Downloaded 18 times






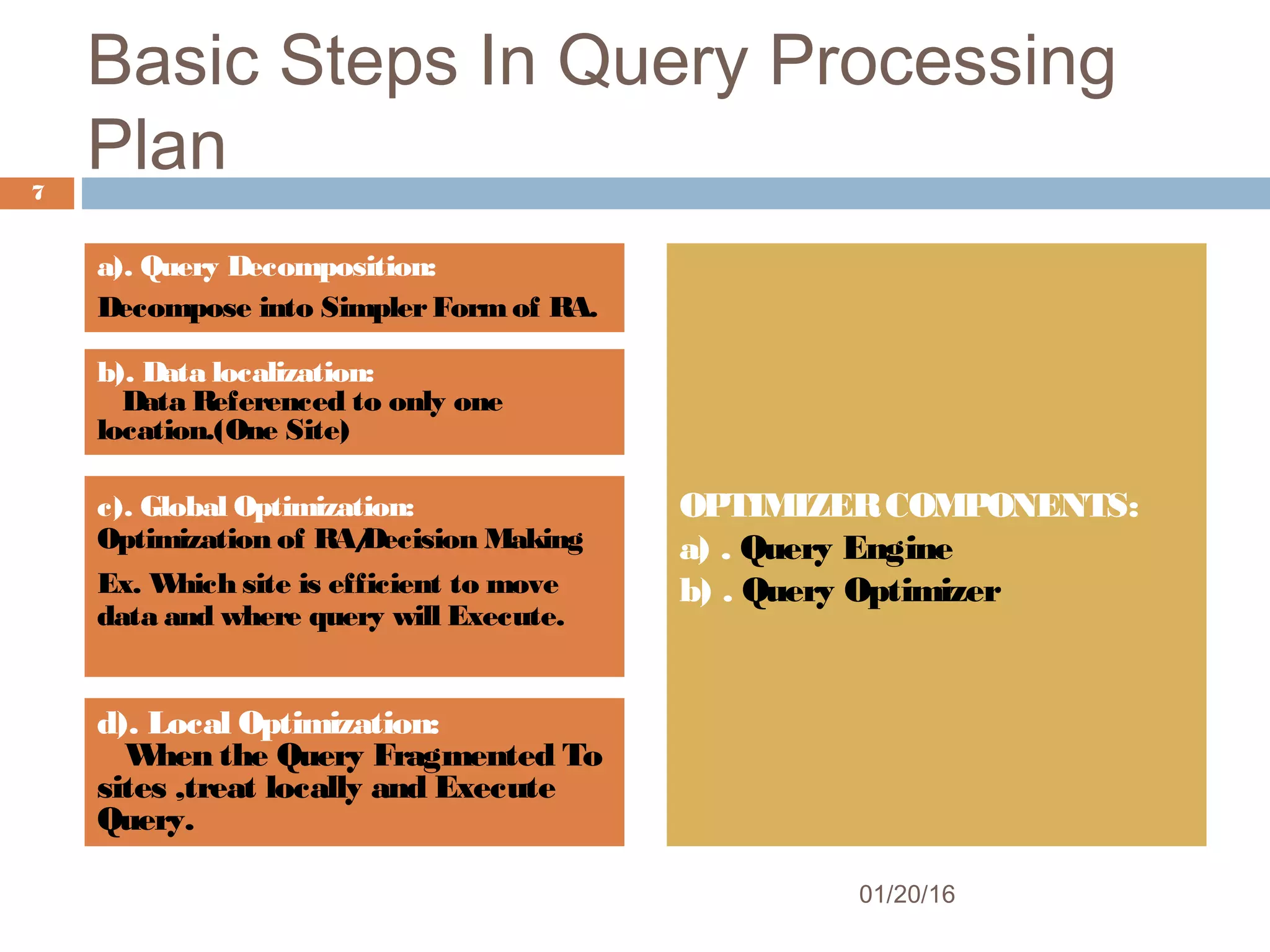









This document summarizes several reviews on query optimization in distributed databases. It discusses the key challenges in optimizing queries across multiple data sites including decomposing queries, determining where to move data to reduce communication costs, and calculating an efficient execution plan. The reviews covered explore techniques like dynamic programming, greedy algorithms, and ant colony optimization to generate low-cost query plans in distributed environments. Overall, the document outlines the basic process for optimizing queries in distributed databases and analyzes different approaches from prior work.















































