Download as PDF, PPTX



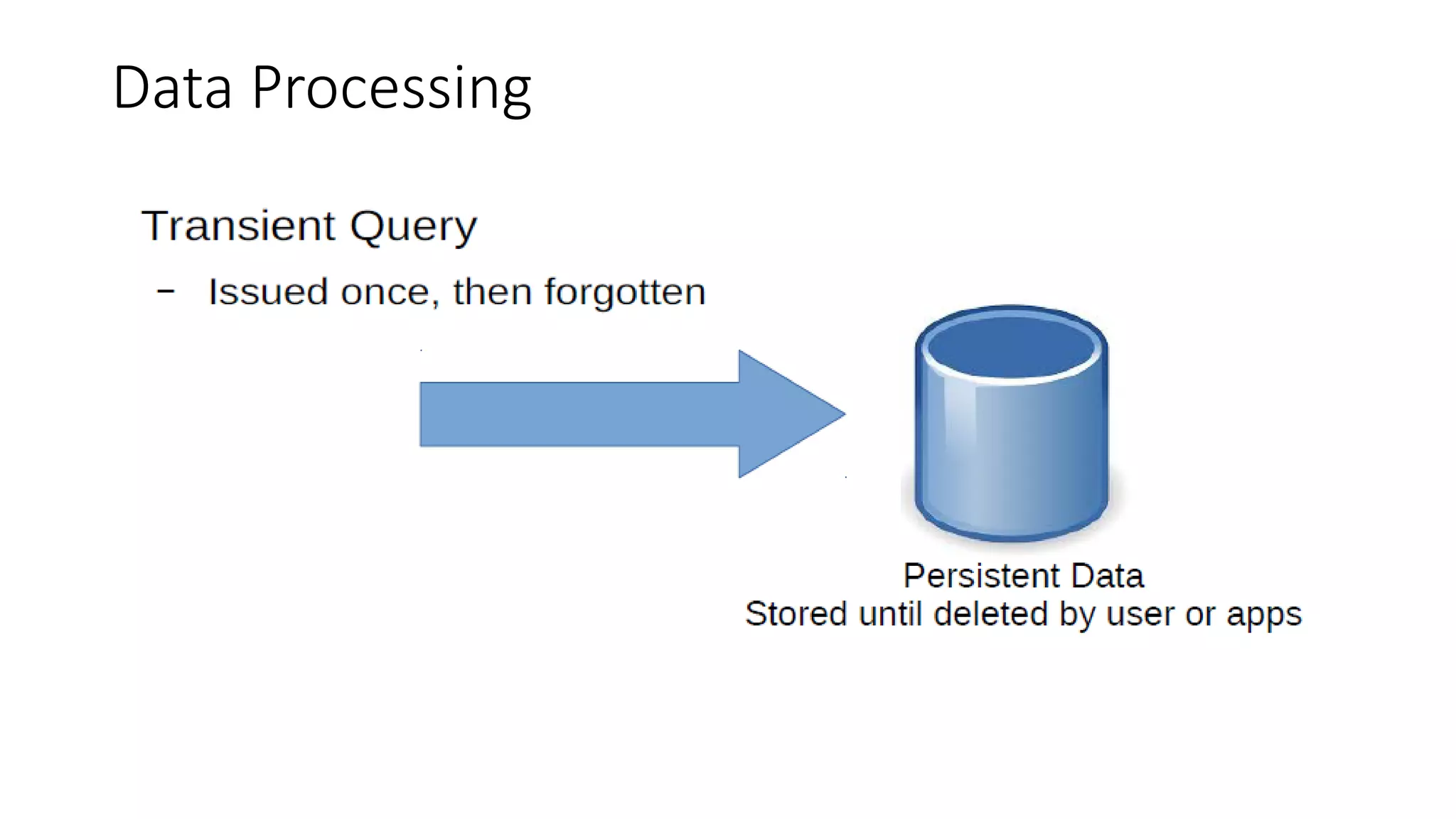
![What is streaming data?
•
Streaming data is an analytic computing platform that is focused on
speed.
•
By streaming, data can be continuously analyzed and transformed in
memory before it is stored on a disk.
•
It is a real time processing technique.
● All definitions are taken from reference [1]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-4-2048.jpg)
![Why Streaming Data?
•
Businesses are dealing with a lot of data that needs to be
processed and analyzed in real time.
•
Therefore, the physical environment that supports this level of
responsiveness is critical.
•
Streaming data environments typically require a clustered
hardware solution, and sometimes a massively parallel processing
approach will be required to handle the analysis.
•
Defining properties or dimensions of big data are volume, variety,
and velocity. Streaming technology can cover these three.
● All definitions are taken from reference [1]
BIG DATA](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-5-2048.jpg)

![When to use streaming?
•
Some key principles define when using streams is most appropriate:
When it is necessary to determine a retail buying opportunity
at the point of engagement, either via social media or via
permission-based messaging
Collecting information about the movement around a secure
site
To be able to react to an event that needs an immediate
response, such as a service outage or a change in a patient’s
medical condition
Real-time calculation of costs that are dependent on variables
such as usage and available resources
● All definitions are taken from reference [1]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-9-2048.jpg)
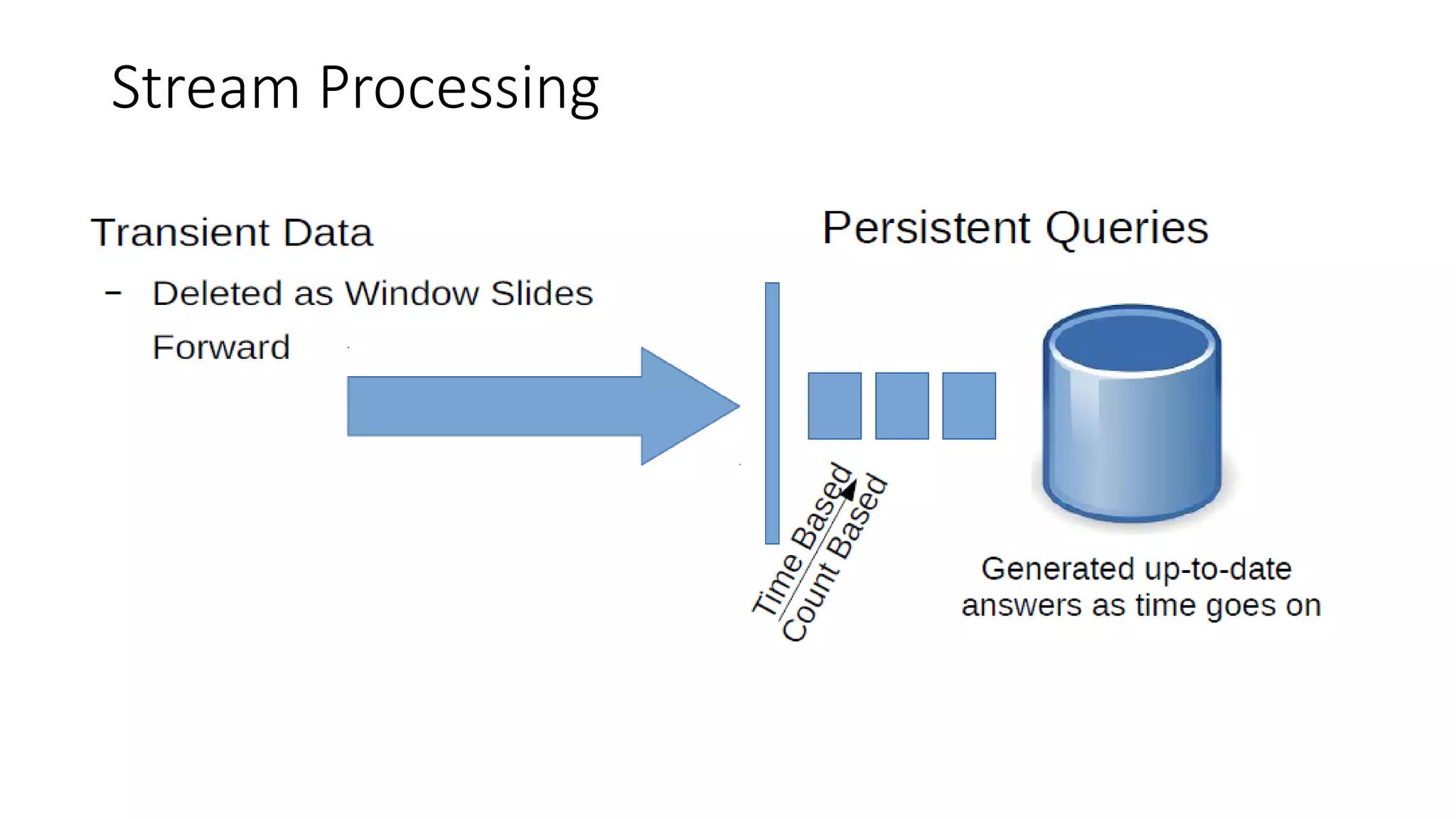
![Single-pass Analysis
•
One important factor about streaming data analysis is the fact
that it is a single-pass analysis.
•
In other words, the analyst cannot reanalyze the data after it is
streamed.
•
This is common in applications where you are looking for the
absence of data.
•
If several passes are required, the data will have to be put into
some sort of warehouse where additional analysis can be
performed.
● All definitions are taken from reference [1]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-10-2048.jpg)
![Streaming data vs. Hadoop
•
Streaming data is similar to the approach
when managing data at rest leveraging
Hadoop.
•
The primary difference is the issue of velocity.
•
In the Hadoop cluster, data is collected in
batch mode and then processed.
● All definitions are taken from reference [1]
Speed matters less
in Hadoop
than it does in
data streaming.](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-11-2048.jpg)

![Evolution of Data Management Solution
•
Relational Databases are not suited for Big Data
● All images are taken from reference [2]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-13-2048.jpg)
![Vendor Landscape
● All images are taken from reference [2]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-14-2048.jpg)
![An architecture of big data processing service
● All images are taken from reference [3]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-15-2048.jpg)
![Big Data Analytics Ecosystem
•
Recently, each architectural layer changed dramatically in terms of
the software stack
•
when services such as Yahoo!, Twitter, and LinkedIn released open
source solutions for dealing with big data.
•
The new architecture:
– Apache Kafka serves as a high-throughput distributed in-
memory messaging system in data ingestion layer,
– Apache Storm as a distributed and fault-tolerant real-time
computation in data analytic layer,
– Apache Cassandra as a NoSQL database in data storage layer.
● All definitions are taken from reference [3]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-16-2048.jpg)
![A simple instance of large-scale datastream-
processing service
● All images are taken from reference [3]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-17-2048.jpg)

![Capability Analysis of Recent Open Source Stream-Processing Systems
[13] L. Neumeyer et al., “S4: Distributed Stream Computing Platform,” Proc. IEEE Int’l Conf. on Data Mining Workshops, 2010,
pp. 170–177.
● Table is taken from reference [3]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-20-2048.jpg)
![[12] M. Zaharia et al., “Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters,”
Proc. 4th Usenix Conf. Hot Topics in Cloud Computing, 2012.](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-21-2048.jpg)
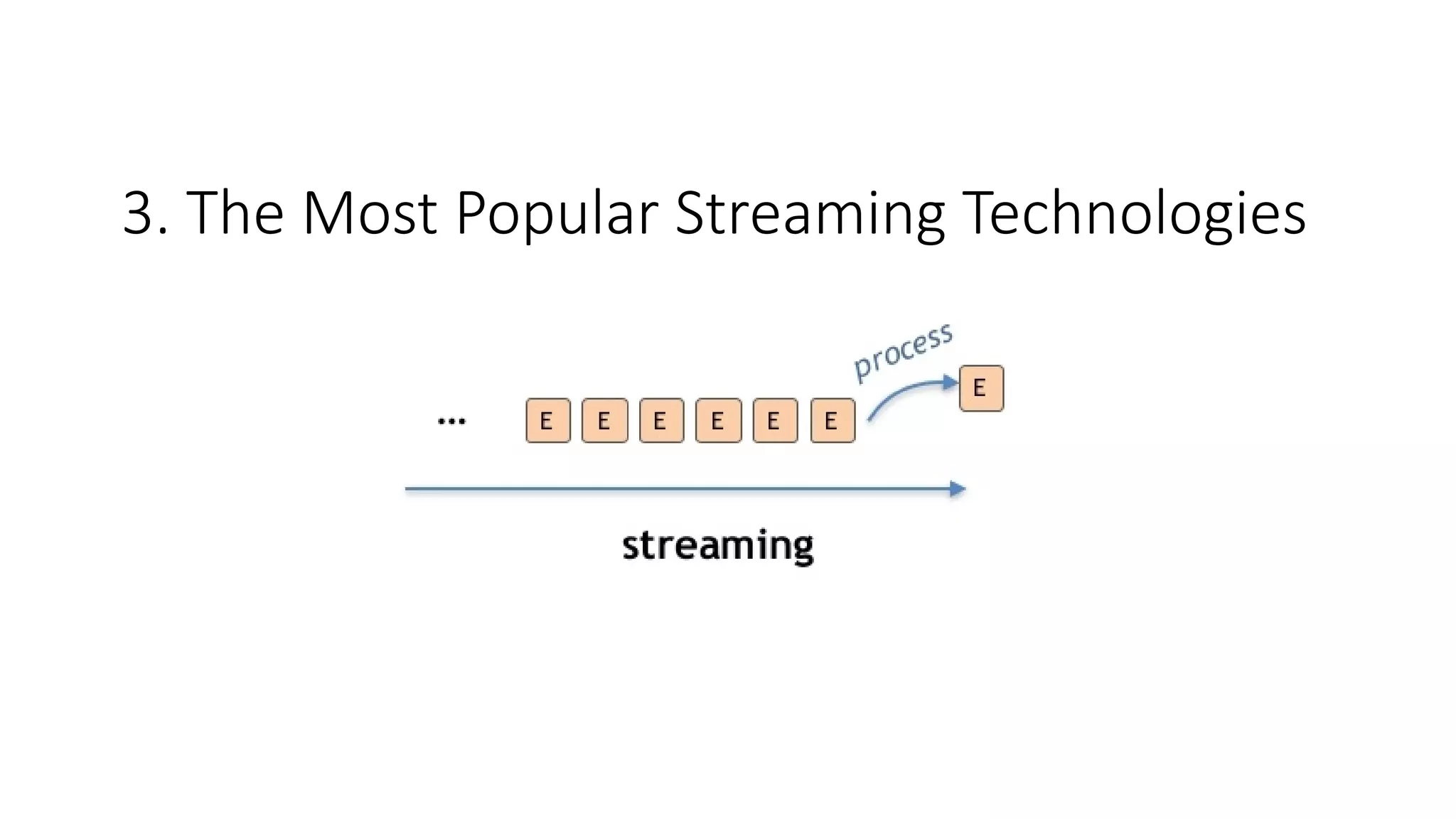
![Some of Streaming Computation Engines
•
Three open-source streaming engines:
– Apache Storm
– Apache Flink
– Apache Spark Streaming
● All definitions and images are taken from reference [4]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-22-2048.jpg)
![Apache Storm
● All definitions and images are taken from reference [4]
•
Apache Storm is a free and open source distributed realtime
computation system.
•
Apache Storm has the TopologyBuilder API to create a directed graph
(topology) through which streams of data flow.
•
“Spouts” are the entry point to the graph, and “bolts” perform the
processing.
•
Data flows through the system as individual tuples.
•
Graphs are not necessarily acyclic (although that is often the case)](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-23-2048.jpg)
![● All definitions are taken from reference [6]
● All images are taken from reference [4]
•
Storm is fast: a benchmark clocked it at over a million tuples
processed per second per node.
•
A Storm topology consumes streams of data and processes those
streams in arbitrarily complex ways, repartitioning the streams
between each stage of the computation however needed.](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-24-2048.jpg)
![Apache Flink
•
Apache Flink is an open-source stream processing framework for
distributed, high-performing, always-available, and accurate data
streaming applications.[7]
•
Apache Flink has the DataStream API to perform operations on
streams of data. (map, filter, reduce, join, etc.)
•
These operations are turned into a graph at job submission time by
Flink.
•
It works similarly to Storm’s model.
•
Also supports a Storm-compatible API.
● All definitions and images are taken from reference [4]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-25-2048.jpg)
![● All definitions and images are taken from reference [4]
•
Flink is designed to run on large-scale clusters with many thousands
of nodes, and in addition to a standalone cluster mode.
•
Flink’s core is a distributed streaming dataflow engine, meaning that
data is processed an event-at-a-time rather than as a series of
batches.](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-26-2048.jpg)
![Apache Spark Streaming
•
Apache Spark is a fast and general engine for large-scale data
processing.
•
Apache Spark has the DStream API to perform operations on streams
of data. (map, filter, reduce, join, etc.) Based on Spark’s RDD
(Resilient Distributed Dataset) abstraction.
•
Similar to Flink’s API. However streaming accomplished through
micro-batches.
•
Spark streaming job consists of one small batch after another.
● All definitions and images are taken from reference [4]](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-27-2048.jpg)
![● All definitions and images are taken from reference [4]
•
A Resilient Distributed Dataset (RDD), the basic abstraction in
Spark.
•
Using RDD(Resilient Distributed Dataset), Spark hides data
partitioning and can have parallel computational framework with
an API for four mainstream programming languages.](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-28-2048.jpg)
![Storm 0.10
Storm 0.11
Storm 0.11
NO ACK
Flink
Spark
•
Benchmark is taken from reference [4].
99th
PercentileLatency
Throughput rate (events/sec)
Comparison of Streaming Technologies](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-29-2048.jpg)
![Summary
•
Streaming data processing is beneficial in most scenarios where new,
dynamic data is generated on a continual basis. It applies to most of
the industry segments and big data use cases.[5]
•
Stream processing requires ingesting a sequence of data, and
incrementally updating metrics, reports, and summary statistics in
response to each arriving data record. It is better suited for real-time
monitoring and response functions.[5]
•
There are a few popular streaming data platforms such as –Apache
Storm, Apache Flink, Apache Spark Streaming.
•
Each of the streaming platforms have their advantages and
disadvantages. Active communities for big data processing projects
continue to innovate and benefit from each other’s advancements.](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-30-2048.jpg)

![References
•
[1] Judith Hurwitz, Alan Nugent, Fern Halper, Marcia Kaufman, "How to Use Data Streaming
For Big Data", Dummies.com, 2017.
•
[2] Sanjai Marimadaiah (CA Technologies), “Big Data, Big Opportunity: A Primer for
Understanding The Big Data Frontier”, CA World 2015.
•
[3] Rajiv Ranjan, “Streaming Big Data Processing in Datacenter Clouds”, IEEE Cloud
Computing, vol. 1, no. 1, pp. 73-83, 2014.
•
[4] Reza Farivar, Kyle Knusbaum, “Performance Comparison of Streaming Big Data
Platforms”, DataWorks Summit/Hadoop Summit, 2016.
•
[5] “What is Streaming Data?”, https://aws.amazon.com/streaming-data/
•
[6] “Why use Storm?”, http://storm.apache.org/
•
[7] “Introduction to Flink”, https://flink.apache.org/](https://image.slidesharecdn.com/sevalcaprazpresentation-200507115740/75/Data-Streaming-For-Big-Data-32-2048.jpg)

Streaming data involves the continuous analysis of data as it is generated in real-time. It allows for data to be processed and transformed in memory before being stored. Popular streaming technologies include Apache Storm, Apache Flink, and Apache Spark Streaming, which allow for processing streams of data across clusters. Each technology has its own approach such as micro-batching but all aim to enable real-time analysis of high-velocity data streams.
An overview of data streaming in big data, including its significance, management systems, and streaming technologies.
Explains streaming data, its real-time processing advantages, and the need for high responsiveness in data environments.
Describes the principles of when to use streaming, single-pass analysis, and compares streaming data with Hadoop.
Evolution of data management solutions, the vendor landscape, architectural changes, and big data processing services.
Details on popular streaming technologies like Apache Storm, Flink, Spark Streaming, and comparisons of their performances.
Details on popular streaming technologies like Apache Storm, Flink, Spark Streaming, and comparisons of their performances.
Details on popular streaming technologies like Apache Storm, Flink, Spark Streaming, and comparisons of their performances.
Digest of streaming data processing benefits and key platforms, with a Q&A session and references for further reading.































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)






















































