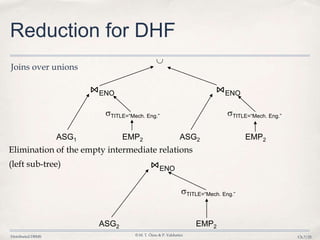
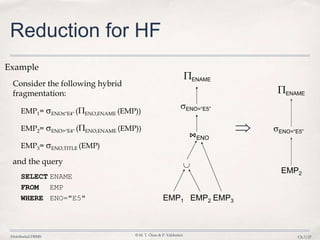
The document outlines the key steps in distributed query processing:
1. Query decomposition breaks a global query into subqueries that can be processed by individual database sites.
2. Data localization determines which database fragments contain the relevant data and substitutes fragment references in the query.
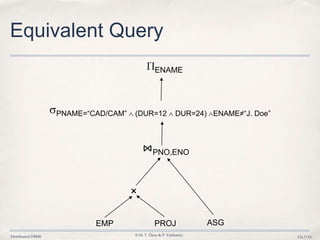
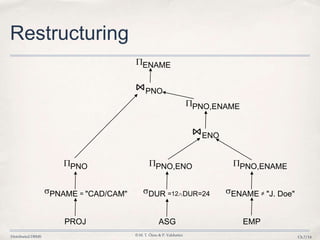
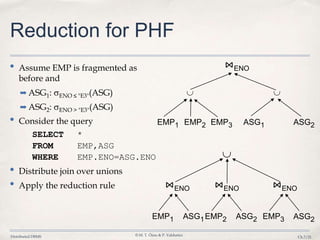
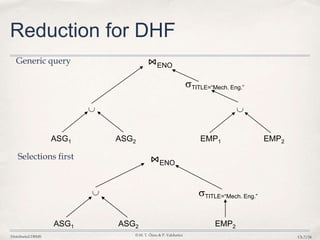
3. Query optimization techniques such as reduction rules are applied to minimize unnecessary data transfers and redundant processing across distributed fragments.









![Distributed DBMS © M. T. Özsu & P. Valduriez
Ch.7/10
Restructuring –Transformation
Rules
• Commutativity of binary operations
➡ R × S S × R
➡ R ⋈S S ⋈R
➡ R S S R
• Associativity of binary operations
➡ ( R × S) × T R × (S × T)
➡ (R ⋈S) ⋈T R ⋈ (S ⋈T)
• Idempotence of unary operations
➡ A’( A’(R)) A’(R)
➡ p1(A1)( p2(A2)(R)) p1(A1) p2(A2)(R)
where R[A] and A' A, A" A and A' A"
• Commuting selection with projection](https://image.slidesharecdn.com/7-querylocalization-140403161543-phpapp01/85/Database-7-query-localization-10-320.jpg)
![Distributed DBMS © M. T. Özsu & P. Valduriez
Ch.7/11
Restructuring – Transformation
Rules
• Commuting selection with binary operations
➡ p(A)(R × S) ( p(A) (R)) × S
➡ p(A
i)(R ⋈(A
j,B
k)S) ( p(A
i) (R)) ⋈(A
j,B
k)S
➡ p(A
i)(R T) p(A
i) (R) p(A
i) (T)
where Ai belongs to R and T
• Commuting projection with binary operations
➡ C(R × S) A’(R) × B’(S)
➡ C(R ⋈(A
j,B
k)S) A’(R) ⋈(A
j,B
k) B’(S)
➡ C(R S) C(R) C(S)
where R[A] and S[B]; C = A' B' where A' A, B' B](https://image.slidesharecdn.com/7-querylocalization-140403161543-phpapp01/85/Database-7-query-localization-11-320.jpg)