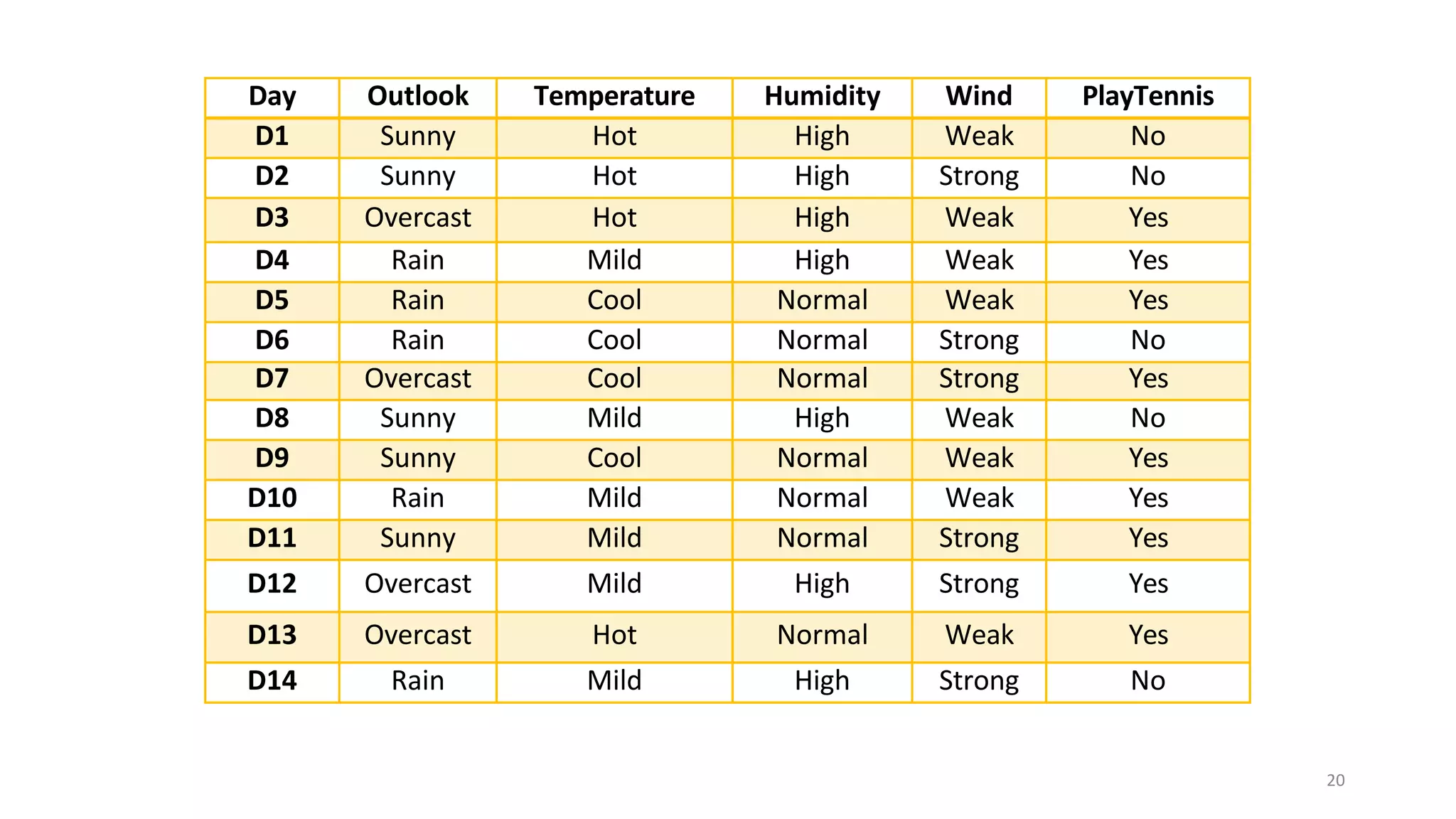
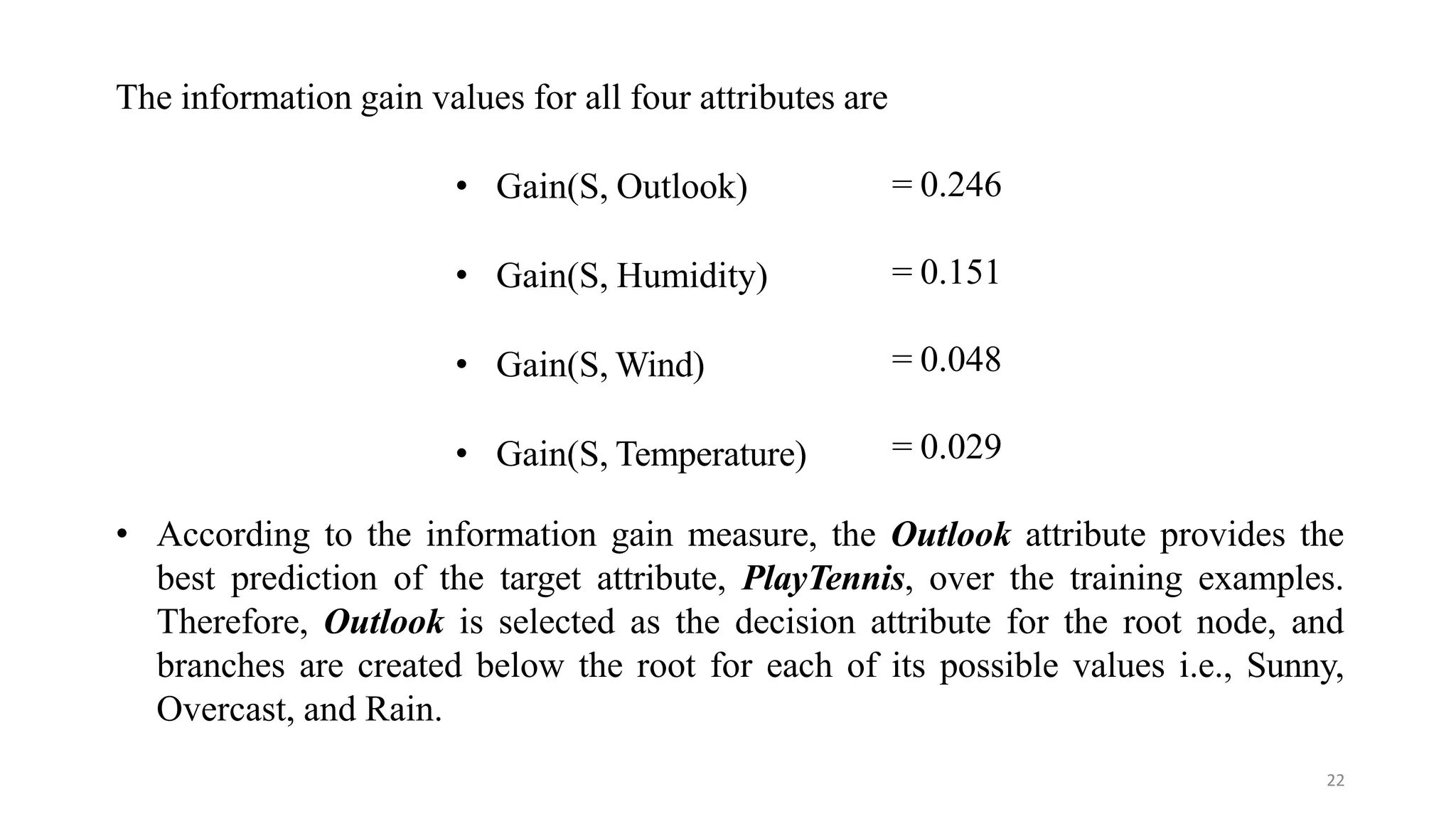
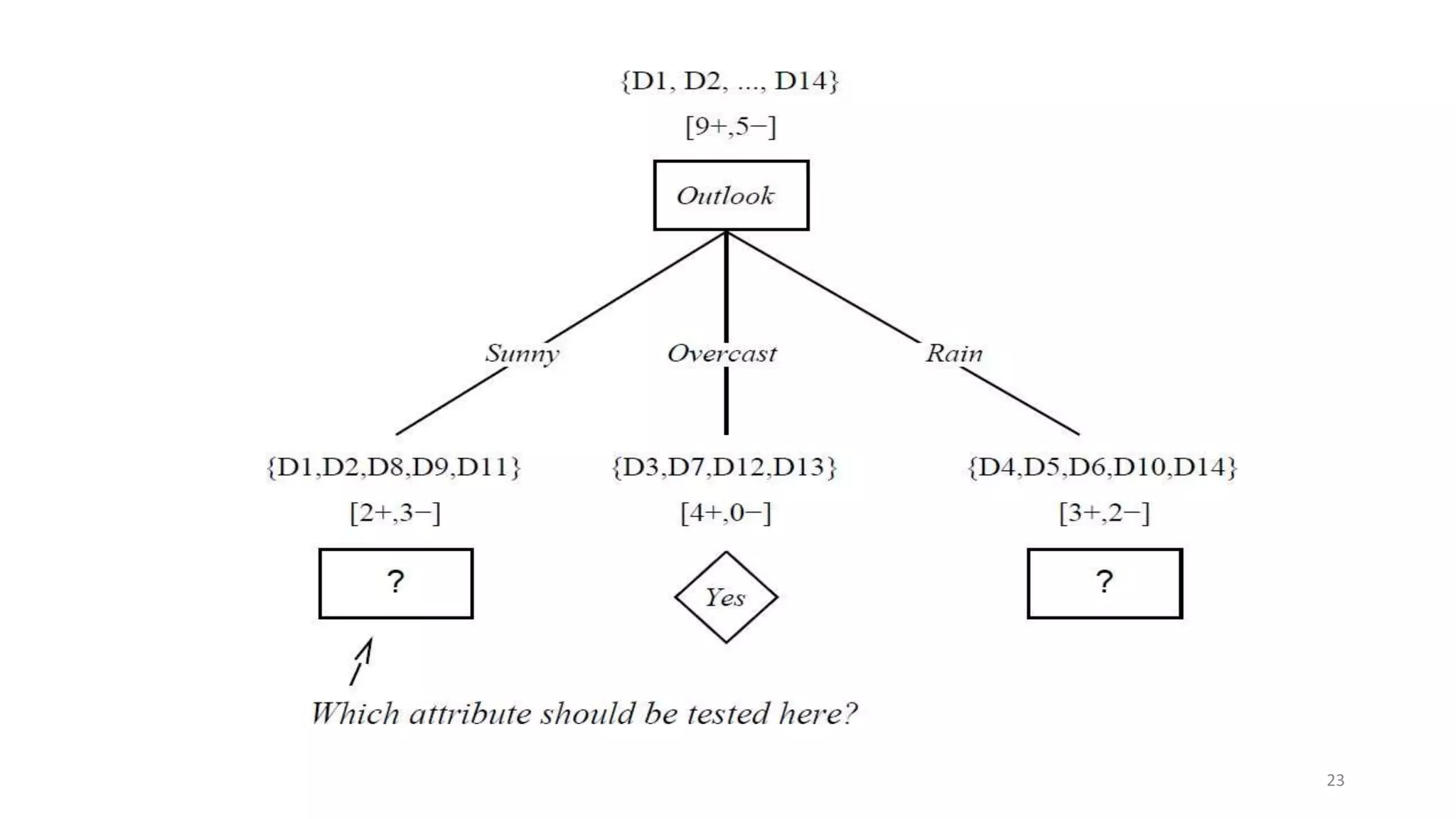
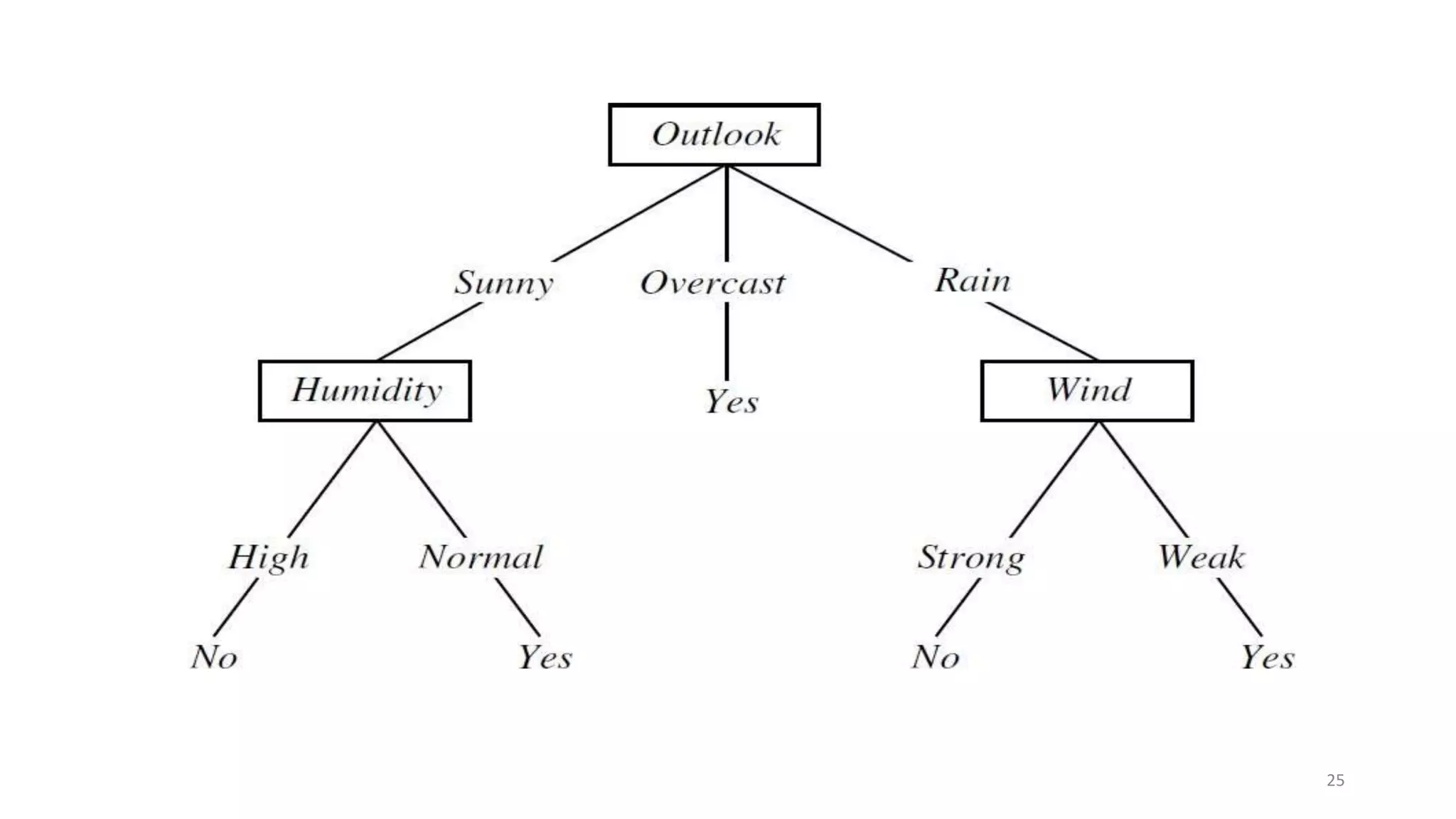
Decision tree learning involves creating a decision tree that classifies examples by sorting them from the root node to a leaf node. Each node tests an attribute and branches correspond to attribute values. Instances are classified by traversing the tree in this way. The ID3 algorithm uses information gain to select the attribute that best splits examples at each node, creating a greedy top-down search through possible trees. It calculates information gain, which measures the expected reduction in entropy (impurity), to determine which attribute best classifies examples at each step.
















![18
Example: Information gain
Let, Values(Wind) = {Weak, Strong}
S
SWeak
SStrong
= [9+, 5−]
= [6+, 2−]
= [3+, 3−]
Information gain of attribute Wind:
Gain(S, Wind) = Entropy(S) − 8/14 Entropy (SWeak) − 6/14 Entropy (SStrong)
= 0.94 – (8/14)* 0.811 – (6/14) *1.00
= 0.048](https://image.slidesharecdn.com/module31-220725150209-dcab5746/75/module_3_1-pptx-18-2048.jpg)