Downloaded 55 times






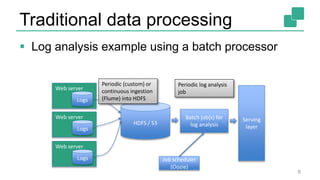
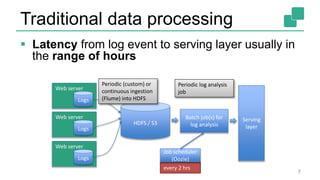
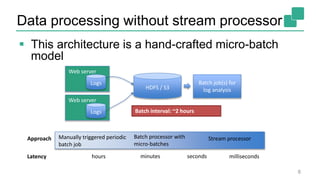
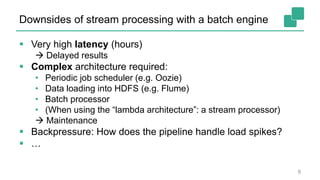
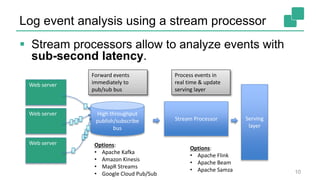
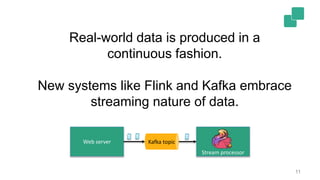
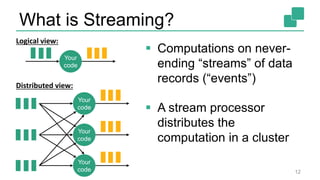
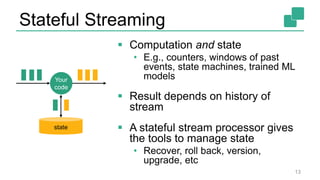

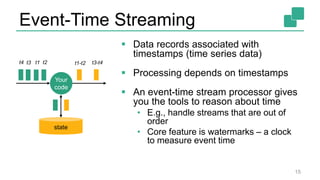
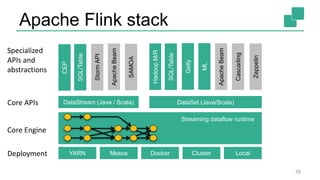



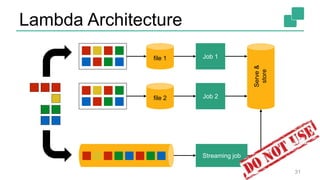



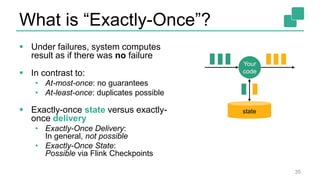
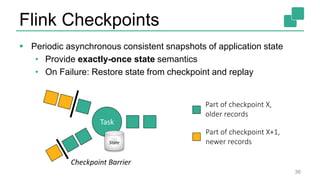
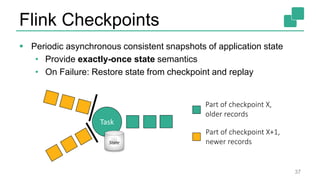
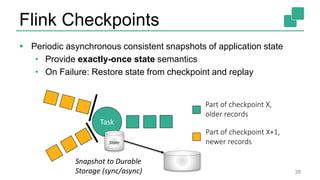
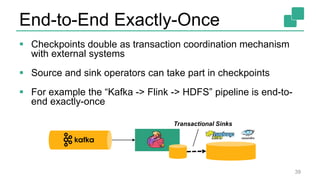
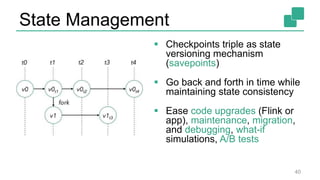









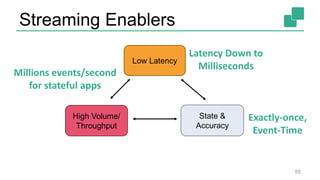











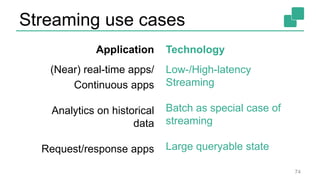


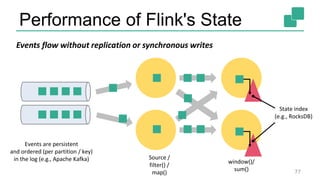
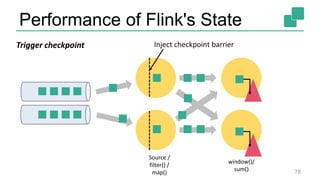
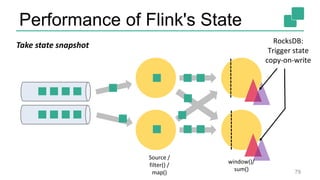
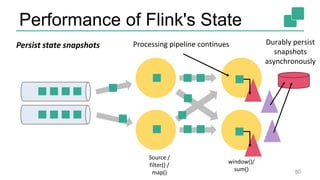
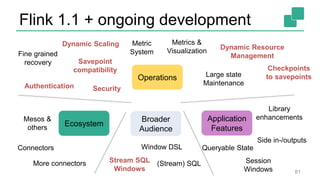








The document presents a detailed discussion on common myths about stream processing with Apache Flink, debunking misconceptions regarding approximation, exactly-once guarantees, throughput versus latency tradeoffs, and the misconception that streaming is solely for real-time data. It illustrates how Flink provides capabilities like low-latency processing, high throughput, and stateful streaming, promoting the efficient handling of unbounded datasets. The conclusion emphasizes that streaming frameworks like Flink can deliver accurate results under high data volumes without needing a batch processing system.























































































