Downloaded 200 times





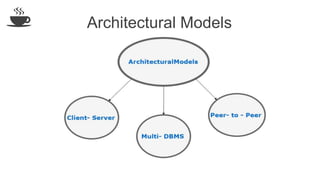


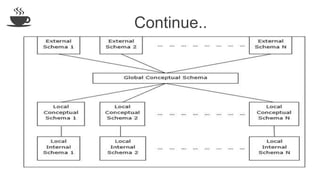





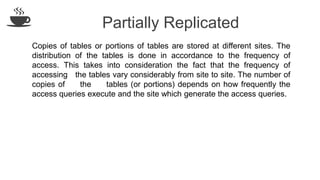














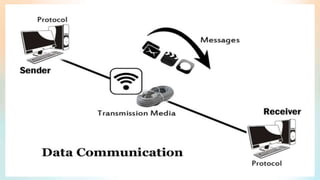




















The document discusses distributed database design, outlining its architecture, fragmentation methods, and concurrency control mechanisms. It highlights various design alternatives for data distribution, including non-replicated, fully replicated, partially replicated, and fragmented approaches, along with their advantages and disadvantages. Additionally, it explains essential concepts in data communication and concurrency control, emphasizing the complexity of managing distributed systems compared to centralized databases.

















































![Dimension reduction techniques[Feature Selection]](https://cdn.slidesharecdn.com/ss_thumbnails/dimensionreductiontechnibyaakankshajain-210625102243-thumbnail.jpg?width=640&height=640&fit=bounds)




























