Downloaded 1,092 times





![Message Delivery Semantics
At most once [0,1]
• Messages my be lost
• Messages never redelivered
At least once [1 .. n]
• Messages will never be lost
• but messages may be redelivered (might be ok if consumer can handle it)
Exactly once [1]
• Messages are never lost
• Messages are never redelivered
• Perfect message delivery
• Incurs higher latency for transactional semantics
2014 © Trivadis
Apache Storm vs. Spark Streaming – Two Stream Processing Platforms compared
3rd December 2014
15](https://image.slidesharecdn.com/apachestormvsapachespark-v1-141203182123-conversion-gate02/75/Apache-Storm-vs-Spark-Streaming-two-Stream-Processing-Platforms-compared-15-2048.jpg)














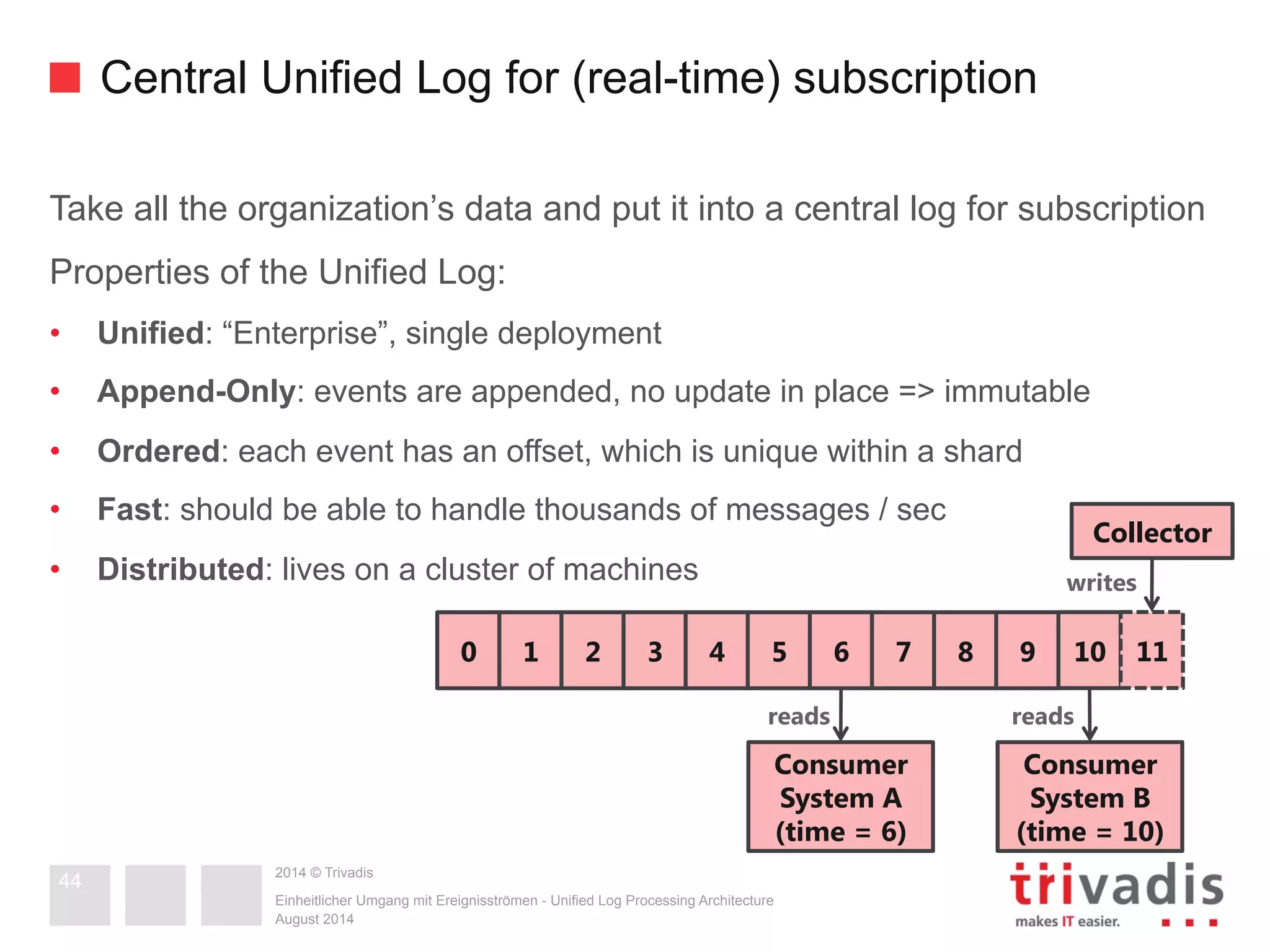
![Unified Log
That’s what most people think about logs
137.229.78.245 - - [02/Jul/2012:13:22:26 -0800] "GET /wp-admin/images/date-button.gif HTTP/1.1" 200 111
137.229.78.245 - - [02/Jul/2012:13:22:26 -0800] "GET /wp-includes/js/tinymce/langs/wp-langs-en.js?ver=349-20805 HTTP/1.1" 200 13593
137.229.78.245 - - [02/Jul/2012:13:22:26 -0800] "GET /wp-includes/js/tinymce/wp-tinymce.php?c=1&ver=349-20805 HTTP/1.1" 200 101114
137.229.78.245 - - [02/Jul/2012:13:22:28 -0800] "POST /wp-admin/admin-ajax.php HTTP/1.1" 200 30747
137.229.78.245 - - [02/Jul/2012:13:22:40 -0800] "POST /wp-admin/post.php HTTP/1.1" 302 -
137.229.78.245 - - [02/Jul/2012:13:22:40 -0800] "GET /wp-admin/post.php?post=387&action=edit&message=1 HTTP/1.1" 200 73160
137.229.78.245 - - [02/Jul/2012:13:22:41 -0800] "GET /wp-includes/css/editor.css?ver=3.4.1 HTTP/1.1" 304 -
137.229.78.245 - - [02/Jul/2012:13:22:41 -0800] "GET /wp-includes/js/tinymce/langs/wp-langs-en.js?ver=349-20805 HTTP/1.1" 304 -
137.229.78.245 - - [02/Jul/2012:13:22:41 -0800] "POST /wp-admin/admin-ajax.php HTTP/1.1" 200 30809
But this is what we mean here by Log
• a structured log (records are numbered beginning with 0 based on order they
2014 © Trivadis
are written)
• aka. commit log or
journal
1st record Next record
Einheitlicher Umgang mit Ereignisströmen - Unified Log Processing Architecture
August 2014
43
written
0 1 2 3 4 5 6 7 8 9 10 11](https://image.slidesharecdn.com/apachestormvsapachespark-v1-141203182123-conversion-gate02/75/Apache-Storm-vs-Spark-Streaming-two-Stream-Processing-Platforms-compared-43-2048.jpg)




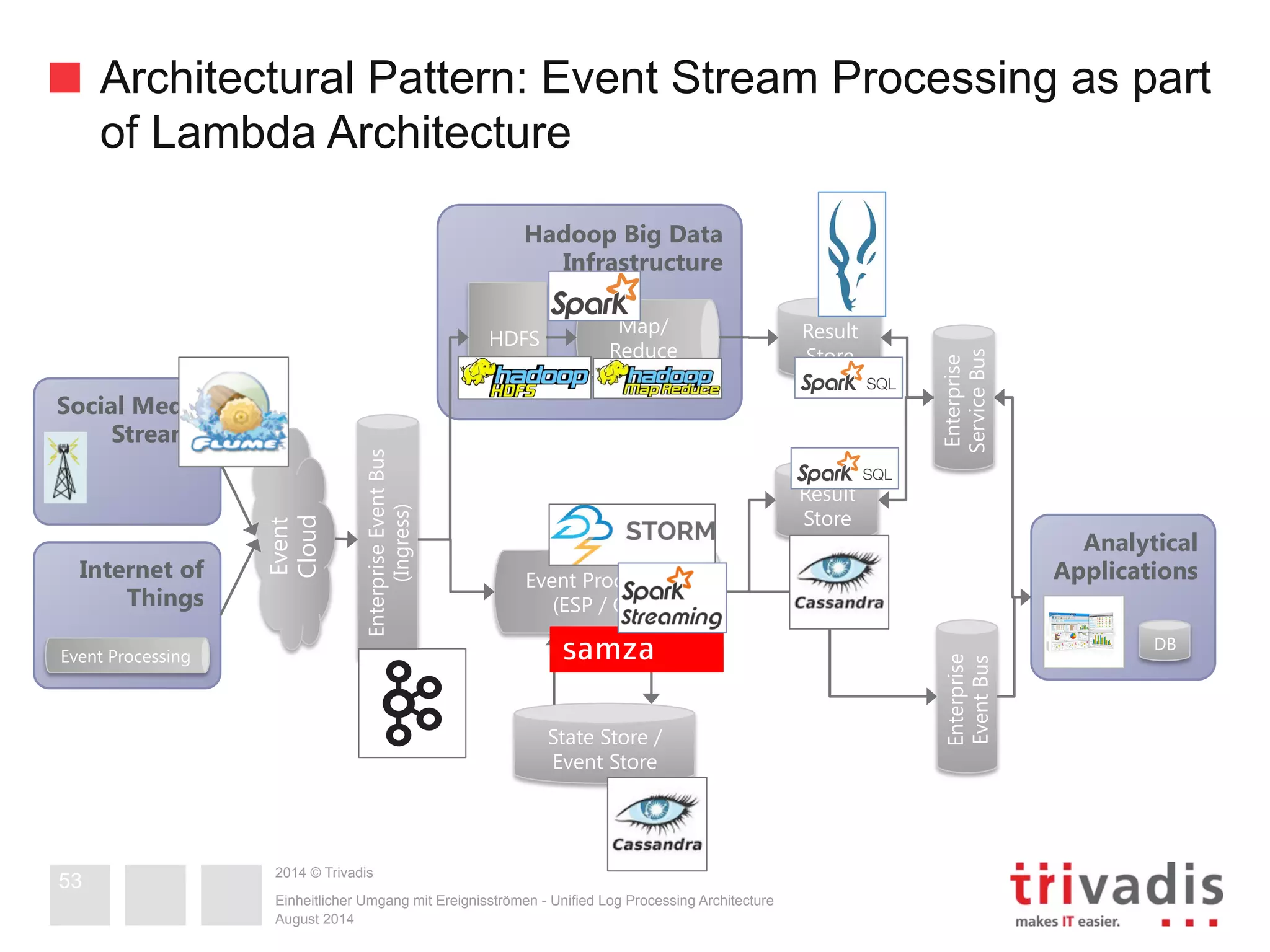
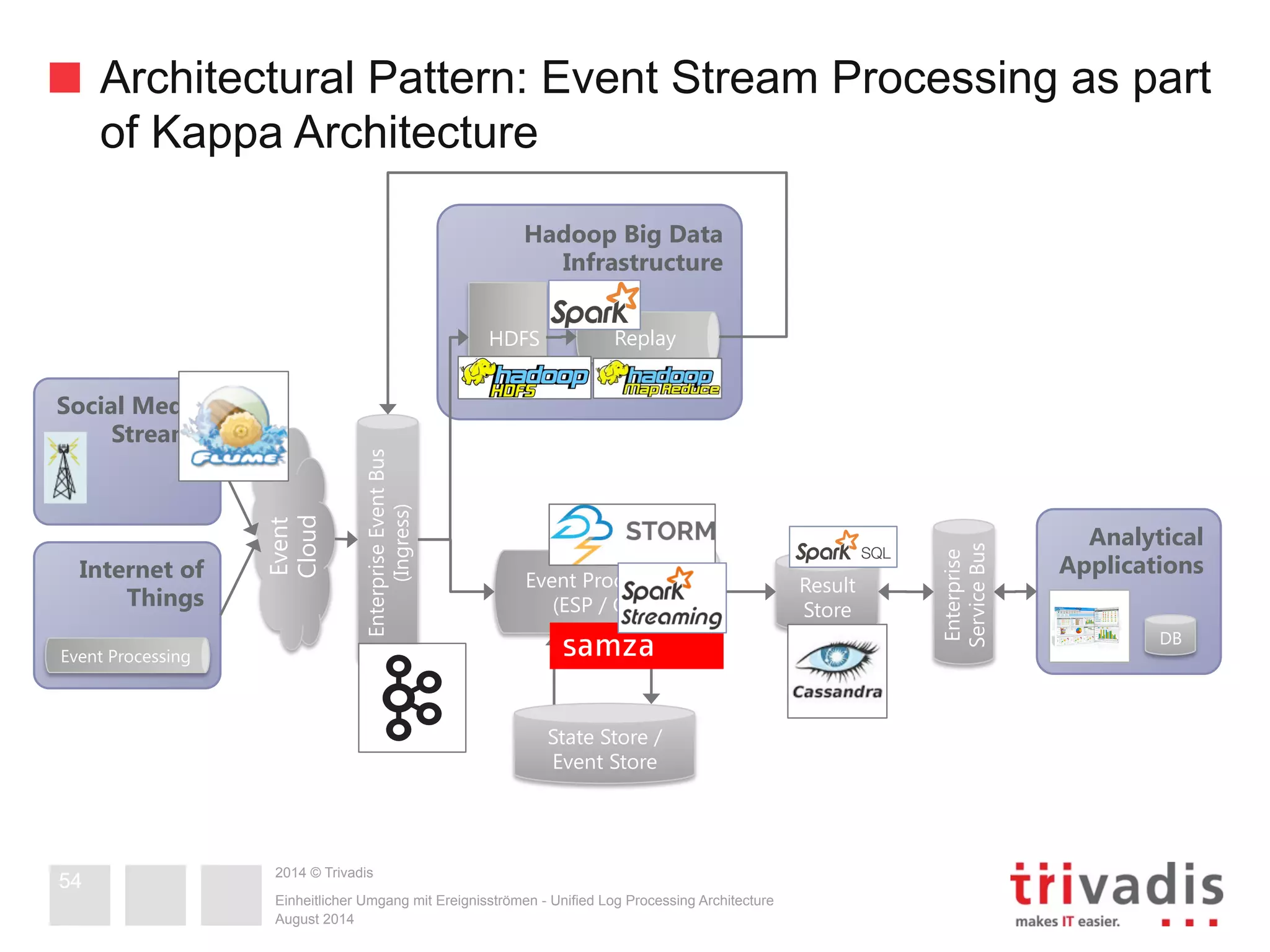

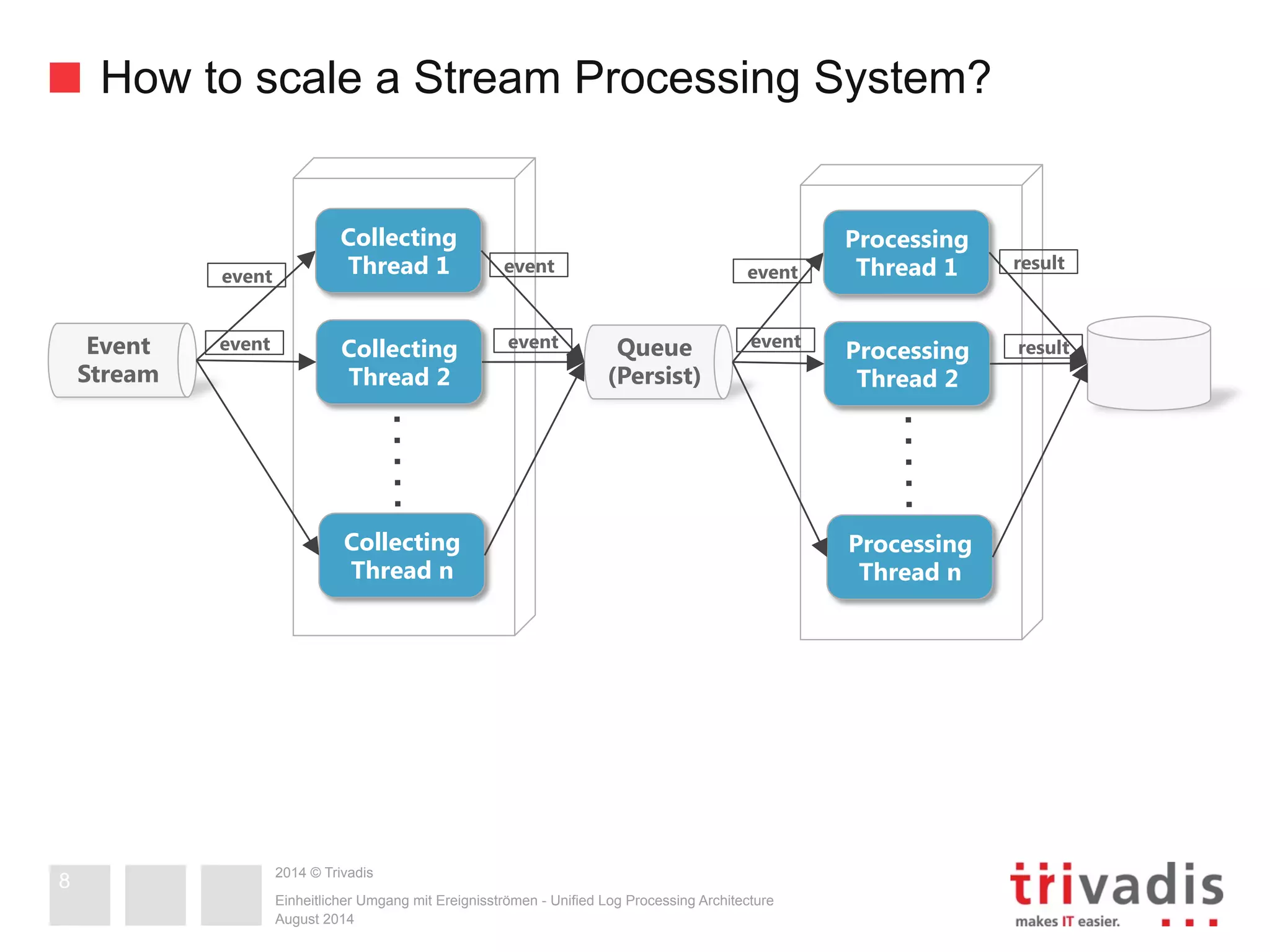
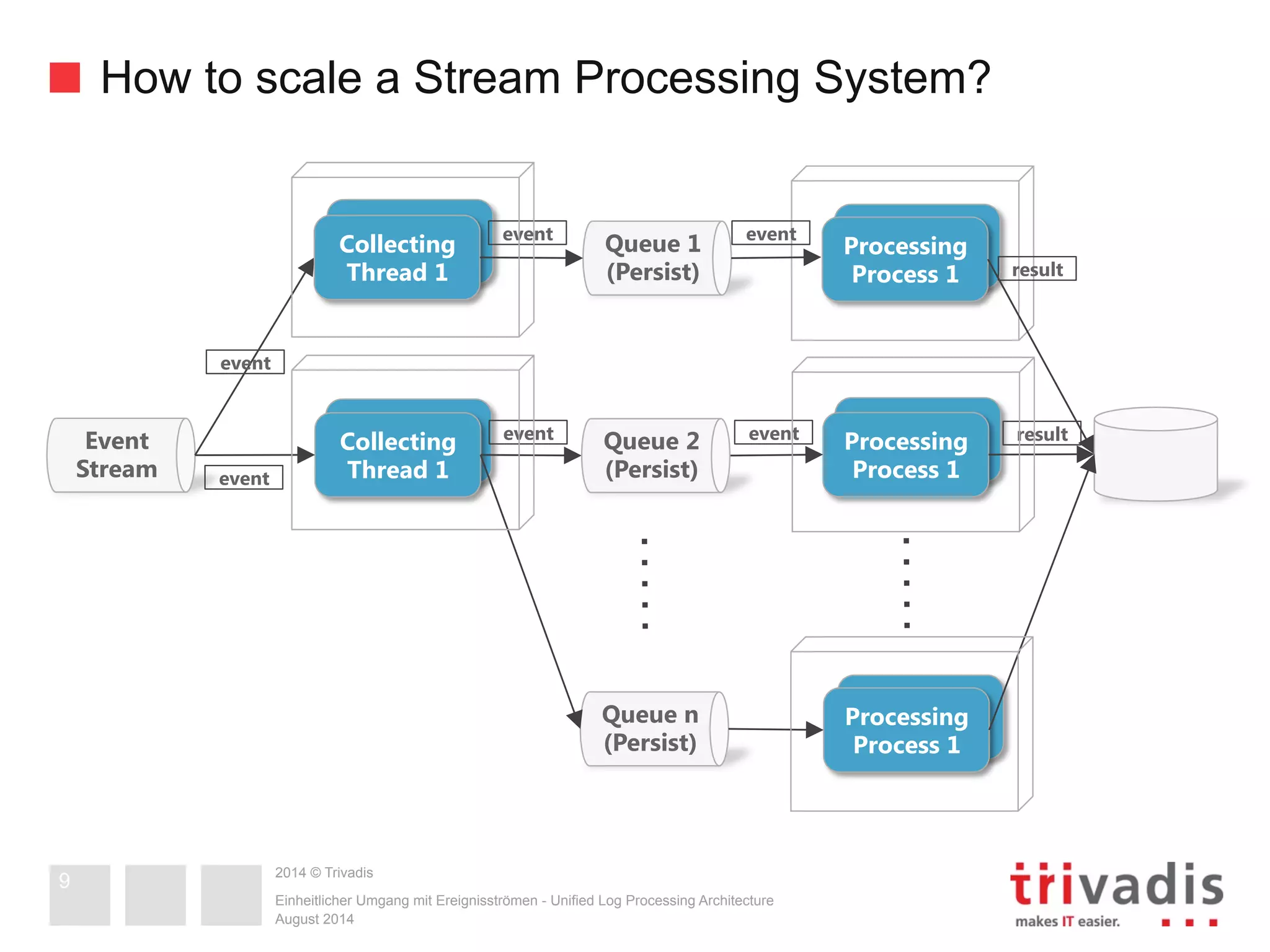
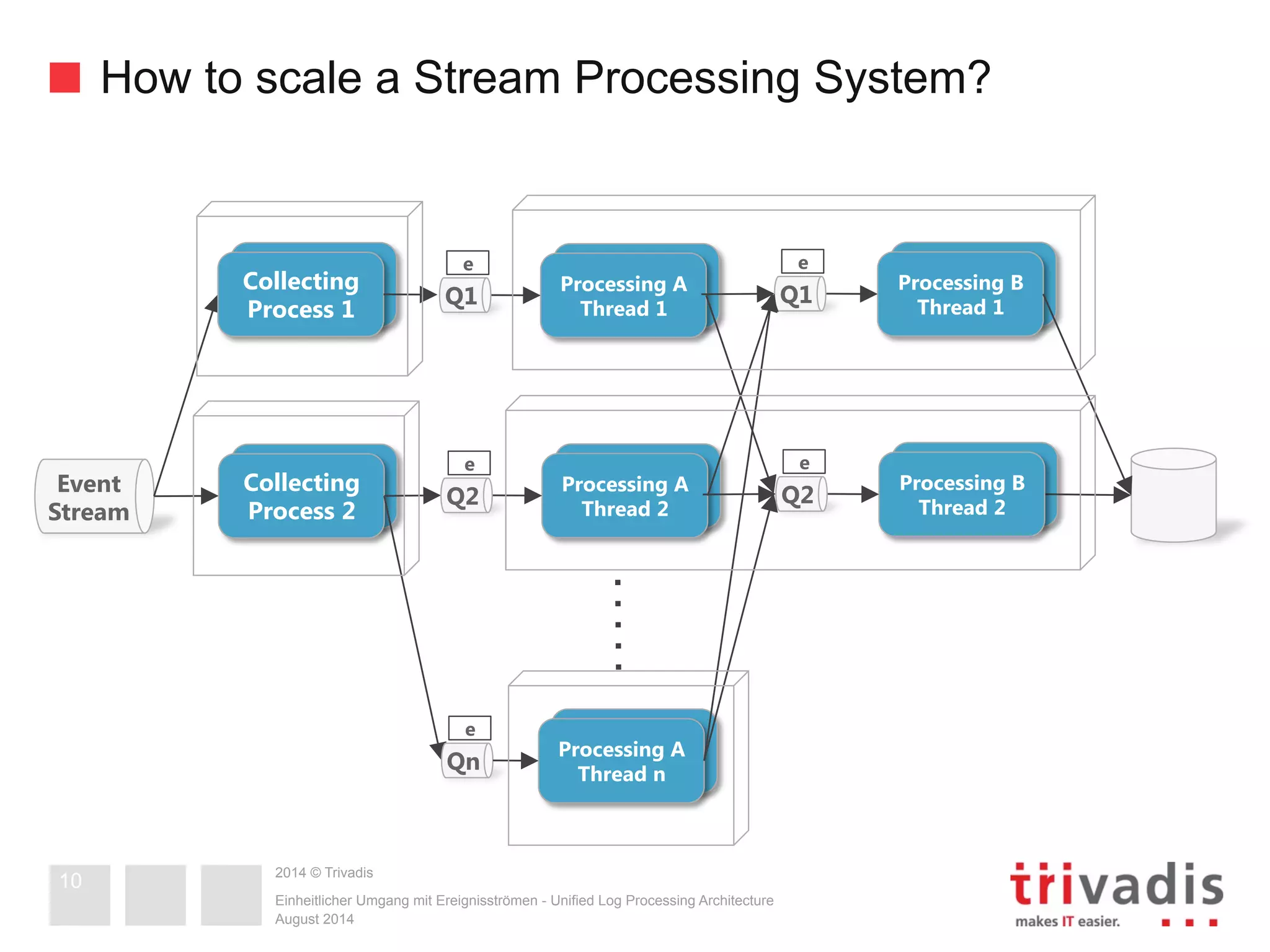
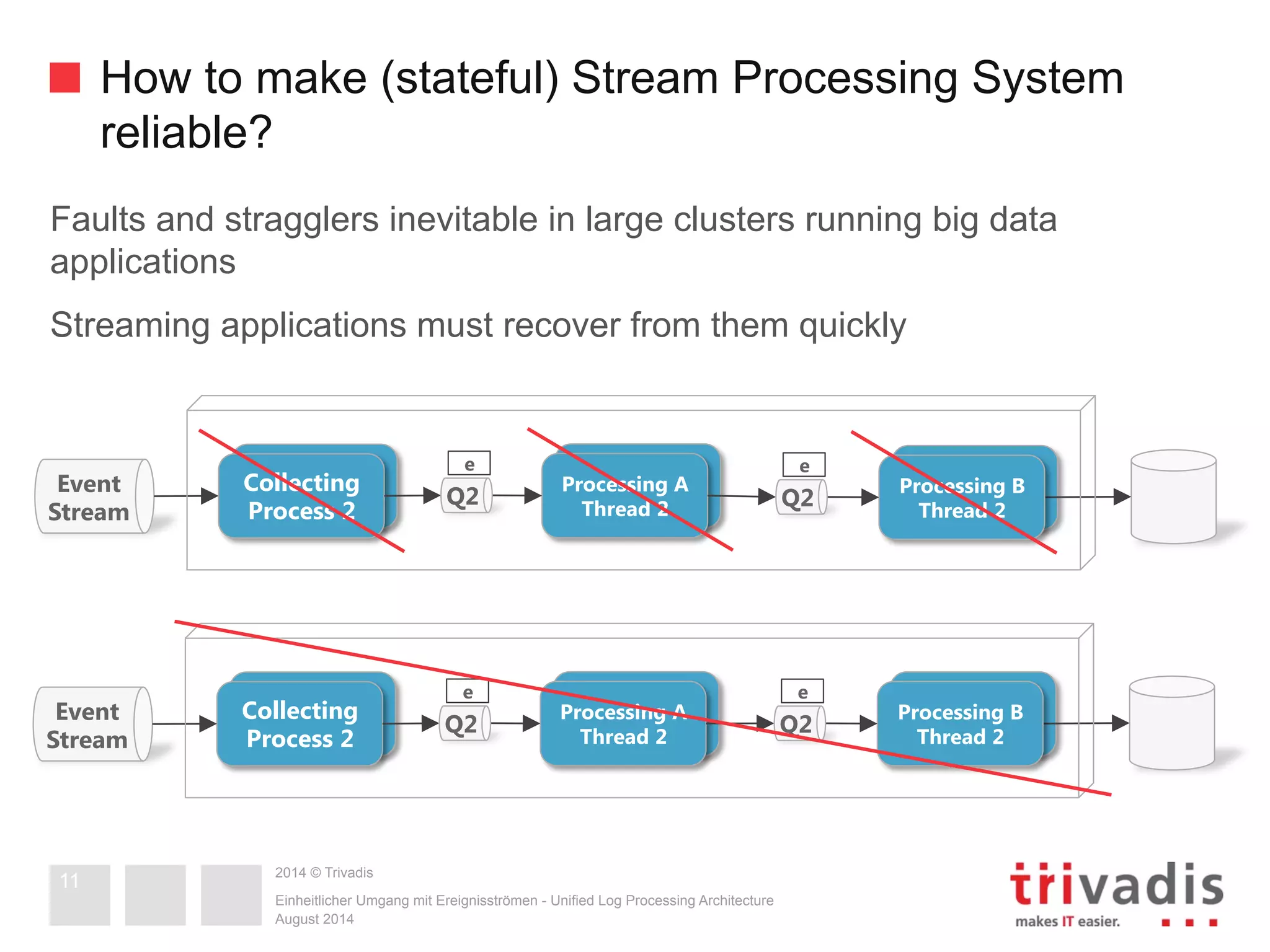
The document compares Apache Storm and Spark Streaming, two prominent stream processing platforms, highlighting their architecture, core concepts, and use cases. It discusses the design of stream processing systems, the importance of response latency, and how to ensure reliability in stateful systems. Both platforms offer distinct features, with Storm focused on real-time processing and Spark providing a more general-purpose solution with capabilities for batch and stream processing.