Download as PDF, PPTX







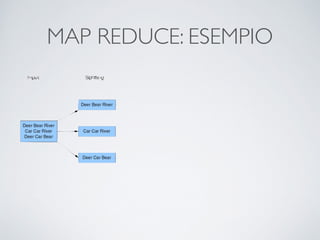
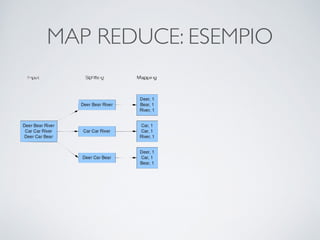
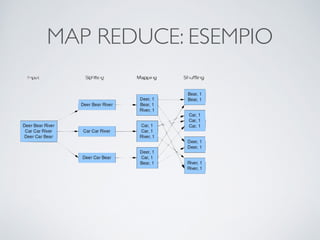
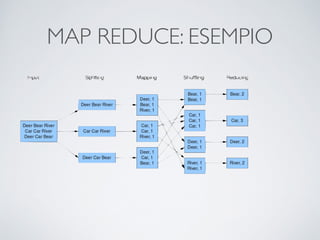
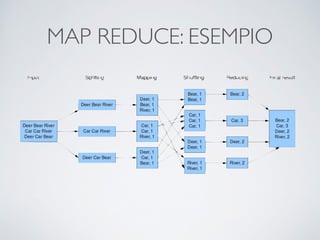



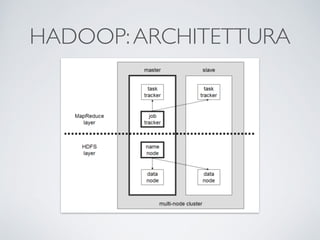





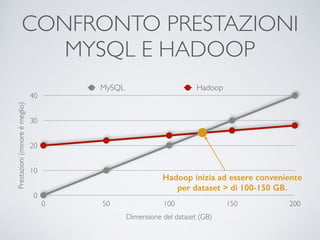




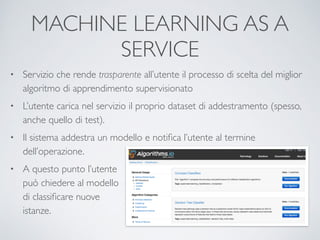


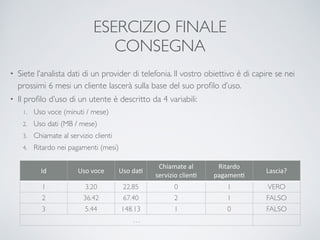


Il documento offre un'introduzione ai big data e alla scienza dei dati, descrivendo tecnologie chiave come MapReduce, Hadoop, Hive e Pig per l'elaborazione di grandi dataset. Viene esplorato anche il cloud computing come strumento per la memorizzazione e l'analisi dei dati, con servizi offerti da provider come AWS e Google Cloud. Infine, presenta un esercizio finale che richiede analisi esplorativa e machine learning per predire la probabilità di abbandono di un cliente in base a diverse variabili del suo utilizzo.















































