Download as PDF, PPTX
















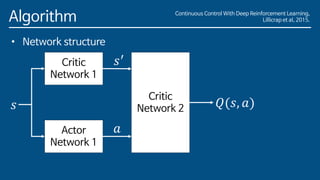
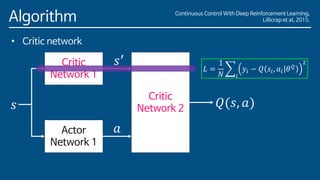
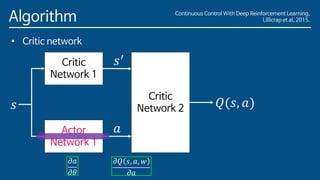

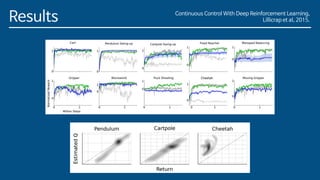





The paper introduces Deep Deterministic Policy Gradient (DDPG), a model-free reinforcement learning algorithm for problems with continuous action spaces. DDPG combines actor-critic methods with experience replay and target networks similar to DQN. It uses a replay buffer to minimize correlations between samples and target networks to provide stable learning targets. The algorithm was able to solve challenging control problems with high-dimensional observation and action spaces, demonstrating the ability of deep reinforcement learning to handle complex, continuous control tasks.






![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]マテリアルズインフォマティクスにおける深層学習の応用](https://cdn.slidesharecdn.com/ss_thumbnails/181207dlwakasugipanasonicver4-181207003725-thumbnail.jpg?width=640&height=640&fit=bounds)





































![[RLKorea] <하스스톤> 강화학습 환경 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-hearthstonesimulationforreinforcementlearningver1-190826145318-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC 2019] 하스스톤 강화학습 환경 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc19hearthstonedevelopmentforreinforcementlearningverfinal-190426141251-thumbnail.jpg?width=640&height=640&fit=bounds)

![[델리만주] 대학원 캐슬 - 석사에서 게임 프로그래머까지](https://cdn.slidesharecdn.com/ss_thumbnails/asdf-190219141801-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC 2018] 유체역학 엔진 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc18fluidenginedevelopmentverfinal-180427164620-thumbnail.jpg?width=640&height=640&fit=bounds)




















