Download as PDF, PPTX





















































![Join Streams With Static Data
val ssc = new StreamingContext(conf, Milliseconds(500))
ssc.checkpoint("checkpoint")
val staticData: RDD[(Int,String)] =
ssc.sparkContext.textFile("whyAreWeParsingFiles.txt").flatMap(func)
val stream: DStream[(Int,String)] =
KafkaUtils.createStream(ssc, zkQuorum, group, Map(topic -> n))
.transform { events => events.join(staticData))
.saveToCassandra(keyspace,table)
ssc.start()
58](https://image.slidesharecdn.com/streaming-analytics-spark-kafka-cassandra-akka-151031073912-lva1-app6891/75/Streaming-Analytics-with-Spark-Kafka-Cassandra-and-Akka-58-2048.jpg)











![72
class KafkaStreamingActor(params: Map[String, String], ssc: StreamingContext)
extends AggregationActor(settings: Settings) {
import settings._
val kafkaStream = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
ssc, params, Map(KafkaTopicRaw -> 1), StorageLevel.DISK_ONLY_2)
.map(_._2.split(","))
.map(RawWeatherData(_))
kafkaStream.saveToCassandra(CassandraKeyspace, CassandraTableRaw)
/** RawWeatherData: wsid, year, month, day, oneHourPrecip */
kafkaStream.map(hour => (hour.wsid, hour.year, hour.month, hour.day, hour.oneHourPrecip))
.saveToCassandra(CassandraKeyspace, CassandraTableDailyPrecip)
/** Now the [[StreamingContext]] can be started. */
context.parent ! OutputStreamInitialized
def receive : Actor.Receive = {…}
}
Gets the partition key: Data Locality
Spark C* Connector feeds this to Spark
Cassandra Counter column in our schema,
no expensive `reduceByKey` needed. Simply
let C* do it: not expensive and fast.](https://image.slidesharecdn.com/streaming-analytics-spark-kafka-cassandra-akka-151031073912-lva1-app6891/75/Streaming-Analytics-with-Spark-Kafka-Cassandra-and-Akka-72-2048.jpg)

.select("precipitation")
.where("wsid = ? AND year = ?", wsid, year)
.collectAsync()
.map(AnnualPrecipitation(_, wsid, year)) pipeTo requester
/** Returns the 10 highest temps for any station in the `year`. */
def topK(wsid: String, year: Int, k: Int, requester: ActorRef): Unit = {
val toTopK = (aggregate: Seq[Double]) => TopKPrecipitation(wsid, year,
ssc.sparkContext.parallelize(aggregate).top(k).toSeq)
ssc.cassandraTable[Double](keyspace, dailytable)
.select("precipitation")
.where("wsid = ? AND year = ?", wsid, year)
.collectAsync().map(toTopK) pipeTo requester
}
}](https://image.slidesharecdn.com/streaming-analytics-spark-kafka-cassandra-akka-151031073912-lva1-app6891/75/Streaming-Analytics-with-Spark-Kafka-Cassandra-and-Akka-73-2048.jpg)

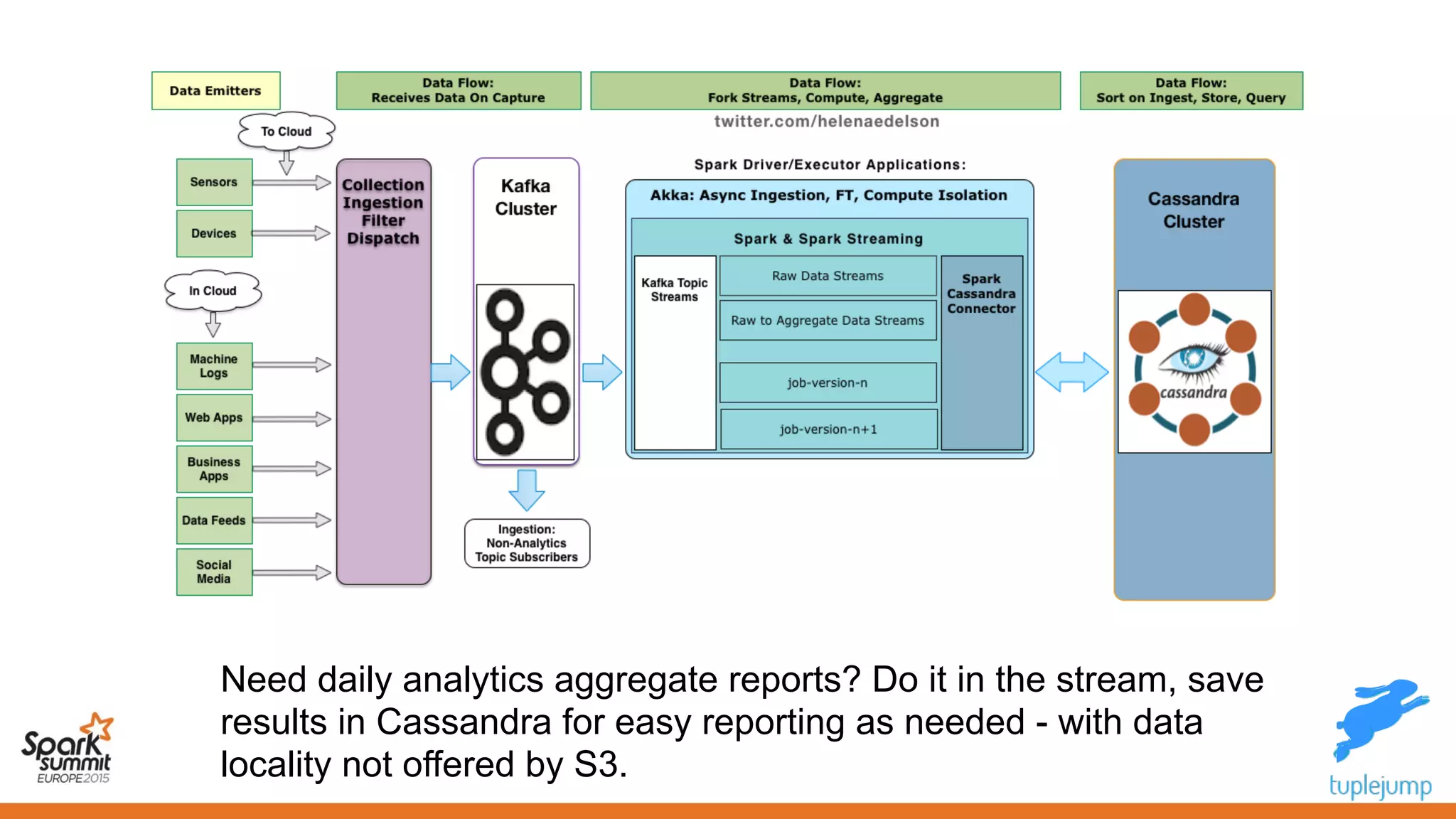



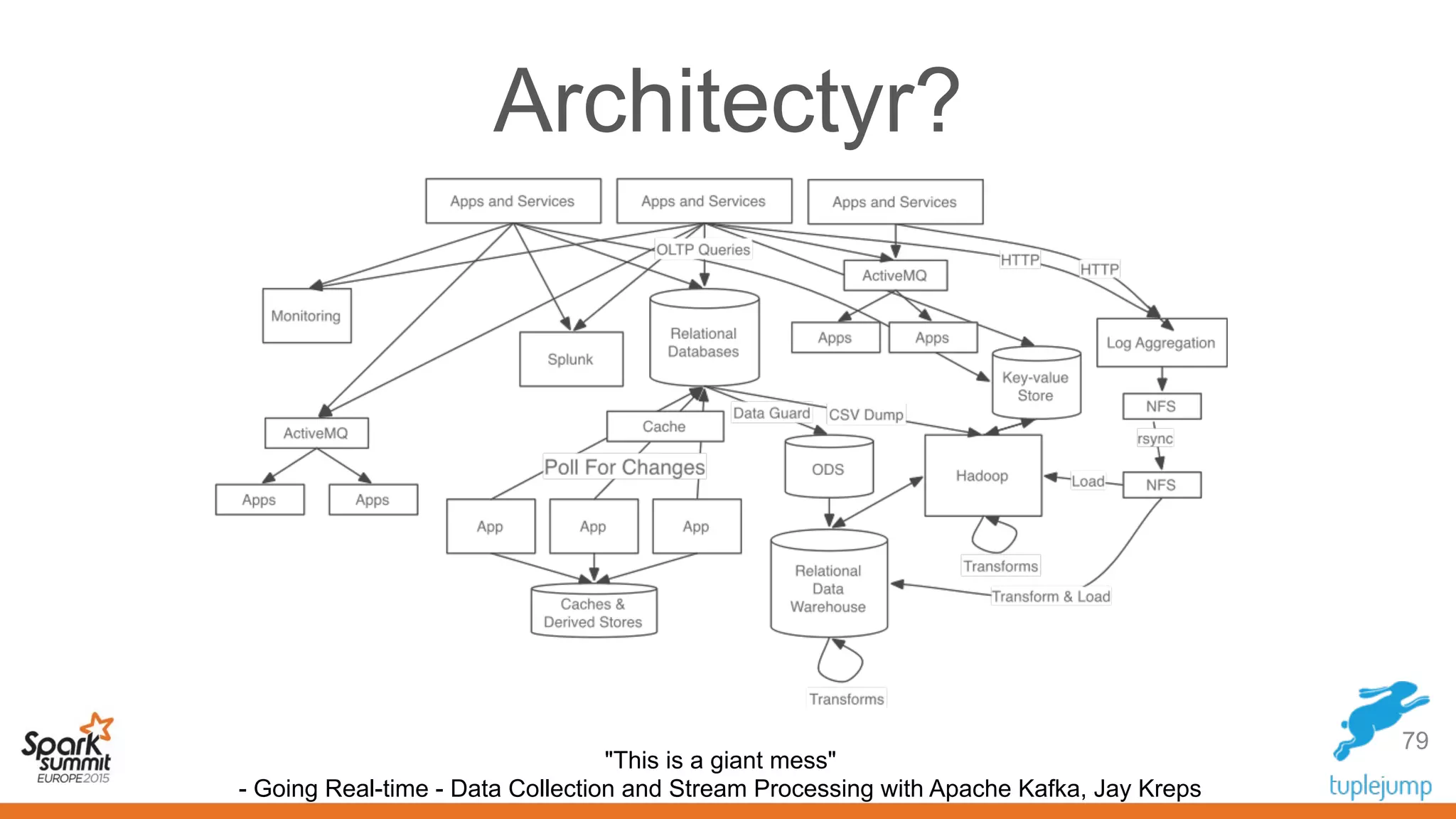
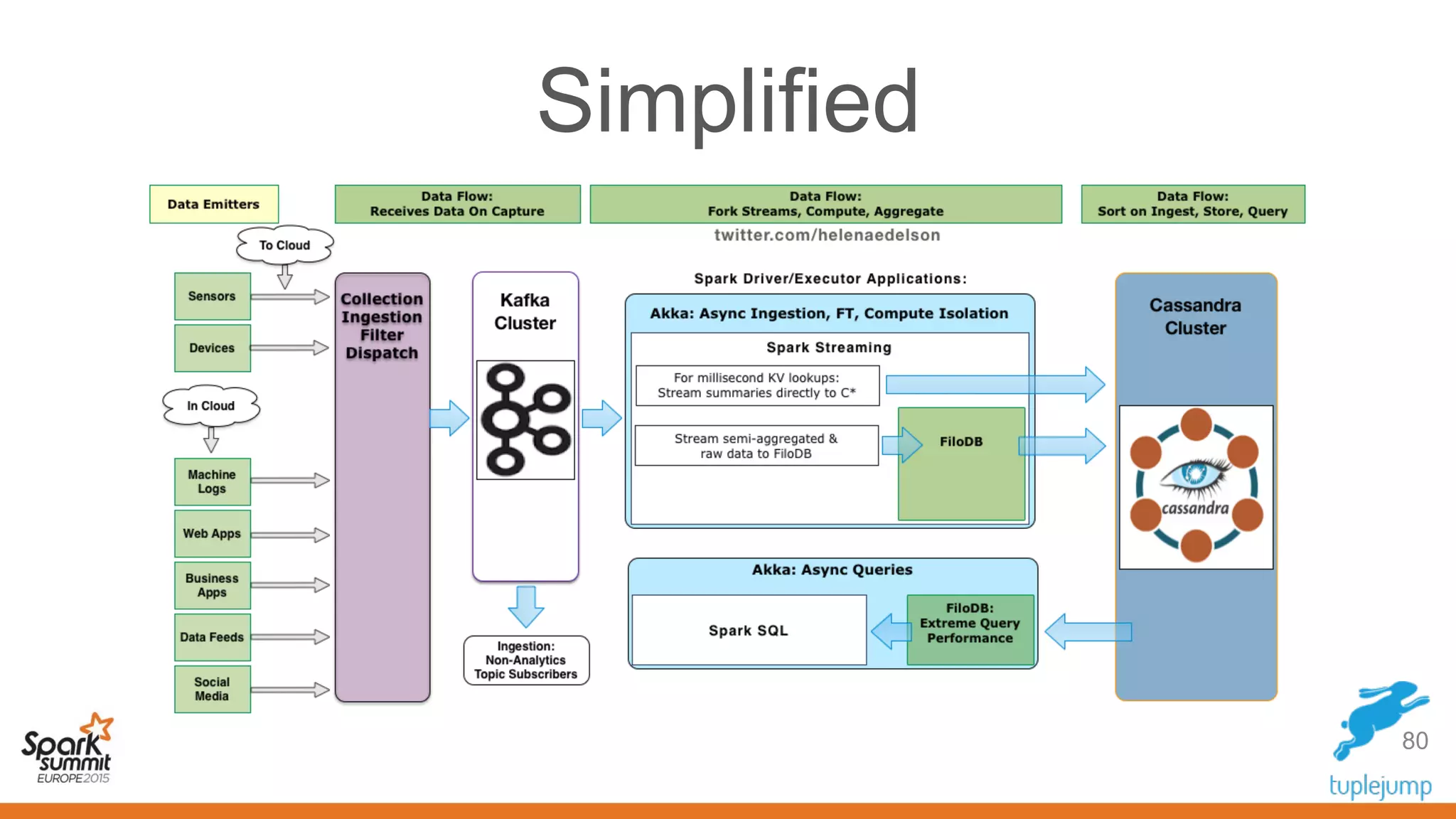
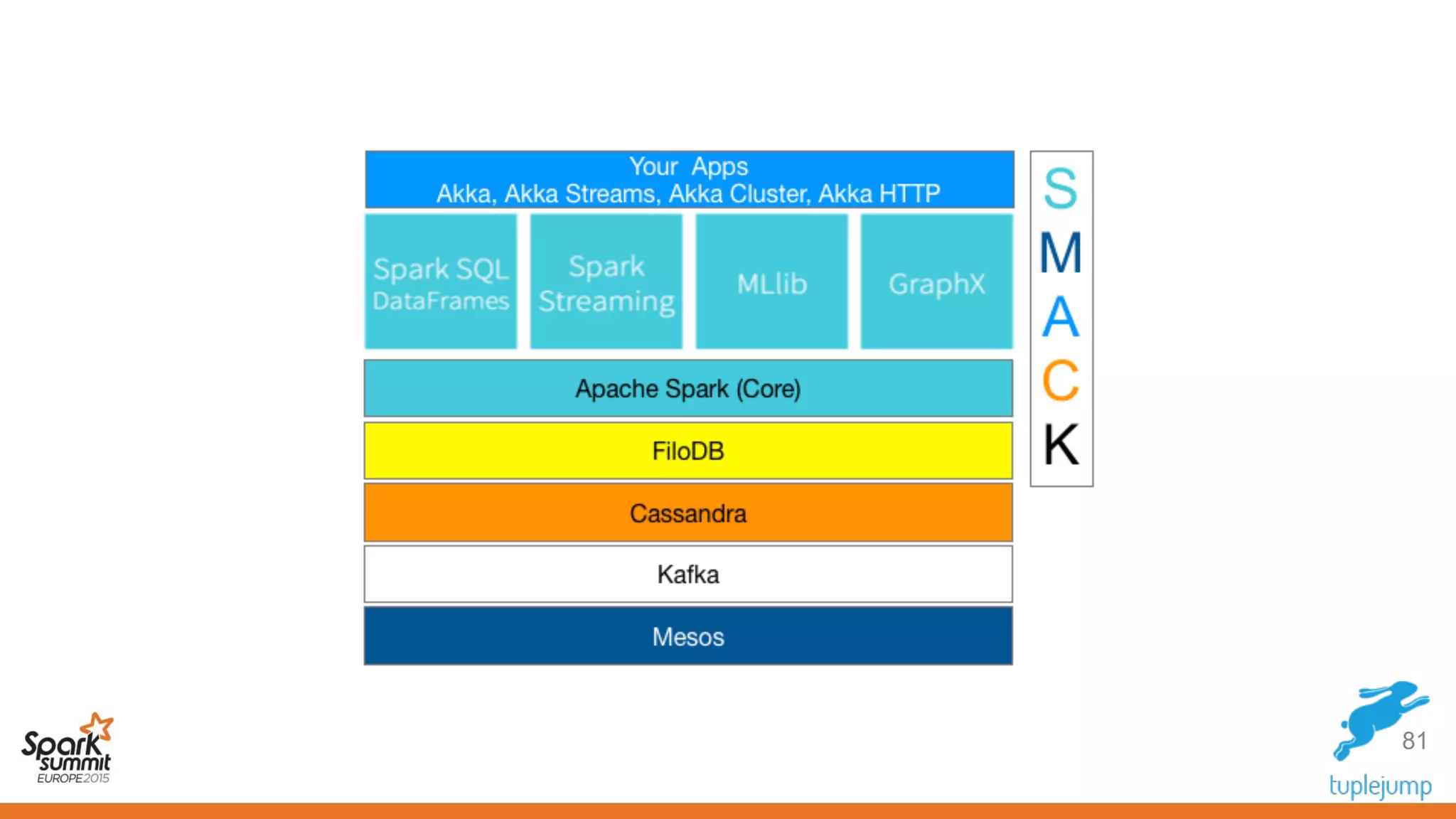




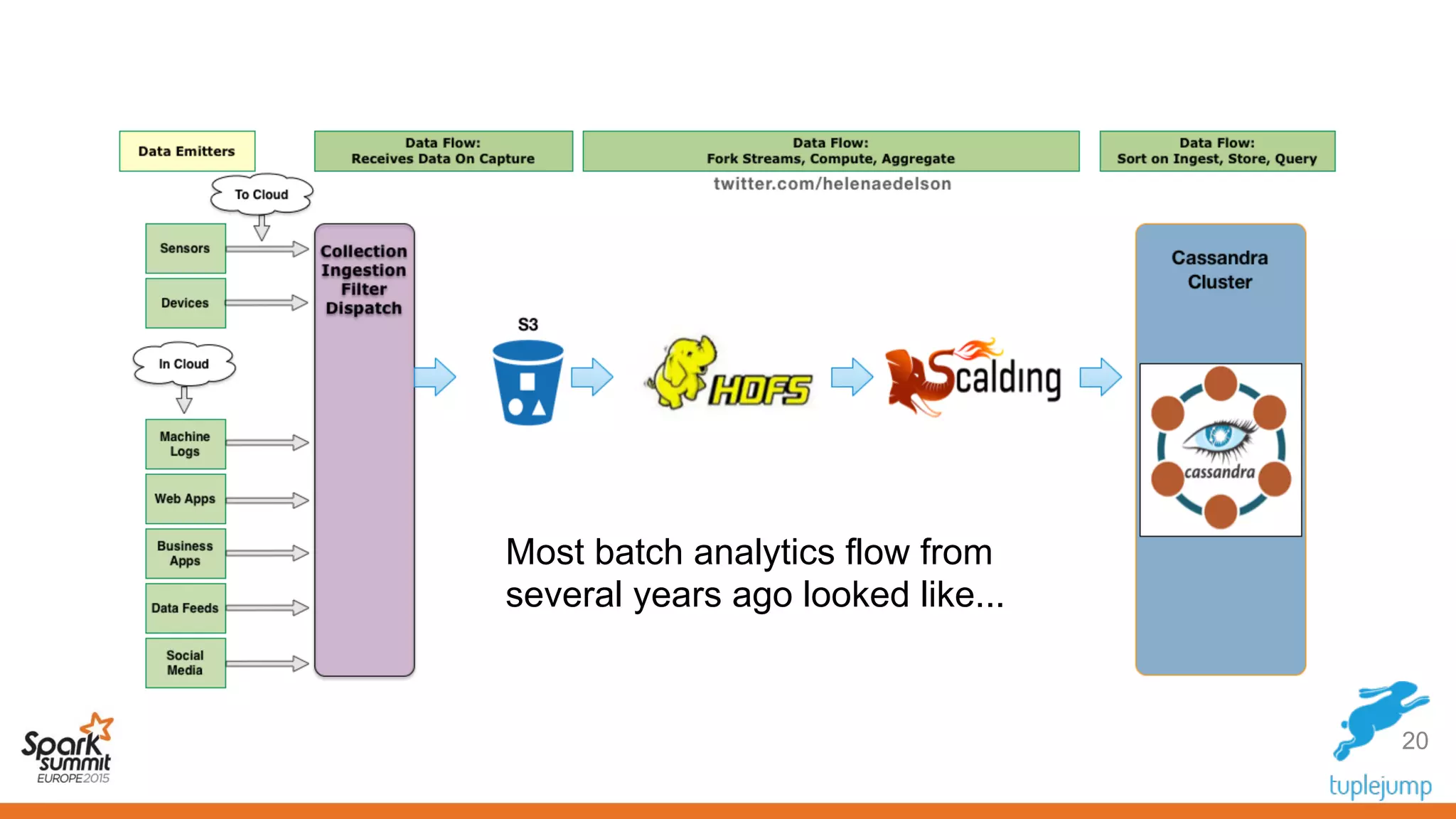
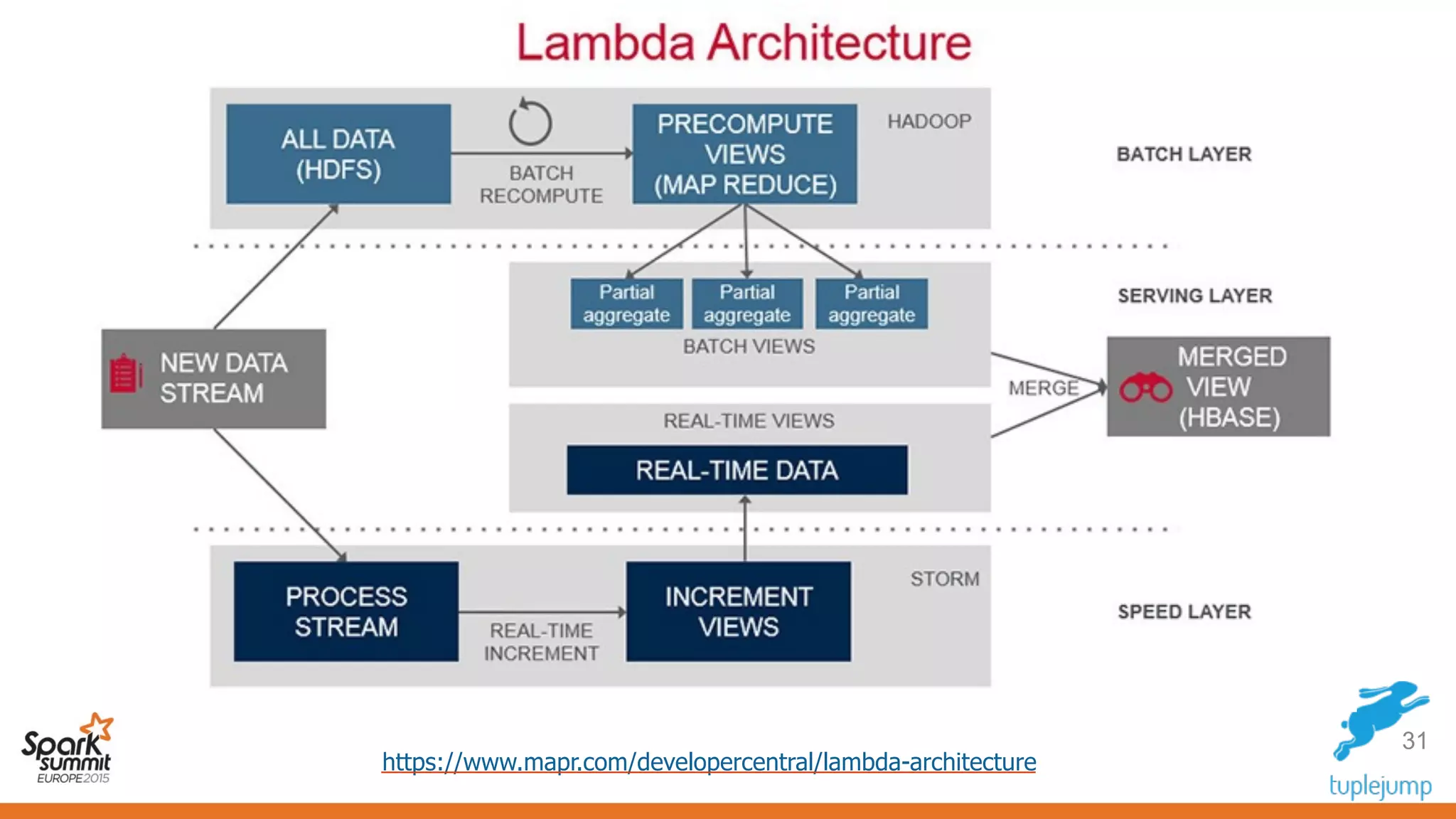
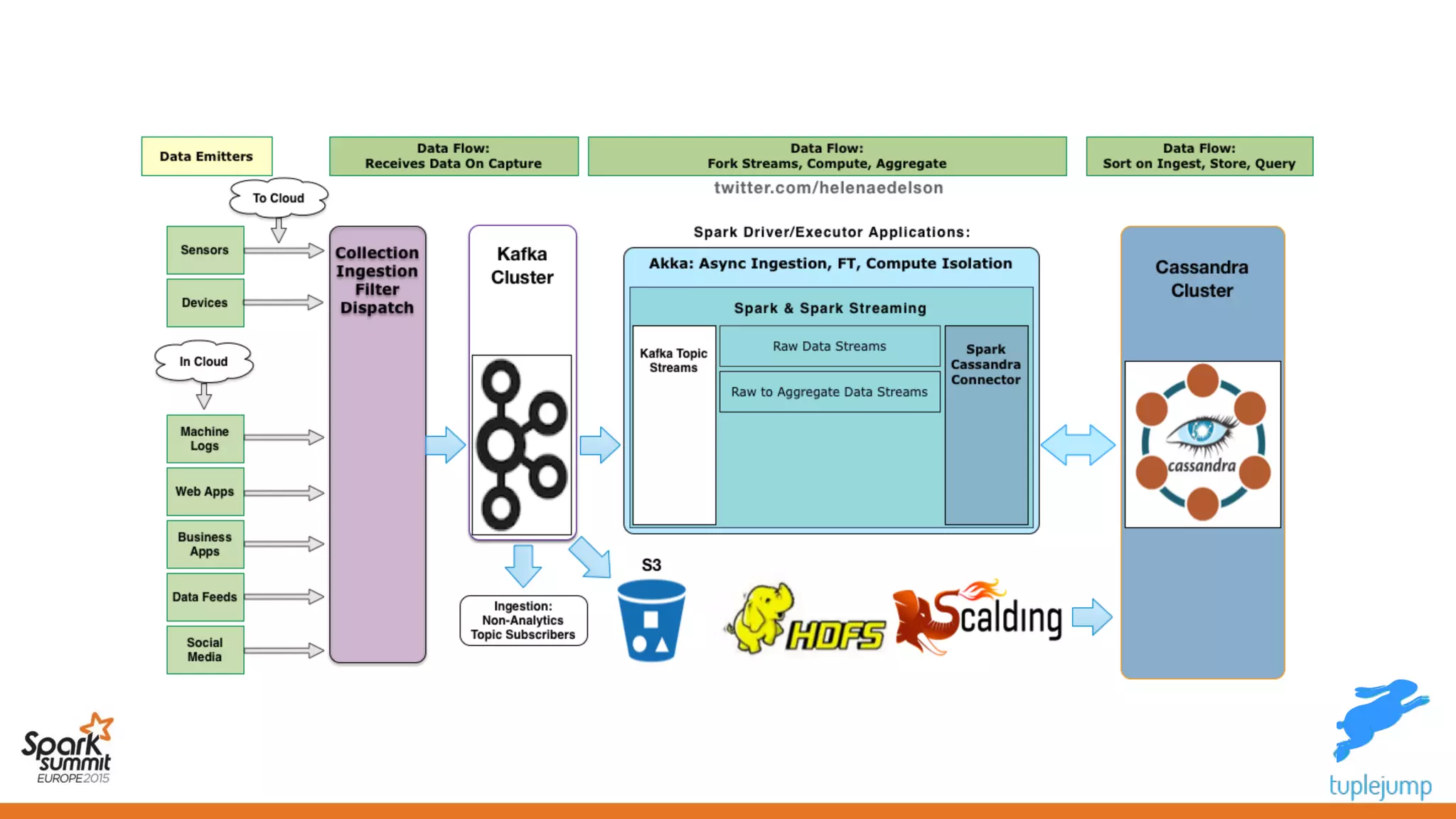
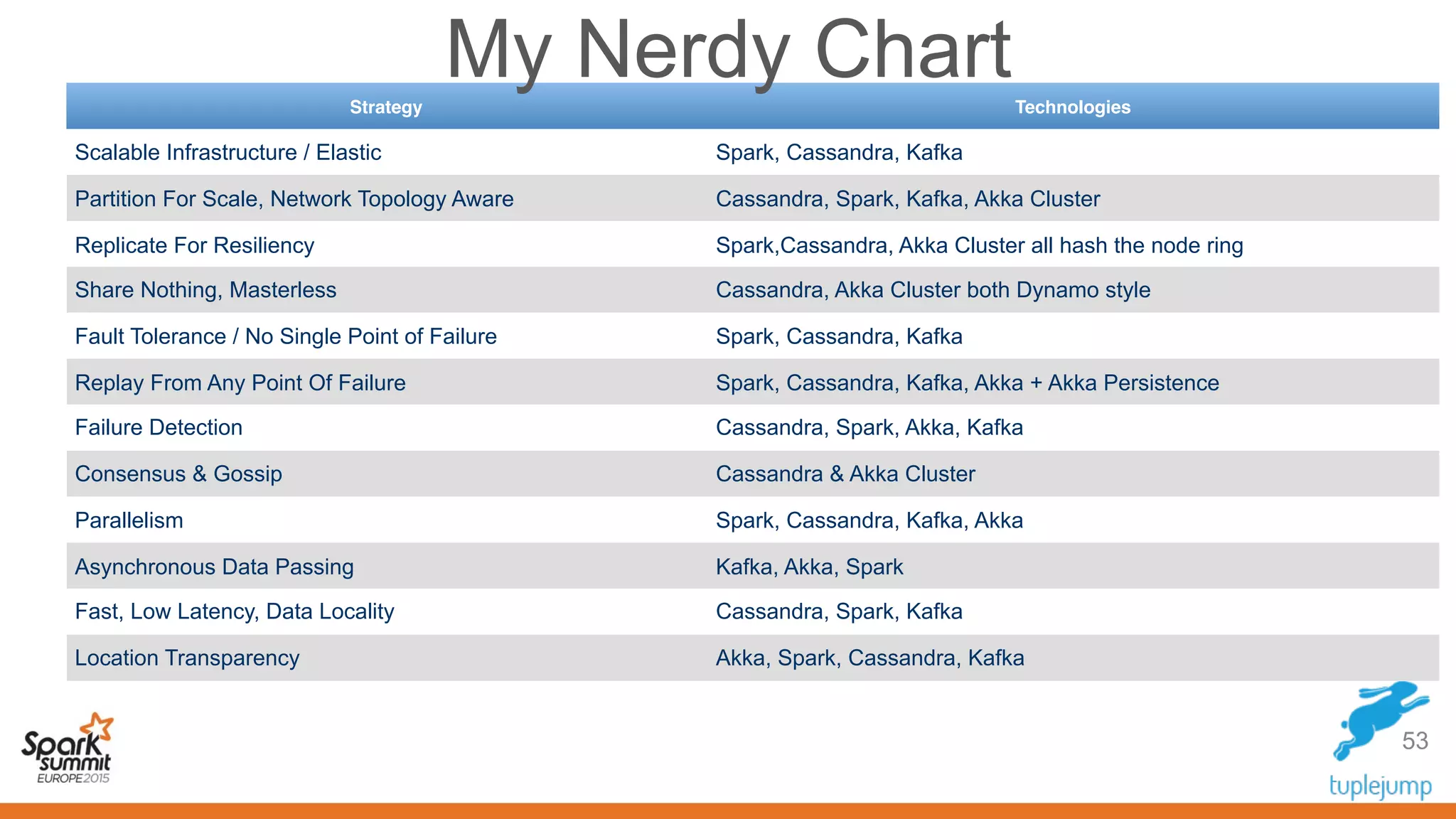
This document discusses a new approach to building scalable data processing systems using streaming analytics with Spark, Kafka, Cassandra, and Akka. It proposes moving away from architectures like Lambda and ETL that require duplicating data and logic. The new approach leverages Spark Streaming for a unified batch and stream processing runtime, Apache Kafka for scalable messaging, Apache Cassandra for distributed storage, and Akka for building fault tolerant distributed applications. This allows building real-time streaming applications that can join streaming and historical data with simplified architectures that remove the need for duplicating data extraction and loading.




































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

