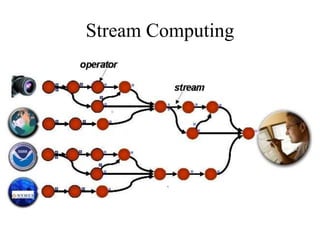
This document discusses stream computing and various real-time analytics platforms for processing streaming data. It describes key concepts of stream computing like analyzing data in motion before storing, scaling to process large data volumes, and making faster decisions. Popular open-source platforms are explained briefly, including their architecture and uses - Spark, Storm, Kafka, Flume, and Amazon Kinesis.