Download as PDF, PPTX
















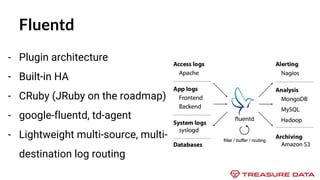














This document discusses data collection and ingestion tools. It begins with an overview of data collection versus ingestion, with collection happening at the source and ingestion receiving the data. Examples of data collection tools include rsyslog, Scribe, Flume, Logstash, Heka, and Fluentd. Examples of ingestion tools include RabbitMQ, Kafka, and Fluentd. The document concludes with a case study of asynchronous application logging and challenges to consider.










































































