量学習 • “MDL-CW: A multimodal deep learning framework with cross weights” • “Multi-view deep network for cross-view classification” • “Visual Word2Vec: Learning visually grounded word embeddings using abstract scenes”
27.
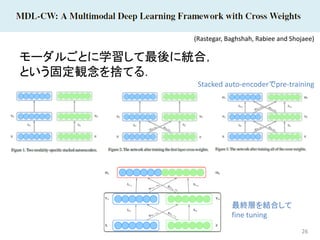
26 モーダルごとに学習して最後に統合, という固定観念を捨てる. (Rastegar, Baghshah, Rabiee
and Shojaee) Stacked auto-encoderでpre-training 最終層を結合して fine tuning
28.
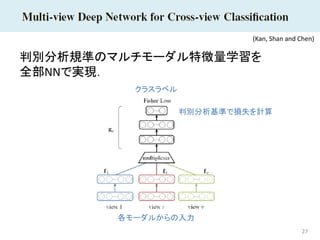
27 判別分析規準のマルチモーダル特徴量学習を 全部NNで実現. (Kan, Shan and
Chen) クラスラベル 各モーダルからの入力 判別分析基準で損失を計算
29.
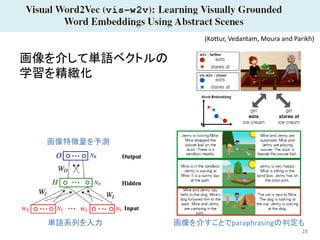
28 画像を介して単語ベクトルの 学習を精緻化 (Kottur, Vedantam, Moura
and Parikh) 単語系列を入力 画像特徴量を予測 画像を介すことでparaphrasingの判定も
30.
Copyright©2014 NTT corp.
All Rights Reserved. クロスモーダル転移 • “Cross modal distillation for supervision transfer” • “Learning with side information through modality hallucination” • “Synthesized classifiers for zero-shot learning” • “Semi-supervised vocabulary-informed learning” • “Latent embeddings for zero-shot classification” • “Image style transfer using convolutional neural networks” • “Learning attributes equals multi-source domain generalization”
31.
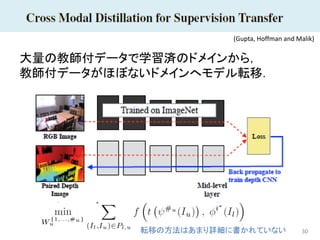
30 大量の教師付データで学習済のドメインから, 教師付データがほぼないドメインへモデル転移. (Gupta, Hoffman and
Malik) 転移の方法はあまり詳細に書かれていない
32.
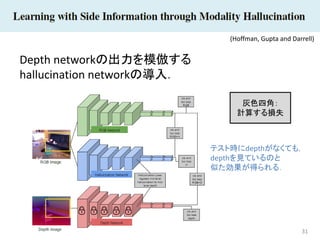
31 Depth networkの出力を模倣する hallucination networkの導入. (Hoffman,
Gupta and Darrell) 灰色四角: 計算する損失 テスト時にdepthがなくても, depthを見ているのと 似た効果が得られる.
33.
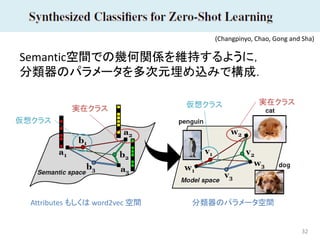
32 Semantic空間での幾何関係を維持するように, 分類器のパラメータを多次元埋め込みで構成. (Changpinyo, Chao, Gong
and Sha) 分類器のパラメータ空間Attributes もしくは word2vec 空間 実在クラス仮想クラス実在クラス 仮想クラス
34.
33 予測対象ラベルの学習データがないかもしれない open-vocabulary learningの実現. (Fu and
Sigal) 画像特徴 𝑥𝑥 を単語ベクトル 𝑢𝑢 に変換する 𝑊𝑊 を求めたい. 自分の属するクラスの単語ベクトルが一番近くなるように変換したい.
35.
34 画像特徴と単語ベクトルの関係性を 複数の「観点」から学習することを目指す. (Xian, Akata, Sharma,
Nguyen, Hein and Schiele) 画像特徴 𝑥𝑥 と単語ベクトル 𝑦𝑦 とのfeasibilityが最大になるクラスに分類. 通常: Feasibilityは単一パラメータの双線形変換で記述. 本論文: 複数パラメータによる双線形変換の 混合として記述.
36.
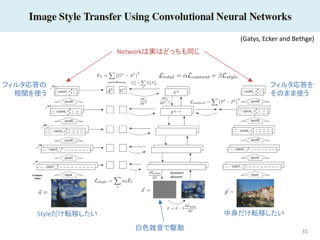
35 (Gatys, Ecker and
Bethge) 白色雑音で駆動 Styleだけ転移したい 中身だけ転移したい Networkは実はどっちも同じ フィルタ応答を そのまま使う フィルタ応答の 相関を使う
37.
36 Attributesを用いた分類問題を 「ドメイン汎化」 [Muandet+ ICML13]
として考え直す. (Gan, Yang, Gong)
38.
Copyright©2014 NTT corp.
All Rights Reserved. まとめ
39.
38 ジュースで一番大事なこと 材料 作り方 飲み方
40.
39 特徴量学習も同じです データセット 学習方法 利用目的 • 目的に合わせたデータセットを用いる必要がある. • 同じ手法を用いても,異なる教師データからは異なる学習結果が出る. •
思うように結果が出ないのは, 本当に学習がうまくいっていないからでしょうか? • データの使い方を工夫すると,今までできなかった ことができるようになるかもしれない.
41.
40
Download





![8
特徴量学習の目的 (1)
• 最終タスク込みの特徴量学習 (end-to-end)
[LeCun Proc. IEEE98]](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-9-320.jpg)
![9
特徴量学習の目的 (2)
• タスク実現のための中間特徴量
[Yu+ CVPR13]
http://www.cc.gatech.edu/~hays/compvision/proj6/](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-10-320.jpg)




![15
グラム行列を近似する方法
• Nystrom method
‒ 学習サンプルの乱択 + 部分グラム行列の直交展開
‒ 直交展開に大きな計算量が必要
• Random feature method [Rahini+ NIPS07]
‒ カーネル関数を以下の形で表現
‒ パラメータ 𝑤𝑤 のサンプリングによる関数近似
‒ 近似に学習サンプルを用いない → 近似誤差が不十分](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-16-320.jpg)

![19
教師なし特徴量学習の別アプローチ
教師のようなものを求められさえすれば良い
[Fang+ CVPR15]
「ユーザ 𝑗𝑗 が
画像 𝑖𝑖 を見た」行列 協調フィルタリング](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-20-320.jpg)

![23
クロスモーダル転移
典型例 - Zero-shot learning
• 画像のラベルを予測する分類問題で,
予測したいラベルの学習データが1つもない.
[Frome+ NIPS13]
word2vec
CNN
CNN特徴から単語ベクトルを予測 単語ベクトルが類似する単語を
予測結果として出力](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-24-320.jpg)
![24
クロスモーダル転移が流行る周辺環境
• どのモーダルでもNN特徴表現が利用可能に
• マルチモーダルNNの発達
[Silberer+ ACL14]
[Srivastava+ JMLR14]](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-25-320.jpg)




![36
Attributesを用いた分類問題を
「ドメイン汎化」 [Muandet+ ICML13] として考え直す.
(Gan, Yang, Gong)](https://image.slidesharecdn.com/160717kantocvver0-160717052304/85/CVPR2016-reading-37-320.jpg)








![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)













![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

























