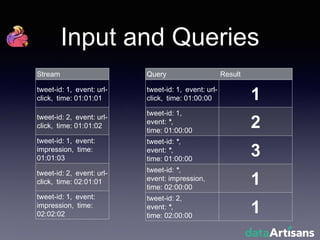
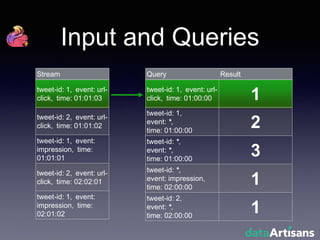
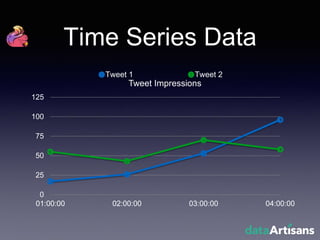
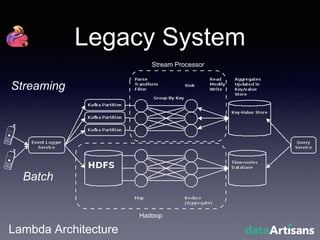
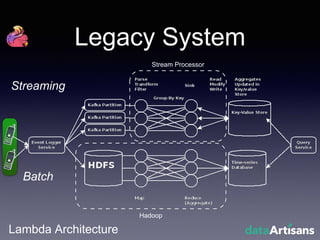
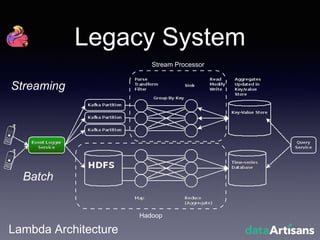
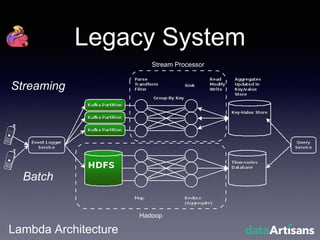
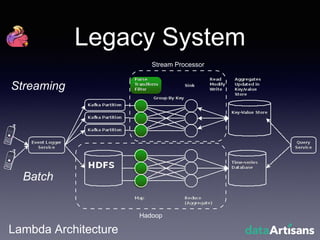
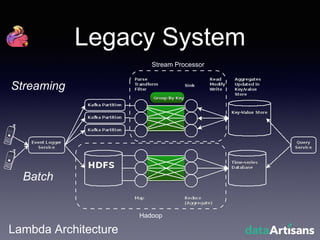
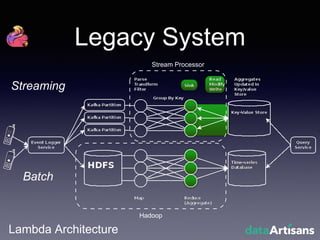
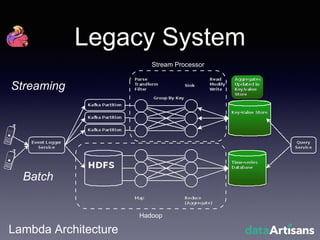
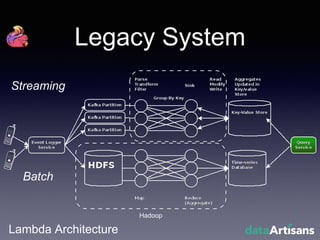
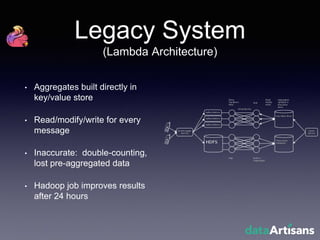
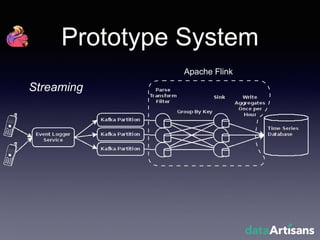
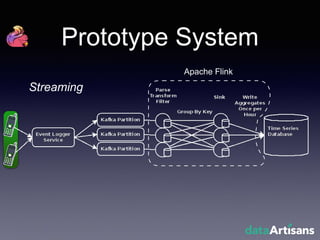
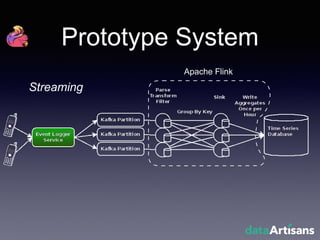
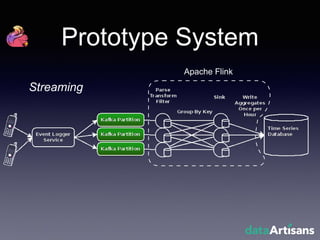
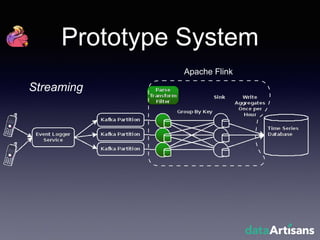
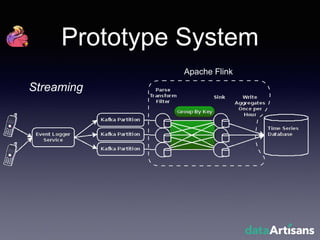
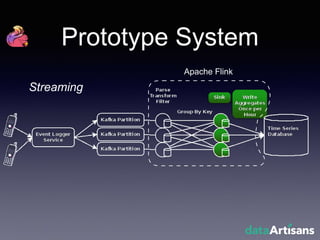
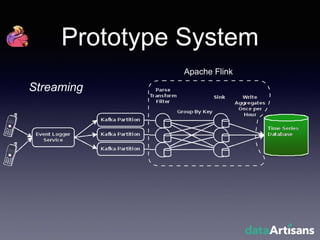
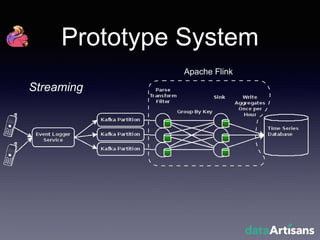
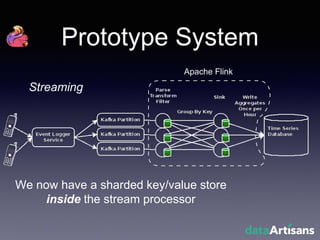
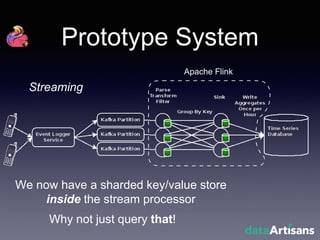
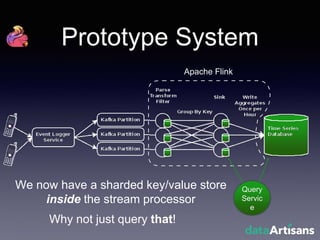
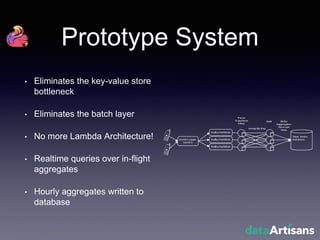
The document outlines the development of a prototype system using Apache Flink for stateful stream processing, aimed at eliminating the key-value store bottleneck and reducing hardware requirements by 200x while maintaining feature parity with existing systems. By leveraging Flink's fault-tolerant state management and built-in windowing, the system achieves real-time queries and exactly-once semantics for accurate data processing. Overall, the project demonstrates significant improvements in performance and resource efficiency for handling high-throughput event streams.

































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









