This slide introduces 3D-CNN model(S. Ji, et al,2013). It have extended 2D-CNN to 3D which includes temporal dimension.


![今回取り上げるのは3D-CNN
[1]Shuiwang Ji, Wei Xu, Ming Yang, Kai Yu. “3D
Convolutional neural networks for human action recognition.
PAMI, 35(1):221-231, 2013.
画像の一般物体認識で広く使われるCNNを三次元(x, y, t)
に拡張することで、動作認識へ応用した!](https://image.slidesharecdn.com/3dcnnintro-160314060007/85/3D-CNN-2-320.jpg)
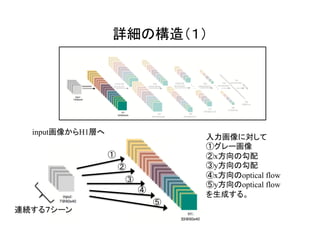
![ここがポイント!
[1]のFigure 1, Figure2より
2DのCNN
3D-CNN
vij
wy
= tanh bij + wijm
pq
v(i−1)m
(x+p)(y+q)
q=0
Qi−1
∑
p=0
Pi−1
∑
m
∑
⎛
⎝
⎜⎜
⎞
⎠
⎟⎟ vij
wyz
= tanh bij + wijm
pq
v(i−1)m
(x+p)(y+q)(z+r)
r=0
Ri−1
∑
q=0
Qi−1
∑
p=0
Pi−1
∑
m
∑
⎛
⎝
⎜⎜
⎞
⎠
⎟⎟
時間軸方向
に展開](https://image.slidesharecdn.com/3dcnnintro-160314060007/85/3D-CNN-3-320.jpg)
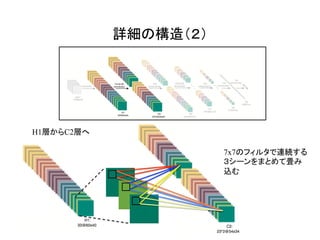
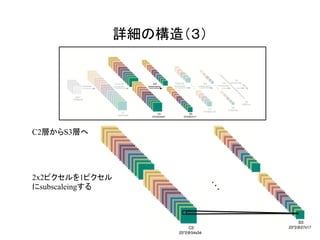
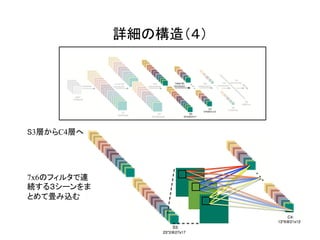
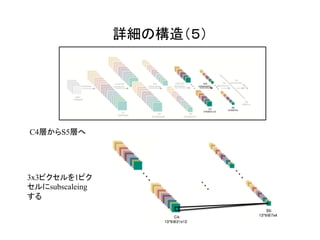
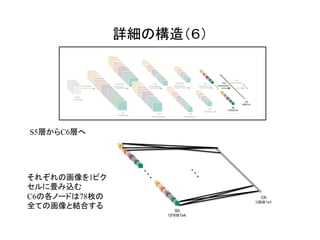
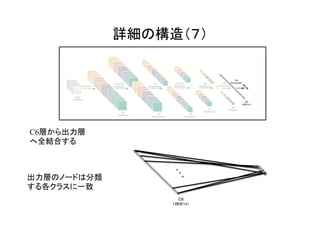
![これが全体の構造!
[1]のFigure 3より](https://image.slidesharecdn.com/3dcnnintro-160314060007/85/3D-CNN-4-320.jpg)

![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Blind Video Temporal Consistency via Deep Video Prior](https://cdn.slidesharecdn.com/ss_thumbnails/20201030deepvideoprior-201030024757-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)




















































