Download as PDF, PPTX




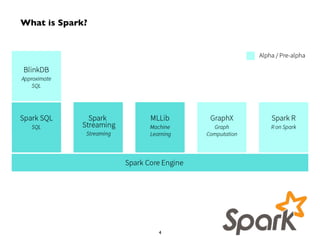





































![60
1. extract text
from the tweet
https://twitter.com/
andy_bf/status/
16222269370011648
"Ceci n'est pas un tweet"
2. sequence
text as bigrams
tweet.sliding(2).toSeq ("Ce", "ec", "ci", …, )
3. convert
bigrams into
numbers
seq.map(_.hashCode()) (2178, 3230, 3174, …, )
4. index into
sparse tf vector!
seq.map(_.hashCode() %
1000)
(178, 230, 174, …, )
5. increment
feature count
Vector.sparse(1000, …) (1000, [102, 104, …],
[0.0455, 0.0455, …])
Demo: Twitter Streaming Language Classifier
From tweets to ML features,
approximated as sparse
vectors:](https://image.slidesharecdn.com/spstreaming-150326061042-conversion-gate01/85/QCon-Sao-Paulo-Real-Time-Analytics-with-Spark-Streaming-60-320.jpg)
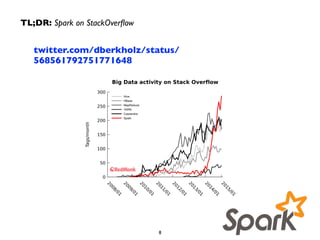
![Demo: Twitter Streaming Language Classifier
Sample Code + Output:
gist.github.com/ceteri/835565935da932cb59a2
val sc = new SparkContext(new SparkConf())!
val ssc = new StreamingContext(conf, Seconds(5))!
!
val tweets = TwitterUtils.createStream(ssc, Utils.getAuth)!
val statuses = tweets.map(_.getText)!
!
val model = new KMeansModel(ssc.sparkContext.objectFile[Vector]
(modelFile.toString).collect())!
!
val filteredTweets = statuses!
.filter(t => !
model.predict(Utils.featurize(t)) == clust)!
filteredTweets.print()!
!
ssc.start()!
ssc.awaitTermination()!
CLUSTER 1:
TLあんまり見ないけど
@くれたっら
いつでもくっるよ۹(δωδ)۶
そういえばディスガイアも今日か
CLUSTER 4:
صدام بعد روحت العروبه
قالوا
العروبه تحيى سلمان مع
واقول
RT @vip588: √ مي فولو √ متابعني زيادة √ االن للمتواجدين
vip588 √ √ رتويت عمل للي فولو √ للتغريدة رتويت √ باك فولو
بيستفيد ما يلتزم ما اللي …
سورة ن](https://image.slidesharecdn.com/spstreaming-150326061042-conversion-gate01/85/QCon-Sao-Paulo-Real-Time-Analytics-with-Spark-Streaming-61-320.jpg)










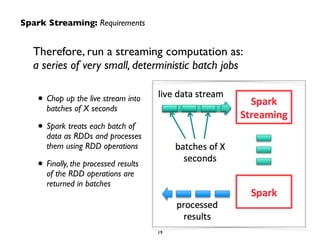
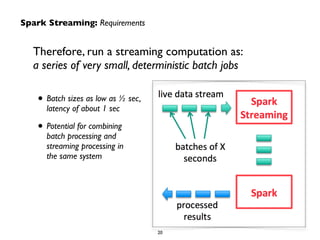
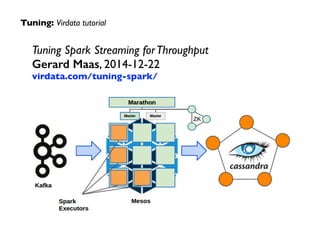
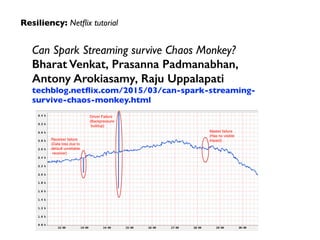
The document provides an overview of real-time analytics using Spark Streaming. It discusses Spark Streaming's micro-batch approach of treating streaming data as a series of small batch jobs. This allows for low-latency analysis while integrating streaming and batch processing. The document also covers Spark Streaming's fault tolerance mechanisms and provides several examples of companies like Pearson, Guavus, and Sharethrough using Spark Streaming for real-time analytics in production environments.


































































































