Downloaded 18 times



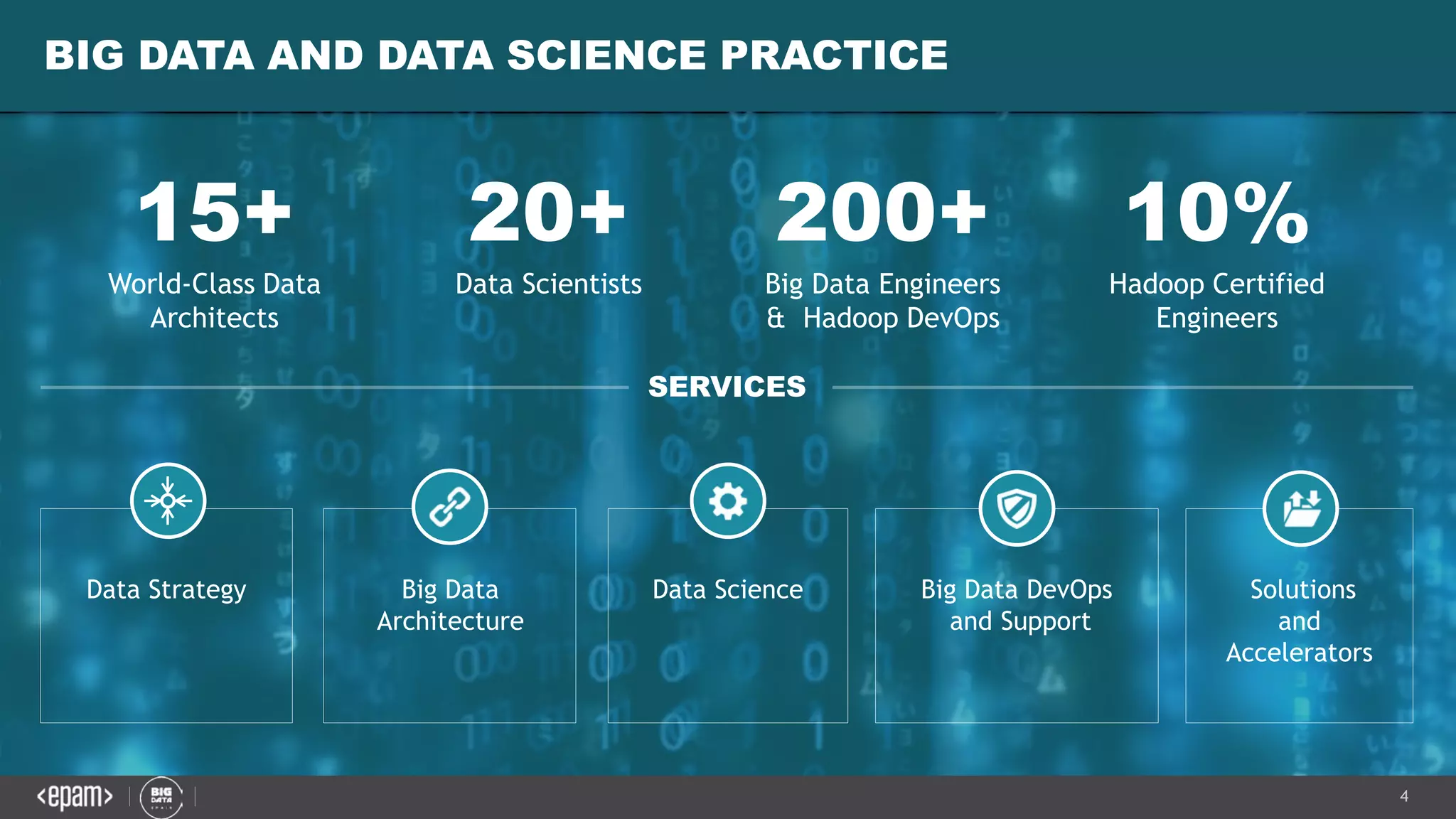



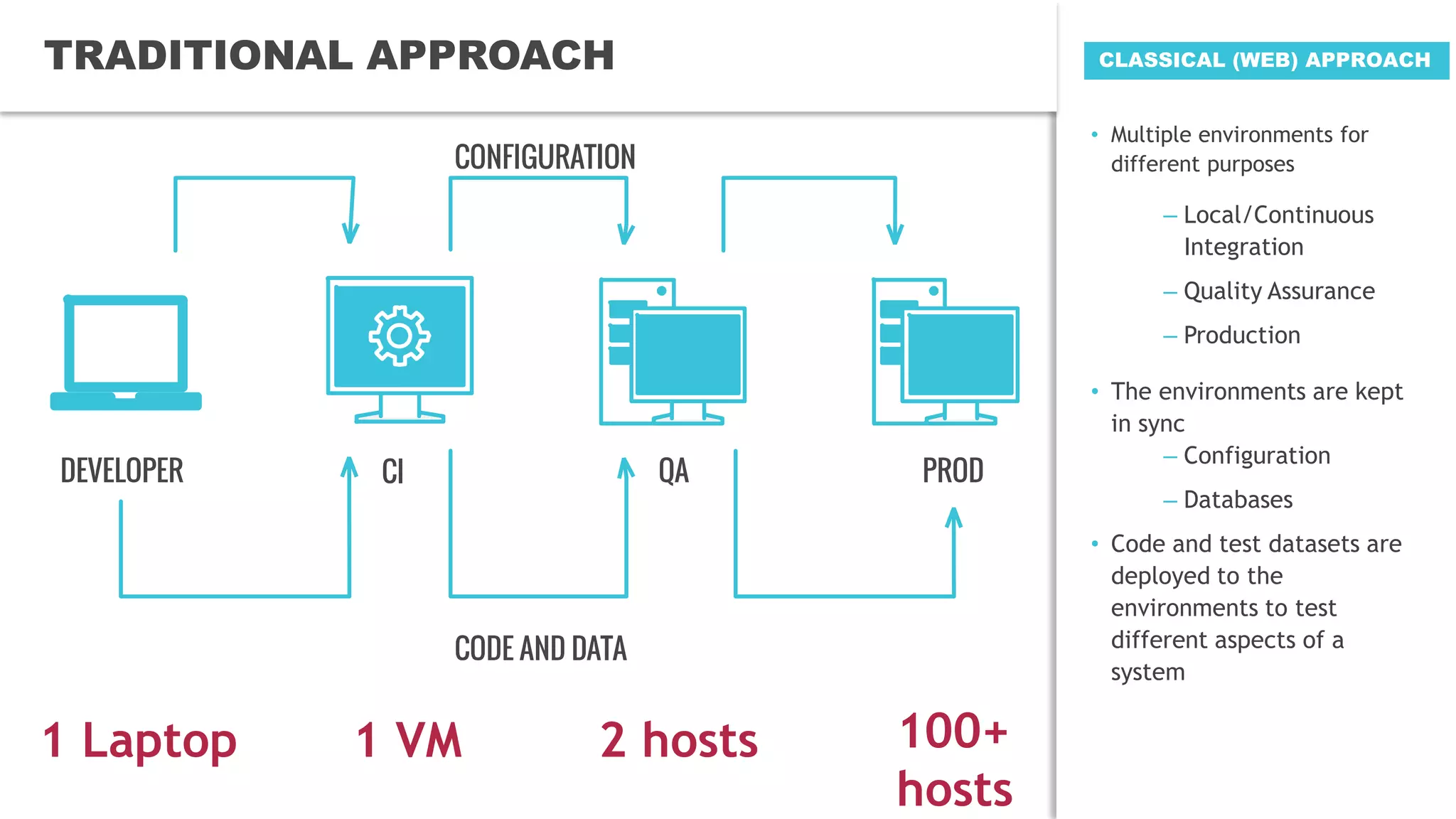



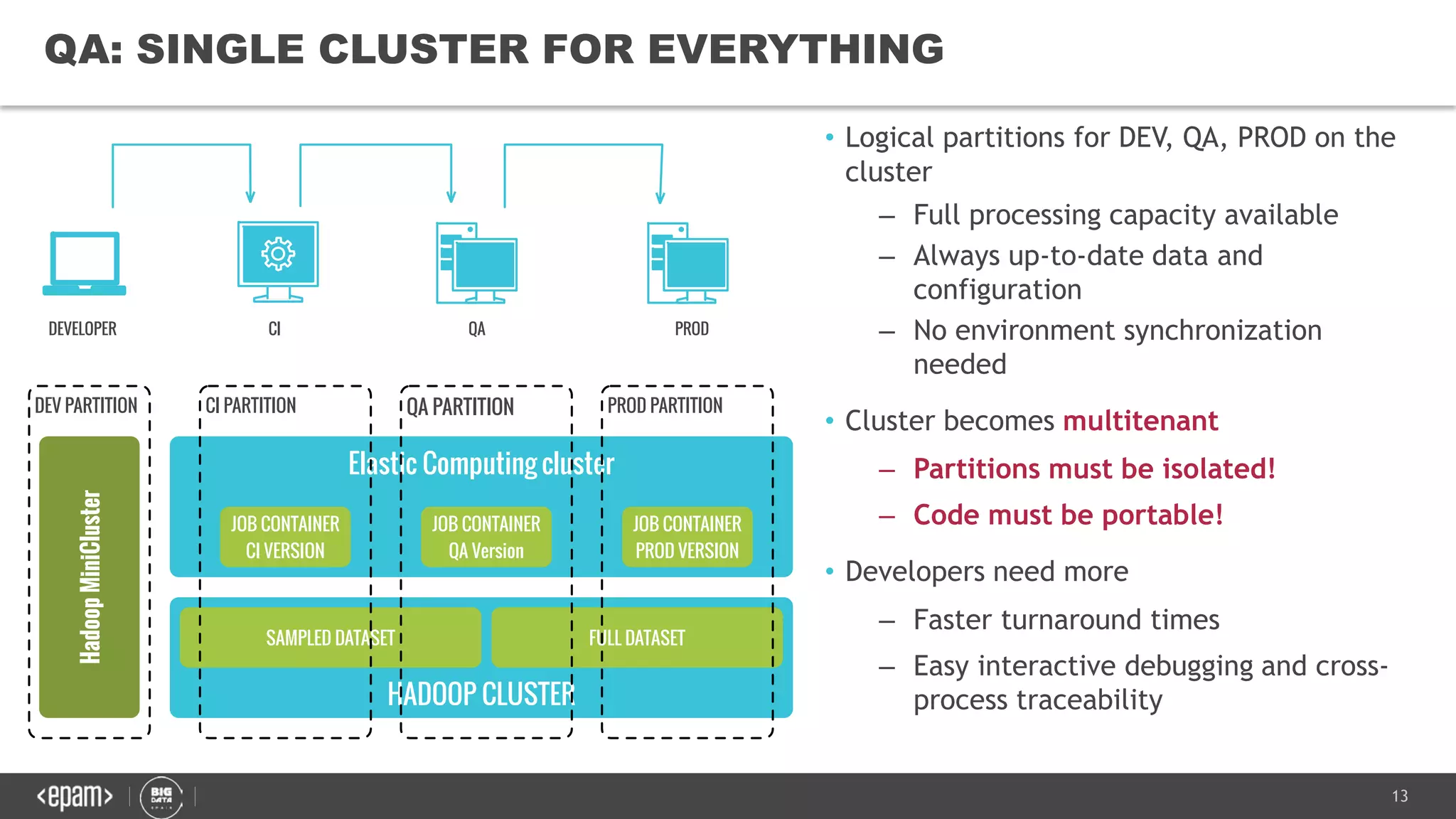
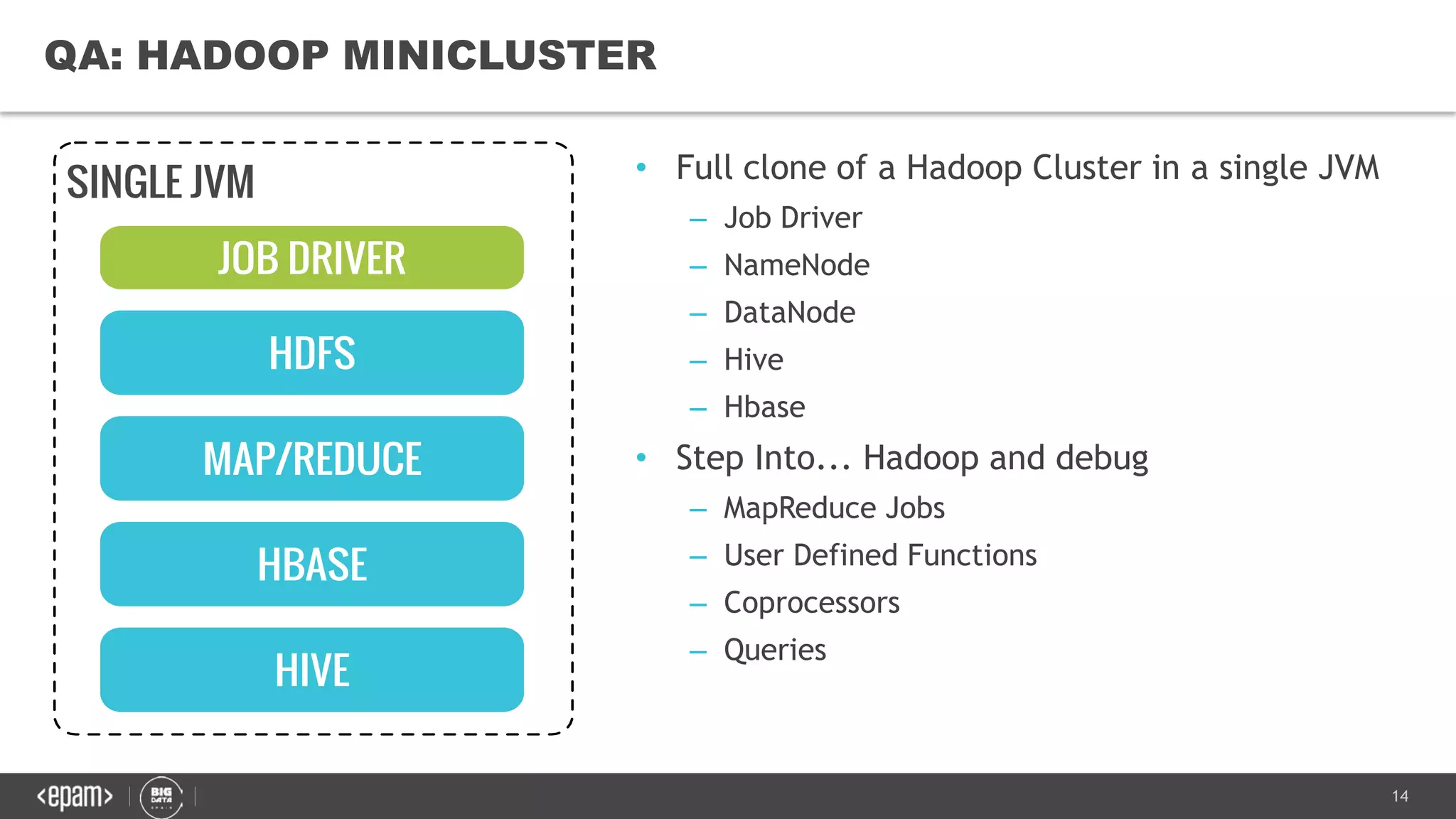



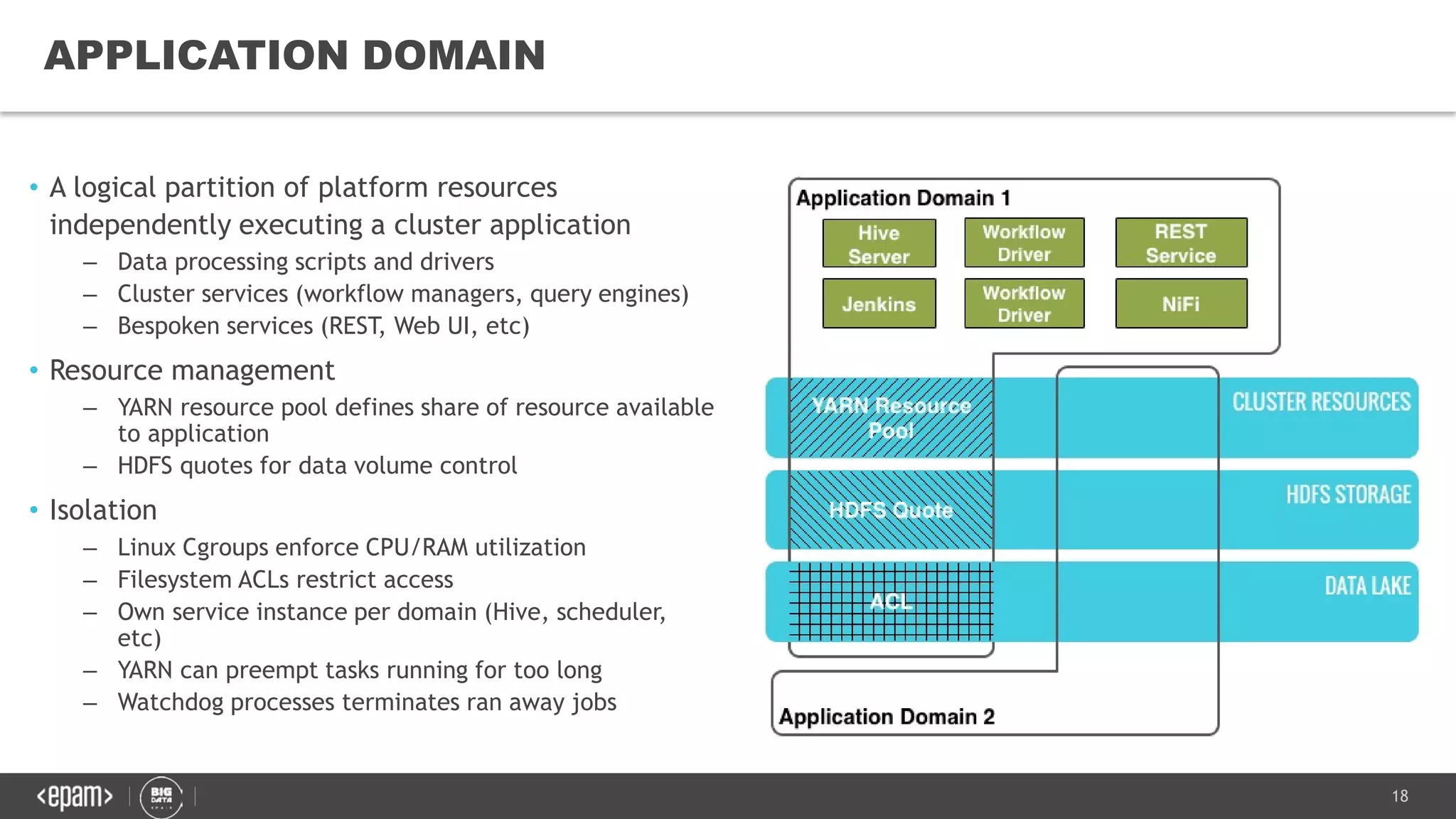




The document discusses the challenges and solutions for managing petabyte-scale data systems, emphasizing multitenancy, continuous integration, and isolated workloads. It highlights the need for a unified platform approach for efficient big data processing while maintaining the integrity and synchronization of configurations across environments. Key takeaways include the importance of augmenting Hadoop with flexible computational capacity and creating isolated domains for tenants.






















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)










