Downloaded 35 times







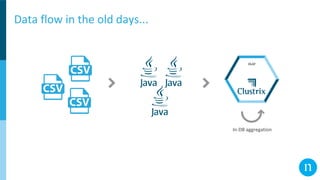

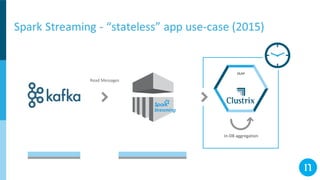
![That's one small step for [a] man… (2014)
“Apache Spark is the Taylor Swift of big data software" (Derrick Harris, Fortune.com, 2015)
In-DB aggregation
OLAP](https://image.slidesharecdn.com/thurs250pmroom127-128streamstreamstreamdifferentstreamingmethodswithsparkandkafkaitaiyaffee-190321210527/85/Stream-Stream-Stream-Different-Streaming-Methods-with-Spark-and-Kafka-10-320.jpg)



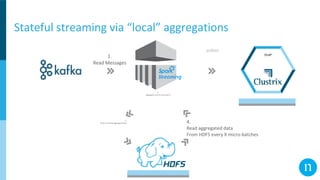


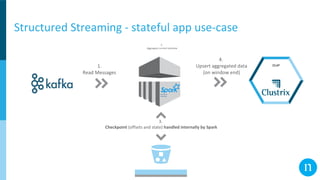


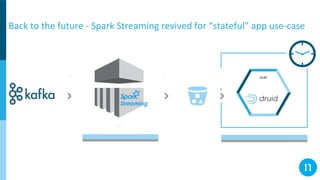
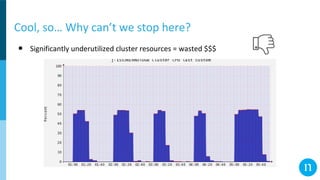
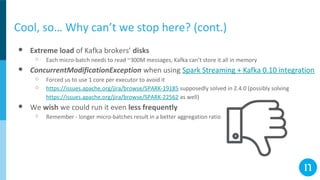

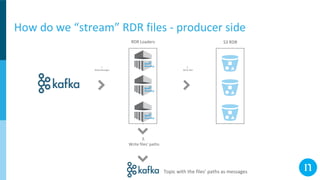
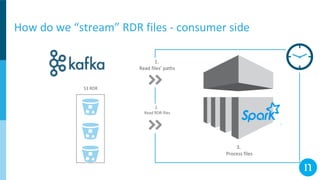
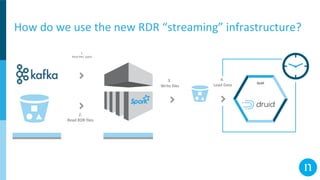








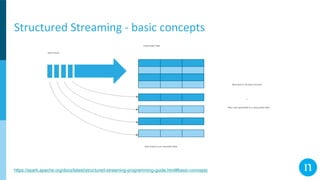
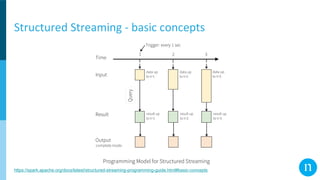
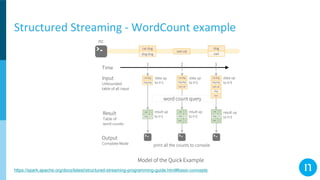





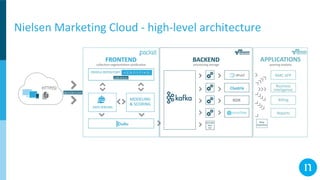
The document discusses various streaming methods using Spark and Kafka, focusing on the evolution from traditional data flows to modern stateful streaming solutions. It highlights the transition to structured streaming for better state management, improved performance, and cost efficiency, while addressing issues encountered during the implementation. Ultimately, the document emphasizes the benefits of using a data lake and optimized streaming architecture to reduce resource waste and enhance data processing capabilities.






















































































