Downloaded 232 times







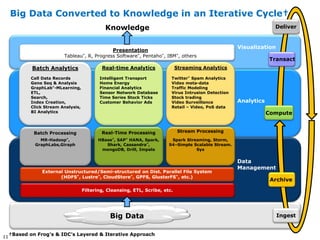







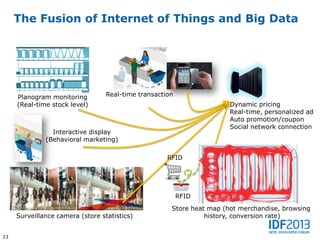

![Smart City Big Data Architecture Framework
Intel® Many Visualization & Interpretation
Integrated Core
Architecture
Vertical Scale
Based on Intel®
Horizontal &
Streaming [Un]Structured Batch
microarchitecture-EX Analytics Data Analytics
Based on Intel
Data Acquisition
microarchitecture-EP
Microserver
Local Analytics
Based on Intel
Complex Event Processing
microarchitecture-EN Analytics Processing
Horizontal
Preprocessing/
Storage
Cleansing/Filtering/
Intel® Core™
Scale
Aggregation
Data Acquisition Video Analytics
Sensors Cameras
Core System-
on-a-Chip
27](https://image.slidesharecdn.com/bj13bigs002101engf-130411064206-phpapp02/85/Big-Data-and-Implications-on-Platform-Architecture-27-320.jpg)

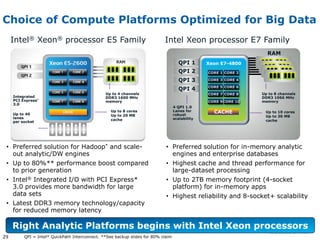
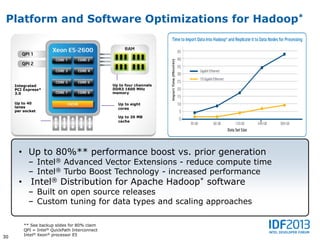
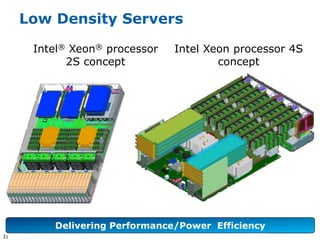

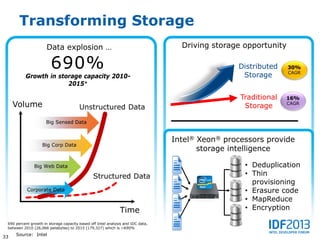
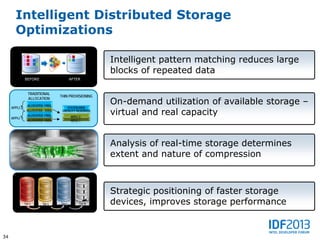








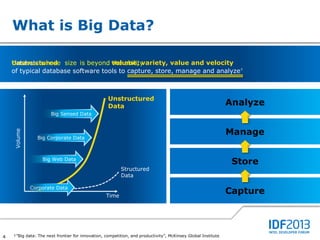
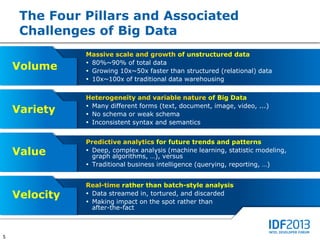
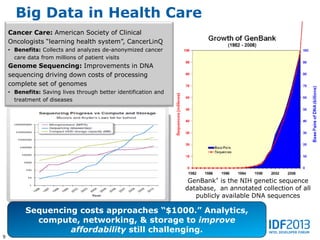
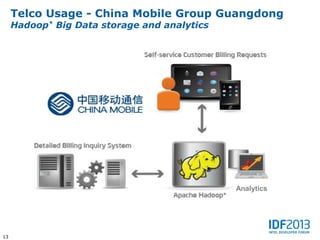
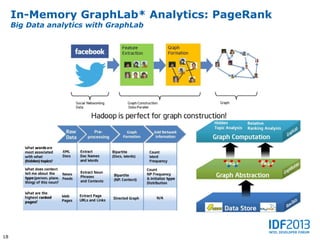
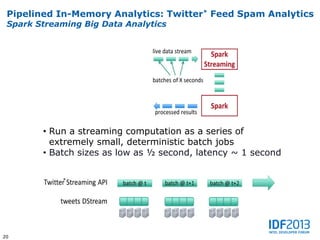
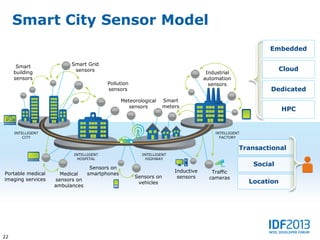
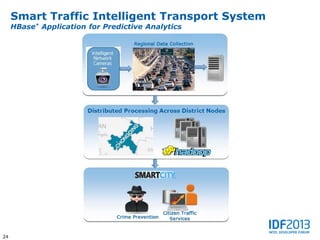
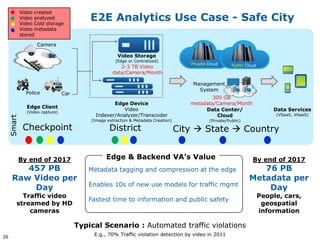
This document discusses big data and its implications for data center architecture. It provides examples of big data use cases in telecommunications, including analyzing calling patterns and subscriber usage. It also discusses big data analytics for applications like genome sequencing, traffic modeling, and spam filtering on social media feeds. The document outlines necessary characteristics for data platforms to support big data workloads, such as scalable compute, storage, networking and high memory capacity.











































































































