Downloaded 35 times























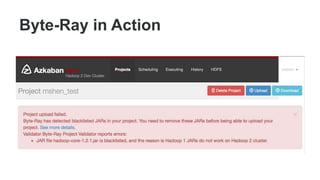





The document summarizes the past, present, and future of Hadoop at LinkedIn. It describes how LinkedIn initially implemented PYMK on Oracle in 2006, then moved to Hadoop in 2008 with 20 nodes, scaling up to over 10,000 nodes and 1000 users by 2016 running various big data frameworks. It discusses the challenges of scaling hardware and processes, and how LinkedIn developed tools like HDFS Dynamometer, Dr. Elephant, Byte-Ray and SoakCycle to help with scaling, performance tuning, dependency management and integration testing of Hadoop clusters. The future may include the Dali project to make data more accessible through different views.











































































































