Download as PDF, PPTX

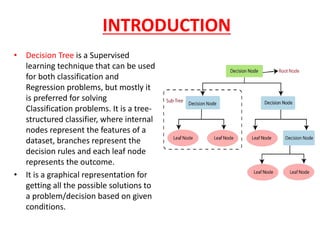

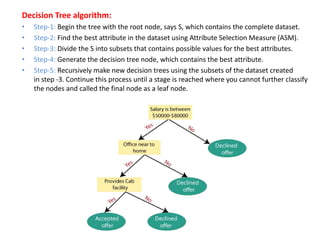



The document discusses decision tree learning and provides details about key concepts and algorithms. It defines decision trees as tree-structured classifiers that use internal nodes to represent dataset features, branches for decision rules, and leaf nodes for outcomes. The document then describes common decision tree terminology like root nodes, leaf nodes, splitting, branches, and pruning. It also outlines the basic steps of a decision tree algorithm, which involves beginning with a root node, finding the best attribute, dividing the dataset, generating decision tree nodes recursively, and ending with leaf nodes. Finally, it discusses two common attribute selection measures - information gain and Gini index - that are used to select the best attributes for decision tree nodes.

































































![COMIPLER_DESIGN_1[1].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/comiplerdesign11-230417141259-412c931b-thumbnail.jpg?width=640&height=640&fit=bounds)





















