Recommended
PDF
動画像理解のための深層学習アプローチ Deep learning approaches to video understanding
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
PPTX
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recog...
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PDF
PDF
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
PDF
物体検知(Meta Study Group 発表資料)
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PPTX
PPTX
論文紹介: Fast R-CNN&Faster R-CNN
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PDF
Introduction to YOLO detection model
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
PPTX
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
PDF
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
PDF
[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)
PDF
PDF
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
PPTX
PDF
PDF
DeepLearningDay2016Summer
More Related Content
PDF
動画像理解のための深層学習アプローチ Deep learning approaches to video understanding
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
PPTX
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recog...
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PDF
PDF
What's hot
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
PDF
物体検知(Meta Study Group 発表資料)
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PPTX
PPTX
論文紹介: Fast R-CNN&Faster R-CNN
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PDF
Introduction to YOLO detection model
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
PPTX
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
PDF
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
PDF
[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)
PDF
PDF
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
PPTX
Similar to R-CNNの原理とここ数年の流れ
PDF
PDF
DeepLearningDay2016Summer
PDF
PPTX
PDF
PPTX
PDF
cvpaper.challenge -サーベイの共有と可能性について- (画像応用技術専門委員会研究会 2016年7月)
PDF
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
PPTX
PDF
PDF
PDF
PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
PDF
PPTX
Densely Connected Convolutional Networks
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
PDF
Convolutional Neural Network @ CV勉強会関東
PDF
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
PDF
More from Kazuki Motohashi
PDF
20190619 オートエンコーダーと異常検知入門
PDF
20190407 第7章 事例研究:自然言語処理における素性
PDF
20190324 第6章 テキストデータのための素性
PDF
20190417 畳み込みニューラル ネットワークの基礎と応用
PPTX
PDF
20180110 AI&ロボット勉強会 Deeplearning4J と時系列データの異常検知について
R-CNNの原理とここ数年の流れ 1. 2. 3. R-CNN (Regions with CNN features)
('n03085013', 'computer_keyboard', 0.78958303)
('n04264628', 'space_bar', 0.13960978)
('n04505470', 'typewriter_keyboard', 0.050729375)
('n03793489', 'mouse', 0.0087937126)
('n04074963', 'remote_control', 0.0026325041)
* 出典:人工知能に関する断創録 - KerasでVGG16を使う (2017)
* http://aidiary.hatenablog.com/entry/20170104/1483535144
CNN (Convolutional Neural Network) 単体では
画像全体から特徴量 (feature) を抽出可能
領域候補
(Region Proposals)
を生成すれば...
Region毎のfeatureを抽出可能
人間が行うような”物体認識”
* 出典:Rich feature hierarchies for accurate object detection and semantic segmentation (2013)
* https://arxiv.org/abs/1311.2524
3
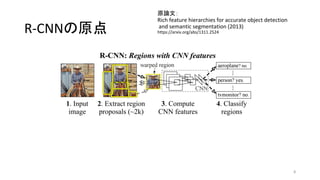
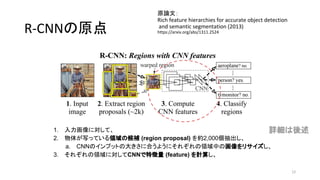
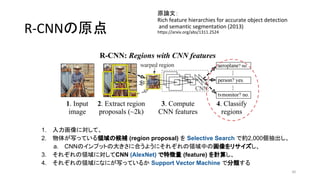
4. 5. 6. 7. 8. 9. R-CNNの原点
原論文:
Rich feature hierarchies for accurate object detection
and semantic segmentation (2013)
https://arxiv.org/abs/1311.2524
9
1. 入力画像に対して、
2. 物体が写っている領域の候補 (region proposal) を抽出し、
a. CNNのインプットの大きさに合うように領域中の画像をリサ
イズし、
3. それぞれの領域に対してCNNで特徴量 (feature) を計算し
4. それぞれの領域になにが写っているか分類する
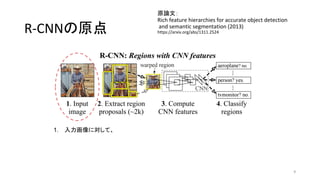
10. R-CNNの原点
原論文:
Rich feature hierarchies for accurate object detection
and semantic segmentation (2013)
https://arxiv.org/abs/1311.2524
10
1. 入力画像に対して、
2. 物体が写っている領域の候補 (region proposal) を約2,000個抽出し、
a. CNNのインプットの大きさに合うように領域中の画像をリサイズし、
3. それぞれの領域に対してCNNで特徴量 (feature) を計算し
4. それぞれの領域になにが写っているか分類する
詳細は後述
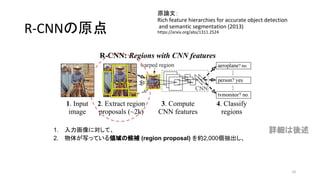
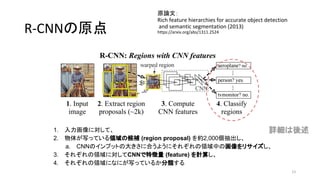
11. R-CNNの原点
原論文:
Rich feature hierarchies for accurate object detection
and semantic segmentation (2013)
https://arxiv.org/abs/1311.2524
11
1. 入力画像に対して、
2. 物体が写っている領域の候補 (region proposal) を約2,000個抽出し、
a. CNNのインプットの大きさに合うようにそれぞれの領域中の画像をリサイズし、
3. それぞれの領域に対してCNNで特徴量 (feature) を計算し
4. それぞれの領域になにが写っているか分類する
詳細は後述
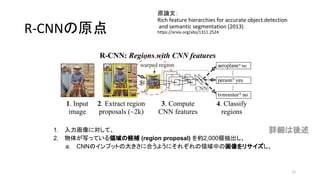
12. R-CNNの原点
原論文:
Rich feature hierarchies for accurate object detection
and semantic segmentation (2013)
https://arxiv.org/abs/1311.2524
12
1. 入力画像に対して、
2. 物体が写っている領域の候補 (region proposal) を約2,000個抽出し、
a. CNNのインプットの大きさに合うようにそれぞれの領域中の画像をリサイズし、
3. それぞれの領域に対してCNNで特徴量 (feature) を計算し、
4. それぞれの領域になにが写っているか分類する
詳細は後述
13. R-CNNの原点
原論文:
Rich feature hierarchies for accurate object detection
and semantic segmentation (2013)
https://arxiv.org/abs/1311.2524
13
1. 入力画像に対して、
2. 物体が写っている領域の候補 (region proposal) を約2,000個抽出し、
a. CNNのインプットの大きさに合うようにそれぞれの領域中の画像をリサイズし、
3. それぞれの領域に対してCNNで特徴量 (feature) を計算し、
4. それぞれの領域になにが写っているか分類する
詳細は後述
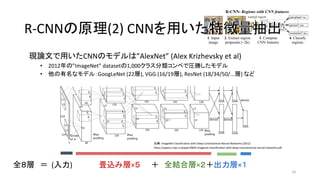
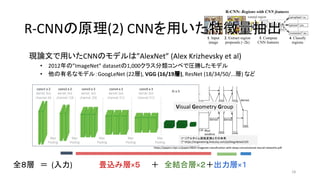
14. 15. 16. 現論文で用いたCNNのモデルは”AlexNet” (Alex Krizhevsky et al)
• 2012年の”ImageNet” datasetの1,000クラス分類コンペで圧勝したモデル
• 他の有名なモデル:GoogLeNet (22層), VGG (16/19層), ResNet (18/34/50/...層) など
16
出典:ImageNet Classification with Deep Convolutional Neural Networks (2012)
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
R-CNNの原理(2) CNNを用いた特徴量抽出R-CNNの原理(2) CNNを用いた特徴量抽出
全8層 = (入力) 畳込み層×5 + 全結合層×2+出力層×1
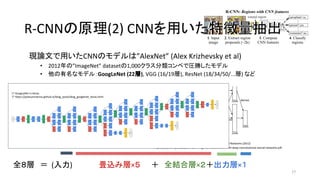
17. 現論文で用いたCNNのモデルは”AlexNet” (Alex Krizhevsky et al)
• 2012年の”ImageNet” datasetの1,000クラス分類コンペで圧勝したモデル
• 他の有名なモデル:GoogLeNet (22層), VGG (16/19層), ResNet (18/34/50/...層) など
17
出典:ImageNet Classification with Deep Convolutional Neural Networks (2012)
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
R-CNNの原理(2) CNNを用いた特徴量抽出R-CNNの原理(2) CNNを用いた特徴量抽出
全8層 = (入力) 畳込み層×5 + 全結合層×2+出力層×1
* GoogLeNet in Keras
* https://joelouismarino.github.io/blog_posts/blog_googlenet_keras.html
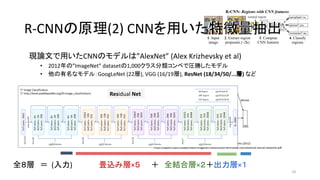
18. 現論文で用いたCNNのモデルは”AlexNet” (Alex Krizhevsky et al)
• 2012年の”ImageNet” datasetの1,000クラス分類コンペで圧勝したモデル
• 他の有名なモデル:GoogLeNet (22層), VGG (16/19層), ResNet (18/34/50/...層) など
18
出典:ImageNet Classification with Deep Convolutional Neural Networks (2012)
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
R-CNNの原理(2) CNNを用いた特徴量抽出R-CNNの原理(2) CNNを用いた特徴量抽出
全8層 = (入力) 畳込み層×5 + 全結合層×2+出力層×1
* リアルタイム画風変換とその未来
* https://engineering.linecorp.com/ja/blog/detail/105
Visual Geometry Group
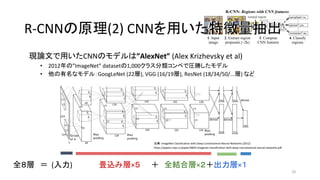
19. 現論文で用いたCNNのモデルは”AlexNet” (Alex Krizhevsky et al)
• 2012年の”ImageNet” datasetの1,000クラス分類コンペで圧勝したモデル
• 他の有名なモデル:GoogLeNet (22層), VGG (16/19層), ResNet (18/34/50/...層) など
19
出典:ImageNet Classification with Deep Convolutional Neural Networks (2012)
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
R-CNNの原理(2) CNNを用いた特徴量抽出R-CNNの原理(2) CNNを用いた特徴量抽出
全8層 = (入力) 畳込み層×5 + 全結合層×2+出力層×1
* Image Classification
* http://book.paddlepaddle.org/03.image_classification/ Residual Net
20. 現論文で用いたCNNのモデルは”AlexNet” (Alex Krizhevsky et al)
• 2012年の”ImageNet” datasetの1,000クラス分類コンペで圧勝したモデル
• 他の有名なモデル:GoogLeNet (22層), VGG (16/19層), ResNet (18/34/50/...層) など
20
出典:ImageNet Classification with Deep Convolutional Neural Networks (2012)
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
R-CNNの原理(2) CNNを用いた特徴量抽出R-CNNの原理(2) CNNを用いた特徴量抽出
全8層 = (入力) 畳込み層×5 + 全結合層×2+出力層×1
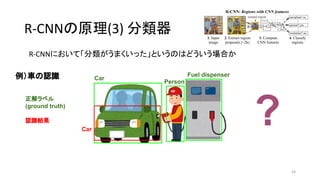
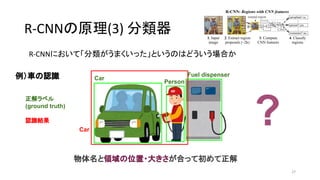
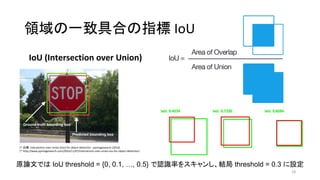
21. 22. 23. 24. 25. 26. 27. 28. 領域の一致具合の指標 IoU
IoU (Intersection over Union)
28
* 出典:Intersection over Union (IoU) for object detection - pyimagesearch (2016)
* http://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
原論文では IoU threshold = {0, 0.1, …, 0.5} で認識率をスキャンし、結局 threshold = 0.3 に設定
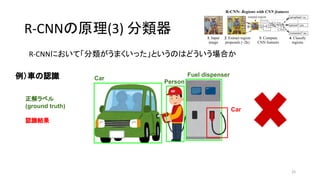
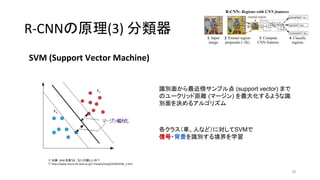
29. R-CNNの原理(3) 分類器
29
SVM (Support Vector Machine)
* 出典:SVM を使うと,なにが嬉しいの?
* http://www.neuro.sfc.keio.ac.jp/~masato/study/SVM/SVM_1.htm
識別面から最近傍サンプル点 (support vector) まで
のユークリッド距離 (マージン) を最大化するような識
別面を決めるアルゴリズム
各クラス(車、人など)に対してSVMで
信号・背景を識別する境界を学習
30. R-CNNの原点
原論文:
Rich feature hierarchies for accurate object detection
and semantic segmentation (2013)
https://arxiv.org/abs/1311.2524
30
1. 入力画像に対して、
2. 物体が写っている領域の候補 (region proposal) を Selective Search で約2,000個抽出し、
a. CNNのインプットの大きさに合うようにそれぞれの領域中の画像をリサイズし、
3. それぞれの領域に対してCNN (AlexNet) で特徴量 (feature) を計算し、
4. それぞれの領域になにが写っているか Support Vector Machine で分類する
31. 32. オリジナルR-CNNの欠点
学習が多段の処理になっていて煩雑
1. まず”ImageNet” dataset(1画像に1物体)でCNNをpretrain
2. “VOC” dataset(1画像に複数物体)でCNNをfine-tuning*
*fine-tuning: 上流の層の重みは固定し、全結合層など下流の層の重みのみを trainingすること
3. CNNの出力側にSVMを載せて学習
4. 矩形回帰の学習
実行時間が遅い
• 領域候補 2,000 個に対してそれぞれCNNを走らせている
• 認識時間 10-45 s/image @ Nvidia Tesla K40 (cf: 最新Tesla P100はThroughput~10倍)
➡ 多数の”進化版”が考案されている 32
(参考)論文紹介:Fast R-CNN & Faster R-CNN
https://www.slideshare.net/takashiabe338/fast-rcnnfaster-rcnn
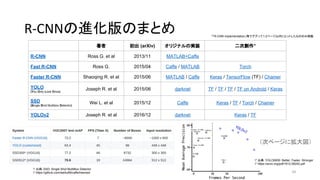
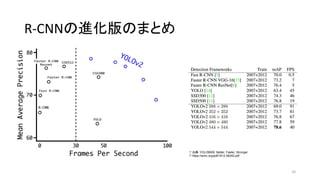
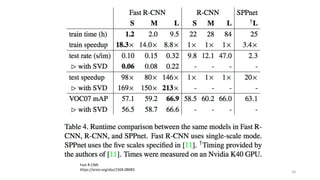
33. 34. R-CNNの進化版のまとめ
34
著者 初出 (arXiv) オリジナルの実装 二次創作*
R-CNN Ross G. et al 2013/11 MATLAB+Caffe
Fast R-CNN Ross G. 2015/04 Caffe / MATLAB Torch
Faster R-CNN Shaoqing R. et at 2015/06 MATLAB / Caffe Keras / TensorFlow (TF) / Chainer
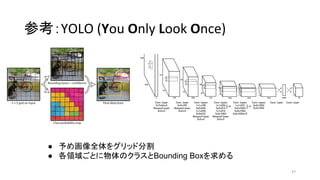
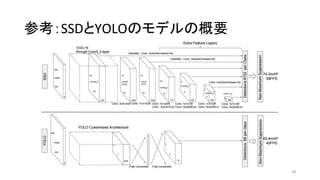
YOLO
(You Only Look Once)
Joseph R. et al 2015/06 darknet TF / TF / TF / TF on Android / Keras
SSD
(Single Shot Multibox Detector)
Wei L. et al 2015/12 Caffe Keras / TF / Torch / Chainer
YOLOv2 Joseph R. et al 2016/12 darknet Keras / TF
*「R-CNN implementation」等でググって1-2ページ以内にヒットしたもののみ掲載
* 出典:SSD: Single Shot MultiBox Detector
* https://github.com/weiliu89/caffe/tree/ssd
* 出典:YOLO9000: Better, Faster, Stronger
* https://arxiv.org/pdf/1612.08242.pdf
(次ページに拡大図)
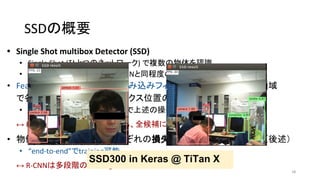
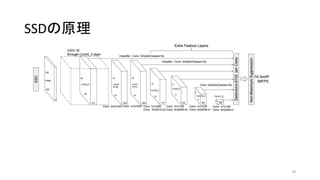
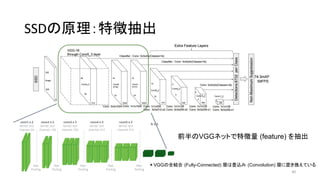
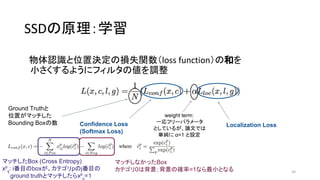
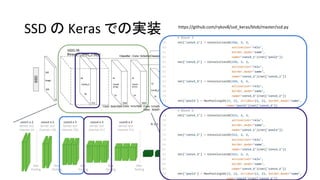
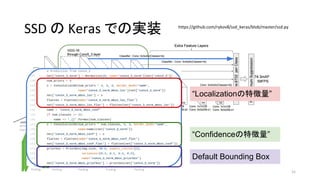
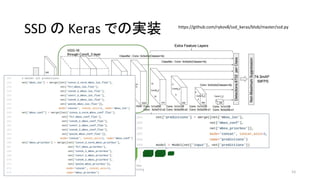
35. 36. 37. SSDの概要
• Single Shot multibox Detector (SSD)
• Single Shot (ひとつのネットワーク) で複数の物体を認識
• YOLOv1よりも速く、Faster R-CNNと同程度の精度
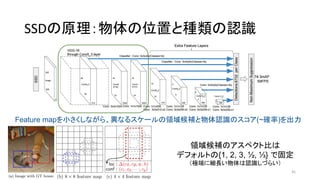
• Feature mapに対して小さな畳み込みフィルタをかけ、それぞれの領域
で各物体クラスのスコアとボックス位置のオフセットを予測(後述)
• 異なるスケール・アスペクト比で上述の操作を繰り返す
↔ R-CNNは領域候補を出してから、全候補にCNNを走らせる
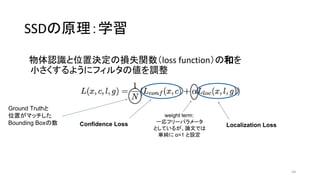
• 物体認識とボックス位置それぞれの損失関数の和を最小化させる(後述)
• “end-to-end”でtraining可能
↔ R-CNNは多段階のtrainingが必要
37
38. • Single Shot multibox Detector (SSD)
• Single Shot (ひとつのネットワーク) で複数の物体を認識
• YOLOv1よりも速く、Faster R-CNNと同程度の精度
• Feature mapに対して小さな畳み込みフィルタをかけ、それぞれの領域
で各物体クラスのスコアとボックス位置のオフセットを予測(後述)
• 異なるスケール・アスペクト比で上述の操作を繰り返す
↔ R-CNNは領域候補を出してから、全候補にCNNを走らせる
• 物体認識とボックス位置それぞれの損失関数の和を最小化させる(後述)
• “end-to-end”でtraining可能
↔ R-CNNは多段階のtrainingが必要
SSDの概要
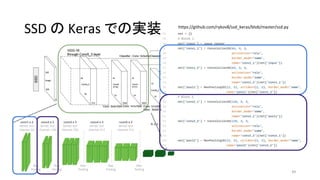
38
SSD300 in Keras @ TiTan X
39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. まとめ
• R-CNN (Regions with CNN features) は
領域分け+CNNの特徴量抽出
を組み合わせて、画像内の複数物体認識を行う
• オリジナルのR-CNNは動作が遅すぎて使い物にならない
• R-CNN改良版のSSDやYOLO
• ひとつのニューラルネットで両方のタスクを担う
• CNNで特徴量を認識してから領域分けを行う
53
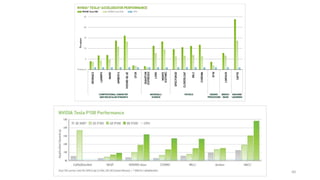
54. 55. 56. 57. 58. 59. 60. 61. 61
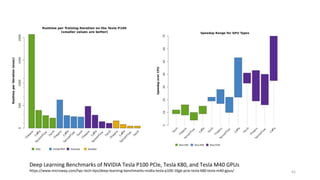
Deep Learning Benchmarks of NVIDIA Tesla P100 PCIe, Tesla K80, and Tesla M40 GPUs
https://www.microway.com/hpc-tech-tips/deep-learning-benchmarks-nvidia-tesla-p100-16gb-pcie-tesla-k80-tesla-m40-gpus/
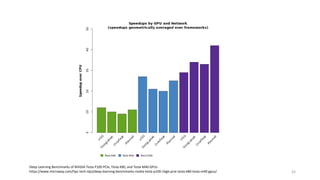
62. 62
Deep Learning Benchmarks of NVIDIA Tesla P100 PCIe, Tesla K80, and Tesla M40 GPUs
https://www.microway.com/hpc-tech-tips/deep-learning-benchmarks-nvidia-tesla-p100-16gb-pcie-tesla-k80-tesla-m40-gpus/






























![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)




























