Download as PDF, PPTX
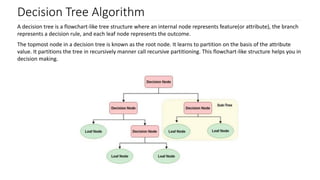
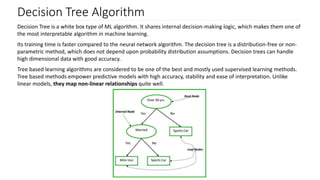








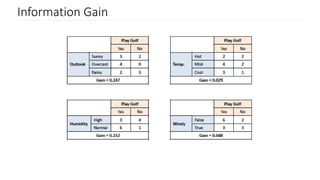
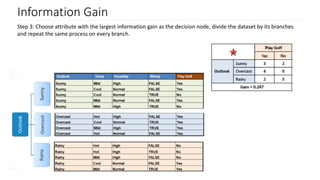

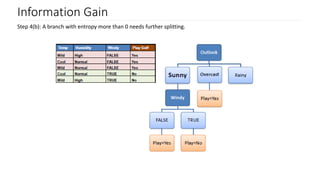
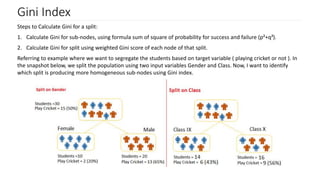

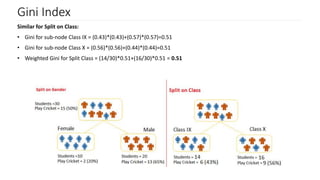




The document discusses decision trees as a key classification technique in machine learning, highlighting their structure, advantages, and common terminology. It explains the algorithm's process for creating a tree by recursively selecting attributes to split data based on measures like information gain and Gini index, which assess the purity of data subsets. Constraints on tree size are also addressed, including minimum samples for node splits, maximum depth, and maximum terminal nodes, essential for managing overfitting.




















































































